






 本文深入解析了FCN网络,这是深度学习语义分割领域的开山之作。文章详细介绍了FCN如何通过将全连接层替换为卷积层实现端到端的像素到像素的密集预测,同时展示了FCN的不同版本(FCN-32s、FCN-16s和FCN-8s)在分割精度上的逐步提升。
本文深入解析了FCN网络,这是深度学习语义分割领域的开山之作。文章详细介绍了FCN如何通过将全连接层替换为卷积层实现端到端的像素到像素的密集预测,同时展示了FCN的不同版本(FCN-32s、FCN-16s和FCN-8s)在分割精度上的逐步提升。
笔者最近在集中时间撰写深度学习图像分割一书,需要对语义分割众多经典论文进行回顾和精读。目前在写第五章:基于U形结构的网络结构设计,从语义分割的开山之作FCN开始,重启精读之路。

随着CNN在图像识别中取得巨大成功,一些经典的图像分类网络(AlexNet、VGG、GoogLeNet、ResNet)也逐渐被应用于更加细分的视觉任务中。很多研究者也在探索如何将分类网络进行改造后用于语义分割的密集预测问题(dense predictions)。在更高效的语义分割网络提出之前,学术界用于密集预测任务的模型主要有以下几个特点:
(1)小模型。早期的网络结构受限于数据量和高性能的计算资源,在设计上一般不会使用过大的模型。
(2)分块训练。分块训练(patchwise training)在当时是图像训练的普遍做法,但该方法对于全卷积网络的训练会显得相对低效,但分块训练的优点在于能够规避类别不均衡问题,并且能够缓解密集分块的空间相关性问题。
(3)输入移位与输出交错。该方法可以视为一种输入与输出的变换方法,在OverFeat等结构中被广泛使用。
(4)后处理。对于神经网络输出质量不高的问题,对输出加后处理也是常见做法,常用的后处理方法包括超像素投影(superpixel projection)、随机场正则化(random field regularization)和图像滤波处理等。
可以看到,早期用于目标检测、关键点预测和语义分割等密集预测问题整体来看有两个缺陷,一是无法实现端到端(end-to-end)的流程,模型整体效率不佳;第二个则是不能做到真正的密集预测的特征:像素到像素(pixels-to-pixels)的预测。
全卷积网络(Fully Convolutional Networks, FCN)的提出,正好可以解决早期网络结构普遍存在的上述两个缺陷。FCN在2015年的一篇论文Fully Convolutional Networks for Semantic Segmentation中提出,其主要思路在于用卷积层代替此前分类网络中的全连接层,将全连接层的语义标签输出改为卷积层的语义热图(heatmap)输出,再结合上采样技术实现像素到像素的密集预测。如下图所示,上图为常见分类网络的流程,在五层卷积网络之后有三层全连接网络,最后输出一个包含类别语义信息的输出概率;下图为FCN网络流程,在上图分类网络的基础上,将最后三层全连接层改为卷积层,输出也相应的变为分类预测的热图,这样就为了最后的像素级的密集预测提供了基础。
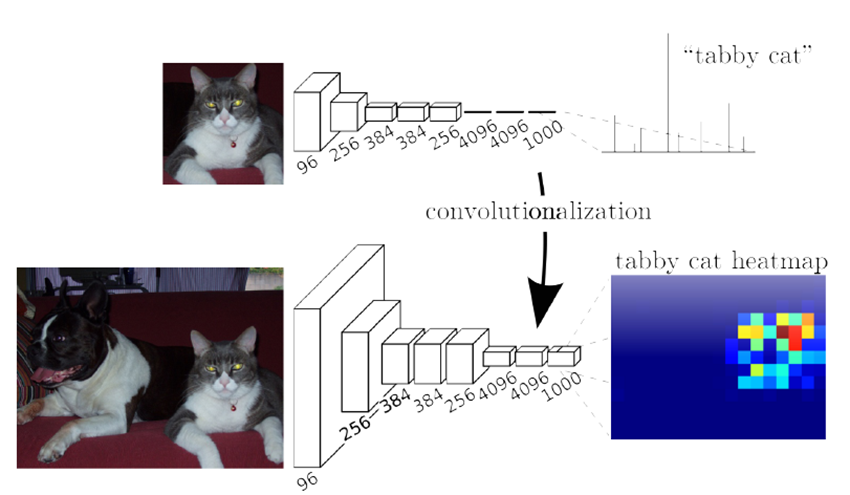
所以,FCN实现密集预测的关键在于修改全连接层为卷积层,那么具体是如何修改的呢?先来详细分析一下的卷积层和全连接层的特征。卷积层与全连接层最大的区别在于卷积层每次计算时只与输入图像中一个具体的局部做运算,但二者都是做点积计算,其函数形式是类似的。假设给定在指定网络层任意坐标点(i,j)的数据向量Xij,而下一层对应坐标点的数据向量为Yij,有:
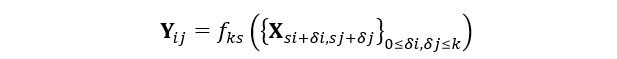
其中为卷积核大小或者权重向量长度,s为步长(stride),而f_ks则表示当前层到下一层的映射函数,f_ks既可以表示为卷积层又可以表示为全连接层,所以二者之间的转换是有理论基础的。将全连接层修改为卷积层,从实际操作上来看是容易的,以VGG16中第一个全连接层25088x4096尺寸为例,现将其转化为512x7x7x4096大小的卷积层,即输入大小为7x7x512,卷积核为512个77大小的卷积核,通道数为4096,相应的输出大小为1x1x4096。在PyTorch中测试全连接层与卷积层的转换,如下代码所示。
# 导入PyTorch库
import torch
from torch import nn
# 指定输入向量
x = torch.rand(25088,)
# 定义全连接层
fc = nn.Linear(25088, 4096)
# 定义卷积层
conv2d = nn.Conv2d(512, 4096, 7)
# 输出全连接层计算
fc_output = fc(x)
print(fc_output.size())
# 输入向量变换
x = torch.reshape(x, (1, 512, 7, 7))
# 数据卷积层计算
conv_output = conv2d(x)
print(conv_output.size())输出为:
torch.Size([4096])
torch.Size([1, 4096, 1, 1])代码中分别创建了一个具有转换关系的全连接层和卷积层,在给定同样输入大小的条件下,二者的输出大小是一致的。
FCN分别在AlexNet、VGG和GoogLeNet上进行了全连接层转卷积层的修改,通过实验发现以VGG16作为主干网络效果最好,完整的FCN结构如下图所示,第一行最左边为原始输入图像,图像尺寸为32x32,conv为卷积层,pool为池化层,可以注意到conv6-7是最后的卷积层,此时得到的密集预测热图尺寸为输入图像的1/32,为了实现像素到像素的预测,还需要对热图进行上采样,FCN采用双线性插值(bilinear interpolation)进行上采样,所以这里需要将热图上采样32倍来恢复到原始图像的尺寸,因而第一行的网络结构也叫FCN-32s。直接进行32倍上采样得到的输出无疑是较为粗糙的,为了提高像素预测质量,FCN又分别有FCN-16s和FCN-8s的改进版本。图中第二行即为FCN-16s,主要区别在于先将conv7(1x1)的输出热图进行2倍上采样,然后将其与pool4(2x2)进行融合,最后对融合后的结果进行16倍上采样得到最终预测结果,同理FCN-8s将pool3(4x4)、2倍上采样后的pool4(4x4)以及4倍上采样的conv7(4x4)进行融合,最后再进行8倍的上采样得到语义分割图像。
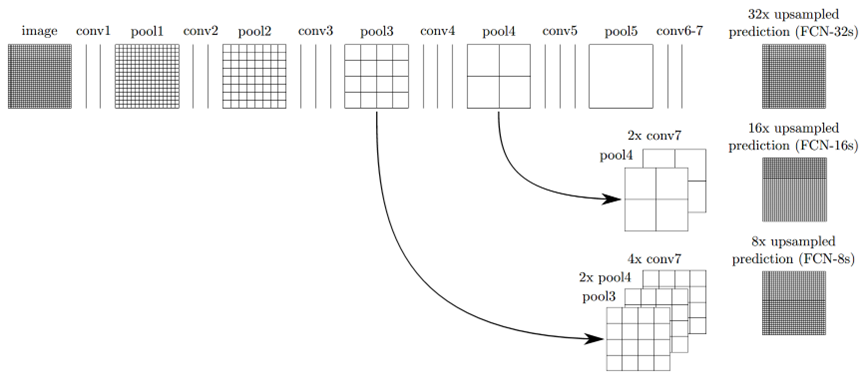
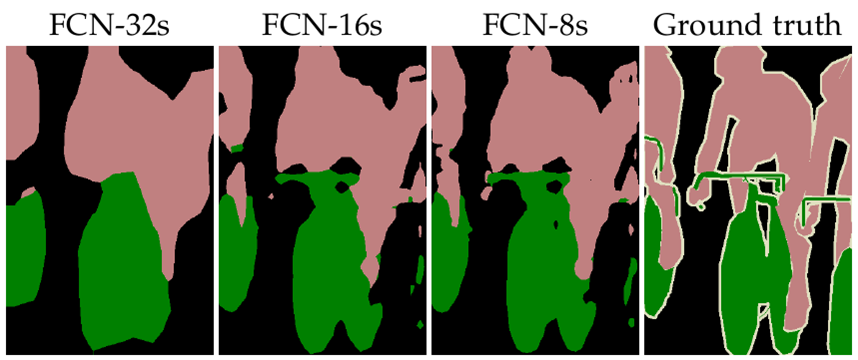
所以,从FCN-32s到FCN-8s,其实一种粗分割到精细分割的演变过程,FCN通过融合浅层图像特征和深层卷积热图的方式来得到当时的SOTA(State of the art)水平的语义分割模型。下图是FCN-32s、FCN-16s和FCN-8s在同一张图像上的分割效果,与分割的标准图像(Ground truth)相比,可以看到三个模型的分割精度是在不断优化的。
下方代码给出FCN-8s的一个PyTorch简略实现方式,便于读者加深对FCN的理解。代码中对于卷积下采样使用了VGG16的预训练权重,分别构建了四个特征提取模块、一个卷积块和三个独立的卷积层。在前向传播流程中,将conv7、pool3和pool4进行融合,最后再做8倍的双线性插值上采样。
# 导入PyTorch相关模块
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import models
### 定义FCN-8s模型类
class FCN8(nn.Module):
def __init__(self, num_classes):
super().__init__()
# 提取VGG16预训练权重作为特征
feats =list(models.vgg16(pretrained=True).features.children())
# 取前9层为第一特征模块
self.feat1 = nn.Sequential(*feats[0:9])
# 取第10-15层为第二特征模块
self.feat2 = nn.Sequential(*feats[10:16])
# 取第16-22层为第三特征模块
self.feat3 = nn.Sequential(*feats[17:23])
# 取后6层为第四特征模块
self.feat4 = nn.Sequential(*feats[24:30])
# 卷积层权重不参与训练更新
for m in self.modules():
if isinstance(m, nn.Conv2d):
m.requires_grad = False
# 定义卷积块
self.conv_blocks = nn.Sequential(
nn.Conv2d(512, 4096, 7),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Conv2d(4096, 4096, 1),
nn.ReLU(inplace=True),
nn.Dropout(),
)
# 改最后三层的全连接层为卷积层
self.conv1 = nn.Conv2d(256, num_classes, 1)
self.conv2 = nn.Conv2d(512, num_classes, 1)
self.conv3 = nn.Conv2d(4096, num_classes, 1)
### 定义前向计算流程
def forward(self, x):
feat1 = self.feat1(x)
feat2 = self.feat2(feat1)
feat3 = self.feat3(feat2)
feat4 = self.feat4(feat3)
conv_blocks = self.conv_blocks(feat4)
conv1 = self.conv1(feat2)
conv2 = self.conv2(feat3)
conv3 = self.conv3(conv_blocks)
outputs = F.upsample_bilinear(conv_blocks, conv2.size()[2:])
# 第一次融合
outputs += conv2
outputs = F.upsample_bilinear(outputs, conv1.size()[2:])
# 第二次融合
outputs += conv1
return F.upsample_bilinear(outputs, x.size()[2:])FCN是深度学习语义分割网络的开山之作,在结构设计上率先将全卷积网络用于深度学习语义分割任务,在经典分类网络的基础上实现了像素到像素和端到端的分割。FCN整体上已具备编解码架构的U形网络雏形,为后续的网络设计开创了坚实的基础。
往期精彩:
完结!《机器学习 公式推导与代码实现》全书1-26章PPT下载

















 1637
1637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









