









原作:https://arxiv.org/abs/1903.08527
研究机构:微软研究院
写在前面
想象一下,通过二维的人脸图片,生成高度还原的三维人脸模型。真是异想天开,可是人工智能要做的不就是实现那些异想天开的事情吗?再想象一下,这种功能能够运用的场景:
- 首先由于我从事的是游戏行业,因此很直接的就是能够生成玩家自定义的三维游戏角色。可以是玩家自己,也可以是玩家喜欢的人,只需要你上传一张高清大头照,我们就给你生成一个三维人脸模型,再结合一些预制的身体模型,一个玩家自定义的角色就生成了。试想一下在NBA 2K游戏中,你自己出现在球场上是什么感觉
- 自拍软件。例如美图,事实上美图在这一领域的确是走在世界前沿的。通过自拍,生成一个三维人脸模型,注意这个人脸模型可不是那种没有色彩的光秃秃的模型哦,它是有贴图的,下面的左图是原图,右图是将三维模型投影到原图上的效果。是不是很逼真!当然,我们承认目前在一些细节上还无法做到最优,比如在一些存在沟壑、棱角的地方,法令纹、眼角、嘴角等。回到美图,有了这个功能,未来美图的优化功能清单上会增加一个功能,表情切换!是的。因为是三维模型,它的表情是可以切换的。当然还有换脸等等功能。事实上,因为有了三维模型独有的深度信息,美图中的上妆功能也可以做的更加逼真,比如颜色的渐变,阴影的智能处理等等。

- 人脸识别。实际上高精度的人脸识别已经运用了这项技术。人脸识别中一项重要的工作叫做“活体检测”。也就是识别眼前这个人不是一张死的照片。三维重建人脸后的深度信息正是活体检测所依赖的重要信息。
- 人脸动画,实际上讲述自拍功能时已经提到,就是可以对三维人脸的表情进行模拟,进而做动画。想象一下,未来的电视剧演员只需要坐在办公室演绎表情,所有实景中的人体、人脸都靠智能生成。实际上这类运用也早就已经有了,例如指环王中的咕噜,无敌浩克中的浩克等等。只是,它们运用的技术还偏向于技术专家的人工合成,而不是基于人工智能的智能合成。当然,我们也承认眼下这项技术仍然存在一些缺陷,无法达到理想的还原状态。
- 请充分发挥你们的想象。
怎么从单张图片生成三维模型?
一个3D模型的数据结构是怎么样的?
实际上,我也是刚接触3维模型这个东西,如何用数据表示一个三维模型也是我比较好奇的地方。那这边我仅分享一下我通过跟代码后得出的一点心得。
首先有个矩阵,给它取个名字,叫points_shape,shape=(35709,3)。35709代表这个模型包括35709个点,3表示的是这些点的三维坐标。实际上,35709就是论文中使用的人脸模型具有的顶点数量。好了,有了这个矩阵,我们能够在脑海里想象在空间中有一个密密麻麻的点云,看上去像个人脸,可是,每个点之间都是离散的。
那么,轮到triangle矩阵出场了,它的shape=(70789,3)。首先triangle是三角形的意思,三角形是一个面。也就是说这个矩阵记录的是面的信息。70789表示这个模型包括70789个三角形面。每个面都由三个顶点组成,后面的3就表示这三个顶点的序号(在points_shape中的序号)。有了这个变量,人脸就不再是离散的点云了,而是有拓扑结构的一个人脸模型了。
然后就是颜色了,texture,shape=(35709,3),35709肯定代表的是点,3代表的RGB三通道。问题来了,为什么是用点的颜色,而不是用面的颜色?实际上,我到现在也还是困惑的!后面有了新的了解再补上吧。
到此,一个三维模型应该就表示清楚了。
什么是3DMM
实际上,大多数三维人脸重建都是基于一项叫做3D Morphable Model的技术实现的。按照字面意思理解,3DMM就是一个允许形变的三维模型。是的,我们可以理解成这是一个标准的人脸模型,这个世界上的所有人脸都可以由这张标准量经过一些变形而生成!(当然,实际上是不可能的,这么说只是为了不让大家感觉作者有什么外貌歧视)实际上,上面的话听起来像是废话,如果大家有玩过有“捏脸”功能的游戏的话,应该会比较有感触,有一些颇具艺术细胞的玩家能够捏出很棒的人脸模型,甚至是捏出他们的男神、女神。3DMM就有点这个意思,不过它牛的地方不是依靠人工捏脸,而是它给定了两组系数,分别是:形状系数,颜色系数。是的,有了形状和颜色,一个三维人脸也就生成了。这些系数有多少个呢?不同的3DMM模型定义的系数是有些许差别的,实际上,后面还延伸出一种表情系数。我们简单对这三组系数做一下说明:
- 形状系数:指定人脸的三维形状,有了这组系数,我们就可以生成一个面无表情的,光秃秃(没色彩)的三维模型。或者叫它原型比较合适。
- 颜色系数:指定颜色。有了这组系数,就可以对模型进行上色了,这时会得到一个逼真的有色彩的可是面无表情的三维模型。
- 表情系数:指定表情。有了这组系数,我们的模型可以微笑、难过、大笑、甚至噘嘴、眨眼。是的,模型活了。
如果非要给3DMM下个定义的话,我会这么讲:3DMM是一个静态的包含了指定的生成规则的用于生成三维人脸模型的模板
回到这篇牛皮的论文了,论文中选用BFM2009(3DMM大家庭中的一个版本,由Basel大学制作并公开,传送门)作为模板,用于生成三维人脸。
那么在BFM2009中,形状系数是一个长度为199的向量,你也可以理解成数组,总之就是199个数。然后!原谅我理解不够深,实际上可以用少于199个数,比如论文中只用了80个数。当然我的理解是,数越少,损失的信息也会越多。不过,它是有进行重要性排序的,也就是这80个数是这199个系数中最重要的数。可能会丢失一些沟壑、边边角角的信息,但是整体的轮廓仍然是准确的。颜色系数同理。(实际上,如果需要完全理解其中奥秘,需要完全理解3DMM的生成原理,可以参照文献)
以上介绍了3DMM,应该还是比较到位的(自以为)。那么后面要介绍的就是如何得到上述的这三种系数(形状系数,颜色系数,表情系数)!
得到系数
是的,现在三维人脸重建问题变成了如何根据单张图片,得到一系列3DMM所需要的系数!论文中采用的是神经网络的方法。输入单张长宽都为224的人脸图片,使用ResNet-50进行特征提取,最后是一个257个神经元组成的全连接层。也就是会输出257个数,其中80个是形状系数,80个颜色系数,64个表情系数,还有3个角度系数,3个尺寸系数,27个光照系数。这边角度系数、尺寸系数、光照系数和模型无关,它们的作用是,对模型进行一定的旋转、放大或缩小,投上光照,生成一个二维投影。想象一下,生成的模型要如何投影生成下面右图中的这个人脸?我们必须告诉它,原图中的人脸是什么角度、多大、光照条件如何。对吗?对!
好啦,一个神经网络要发挥指定的作用,损失函数是关键!损失函数让神经网络按照我们的意愿来进行学习!实际上,损失函数这部分也是我重现这篇论文时遇到的最大的问题。下面章节详细介绍损失函数!

损失函数
注意本文采用的是弱监督学习方式!!牛就牛在这里。三维人脸数据集非常有限!本文不需要任何标注训练集!!!唯一需要的训练集就是尽量多的仅包含一张人脸的照片!不需要标注!!当然有标注68个关键点的话更好,哈哈哈!(后面就知道为什么了)
1. 皮肤颜色的损失
通过神经网络回归得到的系数,已经足够我们生成一个模型,并且生成三维人脸的二维投影!有了这个投影!我们就可以用投影得到的图和原图进行一个颜色比对!这个比对过程就可以得到重构过程的损失!
公式:
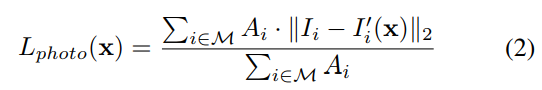
其中,i代表的是像素系数,M代表投影的人脸区域。||·||代表l2正则,A代表的该像素是皮肤的置信度,I代表原图中某个像素的颜色,I撇代表投影图上某像素的颜色!
仔细理解,就是对比投影生成的图的颜色和原图皮肤的颜色的差别!A这个置信度是用一个简单的贝叶斯分类器分类得到的。详情看论文。效果见下图,红框部分就是分类器给出的结果:
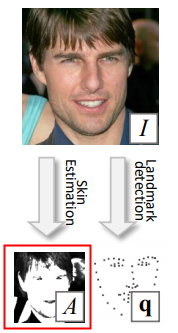
遗留问题:
- 代码层面如何得到投影后的图?(已完成)
- 这个贝叶斯分类器好像没有现成的,要自己训练一下。(难度3,没用过贝叶斯分类器。在github上找了一个分类器,试了一下效果还行,不过不确定和论文中作者使用的分类器具体有多大差别。然后,论文中提到的分类器已经发邮件给老外了,要等他回复,看看会不会给他们训练好的模型)
2. 关键点损失
首先我们用目前市面上最优秀的人脸对齐算法去检测原图的68个关键点。然后,我们拟合得到的三维模型投影在图像上也可以得到68个关键点。然后我们计算这些关键点之间的损失。
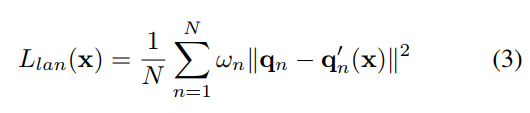
其中,N就是68,q代表原图的关键点坐标,q撇代表投影后的关键点坐标,这边用的是l2范数。
遗留问题:
- 去找这个市面上最优秀的人脸对齐算法(论文中有提到),并且最好有现成的模型。(难度2,应该有现成的模型。github上有基于pytorch的源码,目前安装pytorch出了点问题(墙好高))
3. 感知层损失
首先理解这个感知层,其实中文理解起来是有点费劲的。但是阅读了原文后大概知道了这个意思。图片上直观能看到的是浅层信息,或者是图像级的信息。但是图像经过类似卷积操作之后得到的特征图就是所谓的感知层信息,也可以理解成高层信息,这种信息通常是难理解的,缺乏语义的,但是一个优秀的特征提取器往往能够提取你想象不到的但是至关重要的特征。
作者用300万张包含5万个人的人脸图片训练了一个人脸识别网络,并且用其作为深层人脸特征提取器。
损失的定义为:
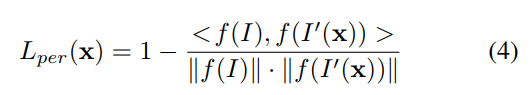
f(·)就代表这个特征提取结果。<·,·>代表向量的内积。下图展示了,加入这层损失后,图像的表面变得更逼真,一些棱角、凹陷也体现出来了。

遗留问题:
- 训练这个人脸识别网络!并且将其作为特征提取器。(难度3,参考论文中提到的文献。一个经典的人脸特征提取网络,FaceNet,有训练好的模型,正在下载中(墙好高!!))
4. 正则化损失
为了防止回归得到的模型系数变质(就是防止生成乱七八糟的人脸)。我们给这些系数加了一个正则。这样可以强制生成的人脸向平均脸靠拢(有利有弊吧)。
定义如下:
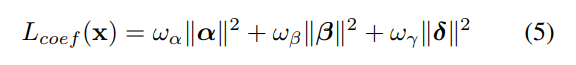
权重的设置是
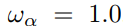
待解决:
- 确定一下公式中的距离是什么距离 ∥ α ∥ 2 \|\boldsymbol{\alpha}\|^{2} ∥α∥2(难度1,应该就是L2范数)
5. 颜色连续性的损失
这个论文中提的很少,还说会附上参考资料,可是一直没附上!!大致意思是为了让生成的颜色信息更具有连续性。
定义如下:
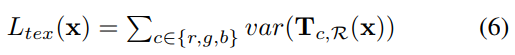
var()表示方差,R代表的是实现定义好的一个区域,这个区域包括脸颊、鼻子、前额(论文中没有具体给出这个区域)。这边也就是分别计算生成图像在r,g,b三个通道的指定区域的方差。
待解决:
- 找到这个区域的定义,实在没有的话,自己定义?(难度2,有印象看到这么一个东西,好像是在3DMM的论文里,实在没有,自己想办法定义吧)

















 6287
6287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









