






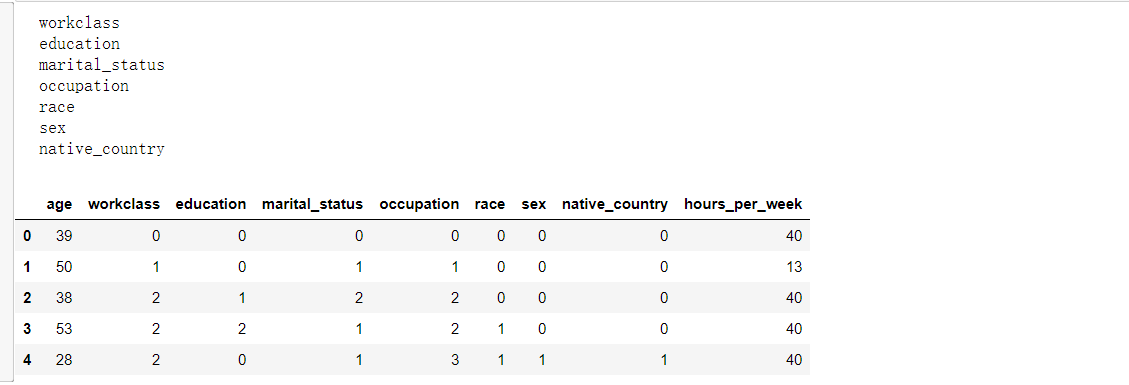
# 2:-1列的所有数据映射
for col in X.columns\[1:-1\]: # 遍历所有类名
u \= X\[col\].unique() # 类似上面的u = X\['occupation'\].unique() 得出每个分类下面的种类名称
# print(col)
def convert(x): # 将上面得出的u 进行索引映射
# print(x)
return np.argwhere(u == x)\[0,0\] # 将上面得出的u 进行索引映射
X\[col\] \= X\[col\].map(convert) # 将上面得出的u 进行索引映射
X.head()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
# 切分训练集跟测试集
from sklearn.model\_selection import train\_test\_split
X\_train,X\_test,y\_train,y\_test \= train\_test\_split(X,y,test\_size = 0.2) # 切分
print(X\_train.shape,X\_test.shape,y\_train.shape,y\_test.shape)
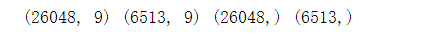- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
# 预测测试
knn = KNeighborsClassifier(n\_neighbors=8)
knn.fit(X\_train,y\_train) # 计算公式
y\_ \= knn.predict(X\_test) # 预测值
from sklearn.metrics import accuracy\_score # 计算分类预测的准确率
# 求出预测准确率
accuracy = accuracy\_score(y\_test, y\_)
print("预测准确率: ", accuracy)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
总结:难度在于数据的预处理















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









