







大家好,这里是七七,这两天在写关于神经网络相关的知识,面对的是有一定基础的读者哦。
一、RNN核心思想
RNN的核心思想就是曾经的输入造成的影响,会以致影响之后的输入,即隐含层的输出取决于历史数据的全部输入。
三个核心点
- 当前时刻隐含层的输出矢量不仅与当前网络的输入矢量有关,而且与上一个时刻隐含层的输出矢量有关
- 当前时刻网络的输出矢量只与当前时刻隐含层的输出矢量有关
- RNN在某一时刻的输出不仅与该时刻的网络输入有关,海域该时刻之前的所有时刻的网络输入有关
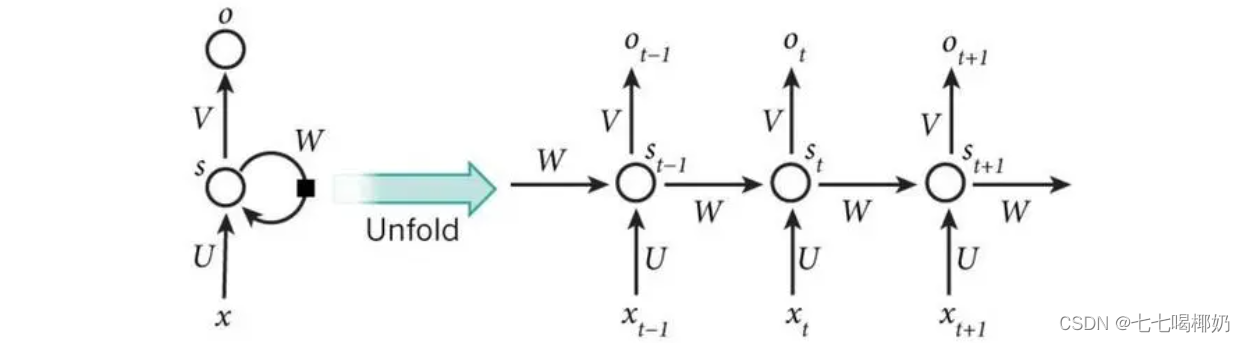
二、单向RNN
这张图展示的便是一个单项RNN,其中,x为输入向量,t代表第几次,U代表输入权矩阵,W代表历史权矩阵,V代表隐含层的输出权矩阵,s代表隐含层,o代表输出层。
本次s的值取决于本次的输入和上次的s的值,本次的o值只取决于本次的s的值。
中间的隐含层也可以有两层、三层以及更多,相应的计算公式也会发生改变,但原理都是一样的。
三、BPTT算法
BPTT算法其实就是BP算法增加了TT(Through Time),作用就是训练RNN模型的U、V、W这三个矩阵。与BP算法一样,这也是一种梯度下降算法。
具体过程是这样的,每输入一组数据后(如好几个矩阵),通过预期值与预测值之间的误差,来对U、V、W这三个矩阵进行修改,从而提高正确率。
BPTT的推导过程很复杂,七七这里直接省略推导过程(有好多好多过程┭┮﹏┭┮)
总之,我们只要知道,可以用这个算法,通过梯度下降,来训练模型就可以了。
四、填空问题
填空问题就是我给出一句话,把其中的某个词给扣掉,然后让计算机来填上我刚刚扣掉的这个空。对于要填最后一个空的句子来说,我们可以用单向RNN模型来完成,具体方法是这样的
- 首先一定是训练模型,要用好多句子来训练这个模型。其中,我们需要对这些句子中出现的每个词统计起来,形成词库。这样,每个词对应唯一一个编号。其中,还要有两个特殊的符号,来代表开始符和结束符。
- 然后呢,我们还要对每一个词进行矢量化。这里我们先引入一个概念:独热矢量,就是一个分量为1,而其他分量都为0的矢量。
- 这样一来,每个词都对应一个独热矢量,如[0 0 0 0 0 0......1 0 0......0]。这个独热矢量就可以作为输入来代表对应的词了。
- 词库中有多少个词,我们的输入和输出就有多少个神经元,至于隐含神经元,一般是根据经验来确定发的。
- 在训练的时候,我们需要将句子中的词一个一个输入,然后模型的输出应该是预测的下一个词语。如我们想输入“我爱你”,我们第一次输入的是“我”,此时如果模型输出为“爱”,那么就对了,否则就错了,需要记录错误,并在最后根据错误量进行权值调整。
- 训练是需要划分训练集和测试集的,如二八分。将一部分数据用于训练,通过这部分数据来调整权值;用另一部分数据作为测试,来检测模型的准确率。
- 对于模型的输出,我们可以用将所有输出神经元的激活函数采用softmax函数,这个函数的作用是让所有输出的值之和为1,也就形成了一个概率,然后取输出中最大的那个独热矢量作为输出的值。
上面我们讨论的问题是填最后一个词,如果说这个被扣掉的词是在句子中间,单向RNN就不行了,这是我们可以用双向RNN,就是在单向RNN的基础上将隐含层再复制一遍,然后将新增的隐含层向后传递影响改为向前传递影响就可以了,这里不做仔细讨论,了解即可。
五、梯度爆炸与梯度消失
这里的推导就不给大伙展示了,电脑上的公式实在不好写,直接给大伙介绍介绍吧。
一般,当MLP的层数较多时,其训练过程就可能发生梯度爆炸与消失现象,从而导致训练失败。
那我们要如何处理呢,下面来介绍应对的方法
对于梯度爆炸,我们可以设置一个梯度阈值,训练过程中梯度矩阵中某些元素的绝对值一旦超过阈值,则超过的部分可直接削去,这样就可以很好地抑制梯度爆炸。
对于梯度消失,可以使用LSTM模型,是一种新的RNN网络模型
六、LSTM
LSTM这个模型七七也是用过跟多次了,但此前一直不是很清晰,这次把它搞懂了,来分享给大伙。下面是LSTM的一般结构

LSTM对于RNN的改进在于它改进了一般RNN的隐含层。一般RNN的隐含层是只有状态s的,但LSTM在隐含层中加入了新的状态c,c就叫做单元状态。我们这里说的状态s就怼应上图中的h。
除了单元状态外,LSTM还引入了门的概念。门的作用其实就是对通过门的矢量进行一种增益处理。门其实就是一个矩阵,这个矩阵中元素的数值根据一些参数来确定。我们的输入数据纵向结合上次的隐含层输出数据后,与门进行按元素相乘运算。
LSTM在隐含层一共设置了3个门:
- 遗忘门(f):它决定了上一时刻的单元状态有多少会保留进当前时刻的单元状态
- 输入门(i):它决定了当前时刻的临时单元状态有多少会保留进当前时刻的单元状态
- 输出门(o):它决定了当前时刻的单元状态有多少会保留进当前时刻的输出状态
这些门的计算公式都是一样的,区别只是它们的参数不同。
















 284
284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











