






In Defense of Classical Image Processing: Fast Depth Completion on the CPU论文学习
978-1-5386-6481-0/18/$31.00 ©2018 IEEE
DOI 10.1109/CRV.2018.00013
介绍
本文旨在说明,与基于深度学习的方法相比,设计良好的经典图像处理算法在某些任务上仍然可以提供非常有竞争力的结果。
介绍深度补全的作用。
指出现在使用深度学习算法的弊端,1是需要大量的数据驱动,2是需要硬件支持即GPU,GPU模块也十分耗电。并指出如果没有扎实的理论基础盲目的建立深度模型效果不好,因此采用经典算法。
相关工作
深度补全目前有两个大方向,即引导深度补全和非引导深度补全。
引导深度补全
依靠彩色图像作为指导来完成深度图的绘制。以往的各种算法都提出了联合双边滤波对目标深度图[11]、[12]、[13]进行“补孔”。中值滤波器也被扩展到从彩色图像引导深度补全[14]。近年来,针对导向深度完成问题[15]、[16],出现了深度学习方法。这些方法已经被证明可以生成更高质量的深度图,但都是数据驱动的,需要大量的训练数据才能很好地实现。
算法
主要有以下8步,下面是对这整个步骤的学习:
1.Depth Inversion(深度反演)
第一步是对KITTI数据集中的深度数据进行膨胀操作。
OPENCV中的图像形态学—两个基本运算,腐蚀和膨胀。
二值形态学
腐蚀
粗略的说,腐蚀可以使目标区域范围“变小”,其实质造成图像的边界收缩,可以用来消除小且无意义的目标物。式子表达为:
该式子表示用结构B腐蚀A,需要注意的是B中需要定义一个原点,【而B的移动的过程与卷积核移动的过程一致,同卷积核与图像有重叠之后再计算一样】当B的原点平移到图像A的像元(x,y)时,如果B在(x,y)处,完全被包含在图像A重叠的区域,(也就是B中为1的元素位置上对应的A图像值全部也为1)则将输出图像对应的像元(x,y)赋值为1,否则赋值为0。
我们看一个演示图。
B依顺序在A上移动(和卷积核在图像上移动一样,然后在B的覆盖域上进行形态学运算),当其覆盖A的区域为[1,1;1,1]或者[1,0;1,1]时,(也就是B中‘1’是覆盖区域的子集)对应输出图像的位置才会为1。膨胀
粗略地说,膨胀会使目标区域范围“变大”,将于目标区域接触的背景点合并到该目标物中,使目标边界向外部扩张。作用就是可以用来填补目标区域中某些空洞以及消除包含在目标区域中的小颗粒噪声。
该式子表示用结构B膨胀A,将结构元素B的原点平移到图像像元(x,y)位置。如果B在图像像元(x,y)处与A的交集不为空(也就是B中为1的元素位置上对应A的图像值至少有一个为1),则输出图像对应的像元(x,y)赋值为1,否则赋值为0。
演示图为:
开运算就是先腐蚀再膨胀,闭运算就是先膨胀再腐蚀。
开操作可以平滑物体轮廓,断开狭窄的间断和消除细小的突出物。闭操作可以消弭狭窄的间断,消除小的孔洞。灰度形态学
腐蚀
那么灰度形态学中的腐蚀就是类似卷积的一种操作,用P减去结构元素B形成的小矩形,取其中最小值赋到对应原点的位置即可。
我们来看一个实例,进行加深对灰度形态学的理解。
假设我们有如下的图像A和结构元素B:
我们对输出图像的第一个元素的输出结果进行具体的展示,也就是原点对应的4的位置。输出图像其他的元素的值也都是这样得到的。我们会看到,B首先覆盖的区域就是被减数矩阵,然后在其差矩阵中求min(最小值)来作为原点对应位置的值。膨胀
根据上面对腐蚀的描述,我们对膨胀做出同样的描述,灰度形态学中的膨胀就是类似卷积的一种操作,用P加上B,然后取这个区域中的最大值赋值给结构元素B的原点所对应的位置。
相比较于原图像,因为腐蚀的结果要使得各像元比之前变得更小,所以适用于去除高峰噪声。而灰度值膨胀的结果会使得各像元比之前的变得更大,所以适用于去除低谷噪声。
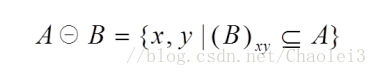

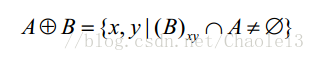





在KITTI数据集中深度数据范围是0-80m,而缺失的空洞深度也是0,较近的物体深度接近0,如果直接进行膨胀操作会令较近物体的边缘信息丢失,作者在这里加入了深度反转,留出一个20m的缓冲区域, D i n v e r t e d = 100.0 − D i n p u t D_{inverted}=100.0-D_{input} Dinverted=100.0−Dinput,20m缓冲区用于偏移有效深度,以便在后续操作中屏蔽无效像素。
2.Custom Kernel Dilation(自定义内核扩张)
第一步是对有效深度数据旁边的缺失信息进行填补(膨胀操作的作用),因为这些像素最有可能与有效深度共享接近的深度值。接下来是对第一步使用的内核进行设计。作者对比了下面四个内核,选择了第四个。

3.Small Hole Closure(小洞关闭)
上面操作之后仍然有许多空洞,作者考虑了环境中物体的结构,注意到附近的膨胀深度块可以连接起来形成物体的边缘。用5×5的FULL核来做闭操作,这个步骤的作用是连接附近的深度值,可以看作是一组5×5像素的平面,从最远的位置堆叠到最近的位置 。
4.Small Hole Fill(小洞填充)
一些小到中尺寸的空洞在前几步不会被填充,为了填充这些空洞,先计算一个空像素掩码(a mask of empty pixels?)紧接着做一个7×7的FULL核膨胀操作,这个操作只会填充空像素,而保持先前计算过的有效像素不变。
5.Extension to Top of Frame(拓展到框架顶部)
为了考虑到高大的物体,如树木、杆子和延伸到激光雷达点顶部的建筑物,沿着每一列的顶部值外推到图像的顶部,提供了一个更密集的深度图输出。
6.Large Hole Fill(大孔填充)
用31×31的FULL核来填充剩下的大的空洞,保存原有有效像素不变。
7.Median and Gaussian Blur(中值和高斯模糊)
用5×5的中值内核来去除膨胀过程中存在的异常值,相当于去噪,在保持局部边缘的时候去除了异常值。最后用5×5的高斯模糊来平滑。
8.Depth Inversion(深度反演)
对应第一步,从编码中得到原始数据。
实验
用RMSE作为评判标准。
这部分与其他方法比较证明RMSE和MAE都是最优的,并且只需要CPU。
说了算法设计思路:
为了设计该算法,遵循贪婪设计过程。由于有效像素附近的空像素有可能共享相似的值,我们用更小到更大的填充孔来构造算法的顺序。这允许每个有效像素的有效面积缓慢增加,同时仍然保持局部结构。剩下的空白区域会被推断出来,但是会变得比以前小很多。最后一个模糊步骤用于减少输出噪声和平滑局部平面。
首先探讨了膨胀核尺寸的设计选择的影响,然后讨论了膨胀核的形状,最后讨论了膨胀后使用的模糊核。我们选择每个实验的最佳结果,继续下一步的设计。由于这种贪婪的设计方法,前两个关于内核大小和形状的实验不包括步骤7的模糊。最后的算法设计使用了每个实验中表现最好的设计,以达到最佳的结果。
代码学习
demo
import glob
import os
import sys
import time
import cv2
import numpy as np
import png
from ip_basic import depth_map_utils
from ip_basic import vis_utils
def main():
"""Depth maps are saved to the 'outputs' folder.
"""
##############################
# Options
##############################
# Validation set
input_depth_dir = os.path.expanduser(
'~/PycharmProjects/IPbasic/ip_basic-master/Kitti/depth/val_selection_cropped/velodyne_raw')
data_split = 'val'
# Test set
# input_depth_dir = os.path.expanduser(
# '~/Kitti/depth/test_depth_completion_anonymous/velodyne_raw')
# data_split = 'test'
# Fast fill with Gaussian blur @90Hz (paper result)
fill_type = 'fast'
extrapolate = True
blur_type = 'gaussian'
# Fast Fill with bilateral blur, no extrapolation @87Hz (recommended)
# fill_type = 'fast'
# extrapolate = False
# blur_type = 'bilateral'
# Multi-scale dilations with extra noise removal, no extrapolation @ 30Hz
# fill_type = 'multiscale'
# extrapolate = True
# blur_type = 'bilateral'
# Save output to disk or show process
save_output = True
##############################
# Processing
##############################
if save_output:
# Save to Disk
show_process = False
save_depth_maps = True
else:
if fill_type == 'fast':
raise ValueError('"fast" fill does not support show_process')//处理异常,异常会被传播到python解释器;
如果没有这句,程序会停止并显示异常的传播轨迹。
# Show Process
show_process = True
save_depth_maps = False
# Create output folder
this_file_path = os.path.dirname(os.path.realpath(__file__))//dirname返回文件路径;
realpath返回path的真实路径。
__file__表示文件当前路径;
__doc__表示文件描述;
在python中,当一个module作为整体被执行时,moduel.__name__的值是"__main__";
当一个module被其它module引用时,module.__name__将是module自己的名字;
当一个module被其它module引用时,其本身并不需要一个可执行的入口main了。
outputs_dir = this_file_path + '/outputs'
os.makedirs(outputs_dir, exist_ok=True)//区别在于,os.makedirs会递归的建立输入的路径,即使是上层的路径不存在,
它也会建立这个路径,而os.mkdir父级路径不存在,那么就会报错。exist_ok默认值为False,如果创建的文件夹存在会报错,
这里设成True可能是不会报错吧?
output_folder_prefix = 'depth_' + data_split
output_list = sorted(os.listdir(outputs_dir))//os.listdir返回指定路径下的文件和文件夹列表。
sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
list 的 sort 方法返回的是对已经存在的列表进行操作,而内建函数 sorted 方法
返回的是一个新的 list,而不是在原来的基础上进行的操作。
sorted(iterable, key=None, reverse=False) iterable -- 可迭代对象。
key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自
于可迭代对象中,指定可迭代对象中的一个元素来进行排序。reverse -- 排序规则,
reverse = True 降序 , reverse = False 升序(默认)。
if len(output_list) > 0:
split_folders = [folder for folder in output_list
if folder.startswith(output_folder_prefix)]//startswith() 方法用于检查字符串是否是以指定子字符串
开头,如果是则返回 True,否则返回 False。如果参数 beg 和 end 指定值,则在指定范围内检查。
if len(split_folders) > 0:
last_output_folder = split_folders[-1]//-1是从后往前,即最后一个文件夹,如果是0就是第一个文件夹,-2是倒数第二个,
1是第一个
last_output_index = int(last_output_folder.split('_')[-1])//int转化为整数类型
else:
last_output_index = -1
else:
last_output_index = -1
output_depth_dir = outputs_dir + '/{}_{:03d}'.format(
output_folder_prefix, last_output_index + 1)//format基本语法是通过 {} 和 : 来代替以前的 % 。这里意思是用format中的
两个参数来代替'/{}_{:03d}'中的{}和{:03d}
if save_output:
if not os.path.exists(output_depth_dir):
os.makedirs(output_depth_dir)
else:
raise FileExistsError('Already exists!')
print('Output dir:', output_depth_dir)
# Get images in sorted order
images_to_use = sorted(glob.glob(input_depth_dir + '/*'))//glob.glob返回所有匹配的文件路径列表。它只有一个参数pathname,
定义了文件路径匹配规则,这里可以是绝对路径,也可以是相对路径。
# Rolling average array of times for time estimation
avg_time_arr_length = 10
last_fill_times = np.repeat([1.0], avg_time_arr_length)//numpy.repeat(a,repeats,axis=None);
参数的意义:axis=None,时候就会flatten当前矩阵,
实际上就是变成了一个行向量
axis=0,沿着y轴复制,实际上增加了行数
axis=1,沿着x轴复制,实际上增加列数
last_total_times = np.repeat([1.0], avg_time_arr_length)
num_images = len(images_to_use)
for i in range(num_images):
depth_image_path = images_to_use[i]
# Calculate average time with last n fill times
avg_fill_time = np.mean(last_fill_times)
avg_total_time = np.mean(last_total_times)
# Show progress
sys.stdout.write('\rProcessing {} / {}, '
'Avg Fill Time: {:.5f}s, '
'Avg Total Time: {:.5f}s, '
'Est Time Remaining: {:.3f}s'.format(
i, num_images - 1, avg_fill_time, avg_total_time,
avg_total_time * (num_images - i)))
sys.stdout.flush()//sys.stdout.write中\r可以自动清除上一次输出的东西只输出最后一次的结果,所以这两句可以看到一个动态的处理图片的过程
# Start timing
start_total_time = time.time()//time.time()返回当前时间的时间戳(1970纪元后经过的浮点秒数)。
time.localtime(time.time())返回时间的结构信息2009, 2, 17, 10, 48, 39, 1, 48, 0
(分别是年,月,日,小时,分钟,秒,后面的不清楚)
# Load depth projections from uint16 image
depth_image = cv2.imread(depth_image_path, cv2.IMREAD_ANYDEPTH)//CV_LOAD_IMAGE_ANYDEPTH返回图像的深度不变。
CV_LOAD_IMAGE_COLOR总是返回一个彩色图。
CV_LOAD_IMAGE_GRAYSCALE总是返回一个灰度图。
第二个参数太没用过,之后再了解了解。
projected_depths = np.float32(depth_image / 256.0)
# Fill in
start_fill_time = time.time()
if fill_type == 'fast':
final_depths = depth_map_utils.fill_in_fast(
projected_depths, extrapolate=extrapolate, blur_type=blur_type)
elif fill_type == 'multiscale':
final_depths, process_dict = depth_map_utils.fill_in_multiscale(
projected_depths, extrapolate=extrapolate, blur_type=blur_type,
show_process=show_process)
else:
raise ValueError('Invalid fill_type {}'.format(fill_type))
end_fill_time = time.time()
# Display images from process_dict
if fill_type == 'multiscale' and show_process:
img_size = (570, 165)
x_start = 80
y_start = 50
x_offset = img_size[0]
y_offset = img_size[1]
x_padding = 0
y_padding = 28
img_x = x_start
img_y = y_start
max_x = 1900
row_idx = 0
for key, value in process_dict.items():
image_jet = cv2.applyColorMap(
np.uint8(value / np.amax(value) * 255),
cv2.COLORMAP_JET)
vis_utils.cv2_show_image(
key, image_jet,
img_size, (img_x, img_y))
img_x += x_offset + x_padding
if (img_x + x_offset + x_padding) > max_x:
img_x = x_start
row_idx += 1
img_y = y_start + row_idx * (y_offset + y_padding)
# Save process images
cv2.imwrite('process/' + key + '.png', image_jet)
cv2.waitKey()
# Save depth images to disk
if save_depth_maps:
depth_image_file_name = os.path.split(depth_image_path)[1]//分隔,取图像文件名
# Save depth map to a uint16 png (same format as disparity maps)
file_path = output_depth_dir + '/' + depth_image_file_name
with open(file_path, 'wb') as f:
depth_image = (final_depths * 256).astype(np.uint16)//当我们写文件时,操作系统往往不会立刻把数据写入磁盘,而
是放到内存缓存起来,空闲的时候再慢慢写入。只有调用
close()方法时,操作系统才保证把没有写入的数据全部写入
磁盘。忘记调用close()的后果是数据可能只写了一部分到磁
盘,剩下的丢失了。所以,还是用with语句来得保险。
# pypng is used because cv2 cannot save uint16 format images
writer = png.Writer(width=depth_image.shape[1],
height=depth_image.shape[0],
bitdepth=16,
greyscale=True)
writer.write(f, depth_image)
end_total_time = time.time()
# Update fill times
last_fill_times = np.roll(last_fill_times, -1)//意思是将last_fill_times,沿着axis的方向,滚动shift长度
last_fill_times[-1] = end_fill_time - start_fill_time
# Update total times
last_total_times = np.roll(last_total_times, -1)
last_total_times[-1] = end_total_time - start_total_time
if __name__ == "__main__":
main()
depth_map_utils
import collections
import cv2
import numpy as np
# Full kernels
FULL_KERNEL_3 = np.ones((3, 3), np.uint8)
FULL_KERNEL_5 = np.ones((5, 5), np.uint8)
FULL_KERNEL_7 = np.ones((7, 7), np.uint8)
FULL_KERNEL_9 = np.ones((9, 9), np.uint8)
FULL_KERNEL_31 = np.ones((31, 31), np.uint8)
# 3x3 cross kernel
CROSS_KERNEL_3 = np.asarray(
[
[0, 1, 0],
[1, 1, 1],
[0, 1, 0],
], dtype=np.uint8)
# 5x5 cross kernel
CROSS_KERNEL_5 = np.asarray(
[
[0, 0, 1, 0, 0],
[0, 0, 1, 0, 0],
[1, 1, 1, 1, 1],
[0, 0, 1, 0, 0],
[0, 0, 1, 0, 0],
], dtype=np.uint8)
# 5x5 diamond kernel
DIAMOND_KERNEL_5 = np.array(
[
[0, 0, 1, 0, 0],
[0, 1, 1, 1, 0],
[1, 1, 1, 1, 1],
[0, 1, 1, 1, 0],
[0, 0, 1, 0, 0],
], dtype=np.uint8)
# 7x7 cross kernel
CROSS_KERNEL_7 = np.asarray(
[
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
], dtype=np.uint8)
# 7x7 diamond kernel
DIAMOND_KERNEL_7 = np.asarray(
[
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 1, 1, 1, 0, 0],
[0, 1, 1, 1, 1, 1, 0],
[1, 1, 1, 1, 1, 1, 1],
[0, 1, 1, 1, 1, 1, 0],
[0, 0, 1, 1, 1, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
], dtype=np.uint8)
def fill_in_fast(depth_map, max_depth=100.0, custom_kernel=DIAMOND_KERNEL_5,
extrapolate=False, blur_type='bilateral'):
"""Fast, in-place depth completion.
Args:
depth_map: projected depths
max_depth: max depth value for inversion
custom_kernel: kernel to apply initial dilation
extrapolate: whether to extrapolate by extending depths to top of
the frame, and applying a 31x31 full kernel dilation
blur_type:
'bilateral' - preserves local structure (recommended)
'gaussian' - provides lower RMSE
Returns:
depth_map: dense depth map
"""
# Invert
valid_pixels = (depth_map > 0.1)
depth_map[valid_pixels] = max_depth - depth_map[valid_pixels]
# Dilate
depth_map = cv2.dilate(depth_map, custom_kernel)
# Hole closing
depth_map = cv2.morphologyEx(depth_map, cv2.MORPH_CLOSE, FULL_KERNEL_5)
# Fill empty spaces with dilated values
empty_pixels = (depth_map < 0.1)
dilated = cv2.dilate(depth_map, FULL_KERNEL_7)
depth_map[empty_pixels] = dilated[empty_pixels]
# Extend highest pixel to top of image
if extrapolate:
top_row_pixels = np.argmax(depth_map > 0.1, axis=0)//argmax当axis=0找到每列最大值的位置,axis=1找到每行最大值的位置
不设置axis时找到数组中最大的值并输出值
top_pixel_values = depth_map[top_row_pixels, range(depth_map.shape[1])]
for pixel_col_idx in range(depth_map.shape[1]):
depth_map[0:top_row_pixels[pixel_col_idx], pixel_col_idx] = \
top_pixel_values[pixel_col_idx]
# Large Fill
empty_pixels = depth_map < 0.1
dilated = cv2.dilate(depth_map, FULL_KERNEL_31)
depth_map[empty_pixels] = dilated[empty_pixels]
# Median blur
depth_map = cv2.medianBlur(depth_map, 5)//medianBlur()函数使用中值滤波器来平滑图像。
# Bilateral or Gaussian blur
if blur_type == 'bilateral':
# Bilateral blur
depth_map = cv2.bilateralFilter(depth_map, 5, 1.5, 2.0)
elif blur_type == 'gaussian':
# Gaussian blur
valid_pixels = (depth_map > 0.1)
blurred = cv2.GaussianBlur(depth_map, (5, 5), 0)
depth_map[valid_pixels] = blurred[valid_pixels]
# Invert
valid_pixels = (depth_map > 0.1)
depth_map[valid_pixels] = max_depth - depth_map[valid_pixels]
return depth_map
def fill_in_multiscale(depth_map, max_depth=100.0,
dilation_kernel_far=CROSS_KERNEL_3,
dilation_kernel_med=CROSS_KERNEL_5,
dilation_kernel_near=CROSS_KERNEL_7,
extrapolate=False,
blur_type='bilateral',
show_process=False):
"""Slower, multi-scale dilation version with additional noise removal that
provides better qualitative results.
Args:
depth_map: projected depths
max_depth: max depth value for inversion
dilation_kernel_far: dilation kernel to use for 30.0 < depths < 80.0 m
dilation_kernel_med: dilation kernel to use for 15.0 < depths < 30.0 m
dilation_kernel_near: dilation kernel to use for 0.1 < depths < 15.0 m
extrapolate:whether to extrapolate by extending depths to top of
the frame, and applying a 31x31 full kernel dilation
blur_type:
'gaussian' - provides lower RMSE
'bilateral' - preserves local structure (recommended)
show_process: saves process images into an OrderedDict
Returns:
depth_map: dense depth map
process_dict: OrderedDict of process images
"""
# Convert to float32
depths_in = np.float32(depth_map)
# Calculate bin masks before inversion
valid_pixels_near = (depths_in > 0.1) & (depths_in <= 15.0)
valid_pixels_med = (depths_in > 15.0) & (depths_in <= 30.0)
valid_pixels_far = (depths_in > 30.0)
# Invert (and offset)
s1_inverted_depths = np.copy(depths_in)
valid_pixels = (s1_inverted_depths > 0.1)
s1_inverted_depths[valid_pixels] = \
max_depth - s1_inverted_depths[valid_pixels]
# Multi-scale dilation
dilated_far = cv2.dilate(
np.multiply(s1_inverted_depths, valid_pixels_far),
dilation_kernel_far)
dilated_med = cv2.dilate(
np.multiply(s1_inverted_depths, valid_pixels_med),
dilation_kernel_med)
dilated_near = cv2.dilate(
np.multiply(s1_inverted_depths, valid_pixels_near),
dilation_kernel_near)
# Find valid pixels for each binned dilation
valid_pixels_near = (dilated_near > 0.1)
valid_pixels_med = (dilated_med > 0.1)
valid_pixels_far = (dilated_far > 0.1)
# Combine dilated versions, starting farthest to nearest
s2_dilated_depths = np.copy(s1_inverted_depths)
s2_dilated_depths[valid_pixels_far] = dilated_far[valid_pixels_far]
s2_dilated_depths[valid_pixels_med] = dilated_med[valid_pixels_med]
s2_dilated_depths[valid_pixels_near] = dilated_near[valid_pixels_near]
# Small hole closure
s3_closed_depths = cv2.morphologyEx(
s2_dilated_depths, cv2.MORPH_CLOSE, FULL_KERNEL_5)
# Median blur to remove outliers
s4_blurred_depths = np.copy(s3_closed_depths)
blurred = cv2.medianBlur(s3_closed_depths, 5)
valid_pixels = (s3_closed_depths > 0.1)
s4_blurred_depths[valid_pixels] = blurred[valid_pixels]
# Calculate a top mask
top_mask = np.ones(depths_in.shape, dtype=np.bool)
for pixel_col_idx in range(s4_blurred_depths.shape[1]):
pixel_col = s4_blurred_depths[:, pixel_col_idx]
top_pixel_row = np.argmax(pixel_col > 0.1)
top_mask[0:top_pixel_row, pixel_col_idx] = False
# Get empty mask
valid_pixels = (s4_blurred_depths > 0.1)
empty_pixels = ~valid_pixels & top_mask
# Hole fill
dilated = cv2.dilate(s4_blurred_depths, FULL_KERNEL_9)
s5_dilated_depths = np.copy(s4_blurred_depths)
s5_dilated_depths[empty_pixels] = dilated[empty_pixels]
# Extend highest pixel to top of image or create top mask
s6_extended_depths = np.copy(s5_dilated_depths)
top_mask = np.ones(s5_dilated_depths.shape, dtype=np.bool)
top_row_pixels = np.argmax(s5_dilated_depths > 0.1, axis=0)
top_pixel_values = s5_dilated_depths[top_row_pixels,
range(s5_dilated_depths.shape[1])]
for pixel_col_idx in range(s5_dilated_depths.shape[1]):
if extrapolate:
s6_extended_depths[0:top_row_pixels[pixel_col_idx],
pixel_col_idx] = top_pixel_values[pixel_col_idx]
else:
# Create top mask
top_mask[0:top_row_pixels[pixel_col_idx], pixel_col_idx] = False
# Fill large holes with masked dilations
s7_blurred_depths = np.copy(s6_extended_depths)
for i in range(6):
empty_pixels = (s7_blurred_depths < 0.1) & top_mask
dilated = cv2.dilate(s7_blurred_depths, FULL_KERNEL_5)
s7_blurred_depths[empty_pixels] = dilated[empty_pixels]
# Median blur
blurred = cv2.medianBlur(s7_blurred_depths, 5)
valid_pixels = (s7_blurred_depths > 0.1) & top_mask
s7_blurred_depths[valid_pixels] = blurred[valid_pixels]
if blur_type == 'gaussian':
# Gaussian blur
blurred = cv2.GaussianBlur(s7_blurred_depths, (5, 5), 0)
valid_pixels = (s7_blurred_depths > 0.1) & top_mask
s7_blurred_depths[valid_pixels] = blurred[valid_pixels]
elif blur_type == 'bilateral':
# Bilateral blur
blurred = cv2.bilateralFilter(s7_blurred_depths, 5, 0.5, 2.0)
s7_blurred_depths[valid_pixels] = blurred[valid_pixels]
# Invert (and offset)
s8_inverted_depths = np.copy(s7_blurred_depths)
valid_pixels = np.where(s8_inverted_depths > 0.1)
s8_inverted_depths[valid_pixels] = \
max_depth - s8_inverted_depths[valid_pixels]
depths_out = s8_inverted_depths
process_dict = None
if show_process:
process_dict = collections.OrderedDict()
process_dict['s0_depths_in'] = depths_in
process_dict['s1_inverted_depths'] = s1_inverted_depths
process_dict['s2_dilated_depths'] = s2_dilated_depths
process_dict['s3_closed_depths'] = s3_closed_depths
process_dict['s4_blurred_depths'] = s4_blurred_depths
process_dict['s5_combined_depths'] = s5_dilated_depths
process_dict['s6_extended_depths'] = s6_extended_depths
process_dict['s7_blurred_depths'] = s7_blurred_depths
process_dict['s8_inverted_depths'] = s8_inverted_depths
process_dict['s9_depths_out'] = depths_out
return depths_out, process_dict
demo运行遇到的问题及解决
1.无png模块。
conda install -c eaton-lab pypng
2.运行完之后没有结果图。
设置断点发现输入文件夹路径错误,os.path.expanduser()会将path中的~/改成用户路径,即变为home/user/,修改路径后demo成功运行。
3.使用conda安装requirement.txt指定的依赖包
conda install --yes --file requirements.txt















 473
473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









