







目录
相较于VOC2006, VOC2007:
1)将类别从10增加到了20
2)并且增加了2种 taster challenges (segmentation and layout)
Compared to VOC2006 we have increased the number of classes from 10 to 20, and added the taster challenges. These tasters have been introduced to sample the interest in segmentation and layout.
1、数据集地址
数据集地址:http://host.robots.ox.ac.uk/pascal/VOC/voc2007/index.html
2、适用的比赛
- 适用于2个主要的比赛:Classification、Detection
- 2个尝试性比赛:Segmentation、Person Layout
1)Main Competitions
Classification:判断图片中是否有某一类物体,输出结果为:有 / 无
Detection: 预测物体的检测框,并且预测出物体的分类,输出结果为:矩形框&对应的分类

2)Taster Competitions
Segmentation: 生成基于像素的分割,得出物该类别物体在像素级的表示,否则为“背景”
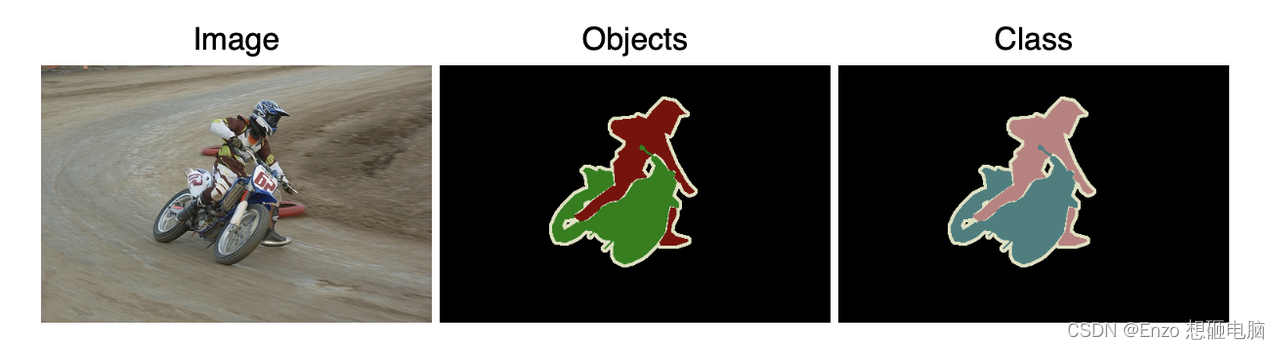
Person Layout: 预测人的每个肢体部分,并框起来

3、类别及类别的定义
1)数据集包含的类别
4大类,20子类
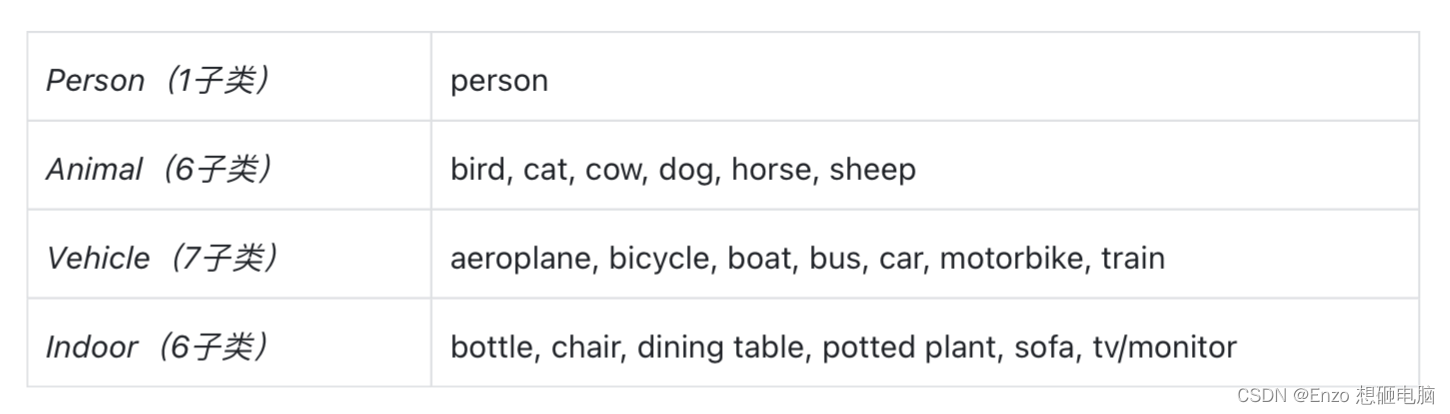
2)类别的定义

4、数据集
1)训练集、验证集、测试集
-
一共9963张图片,包括24640个标注物
其中,训练集+验证集 5012张,测试集 4951张 -
数据均匀分布:训练集合+验证集 占比 50%; 测试集占比 50%
-
图片和待识别物 在训练集/验证集和测试集中的分布大致是均匀的
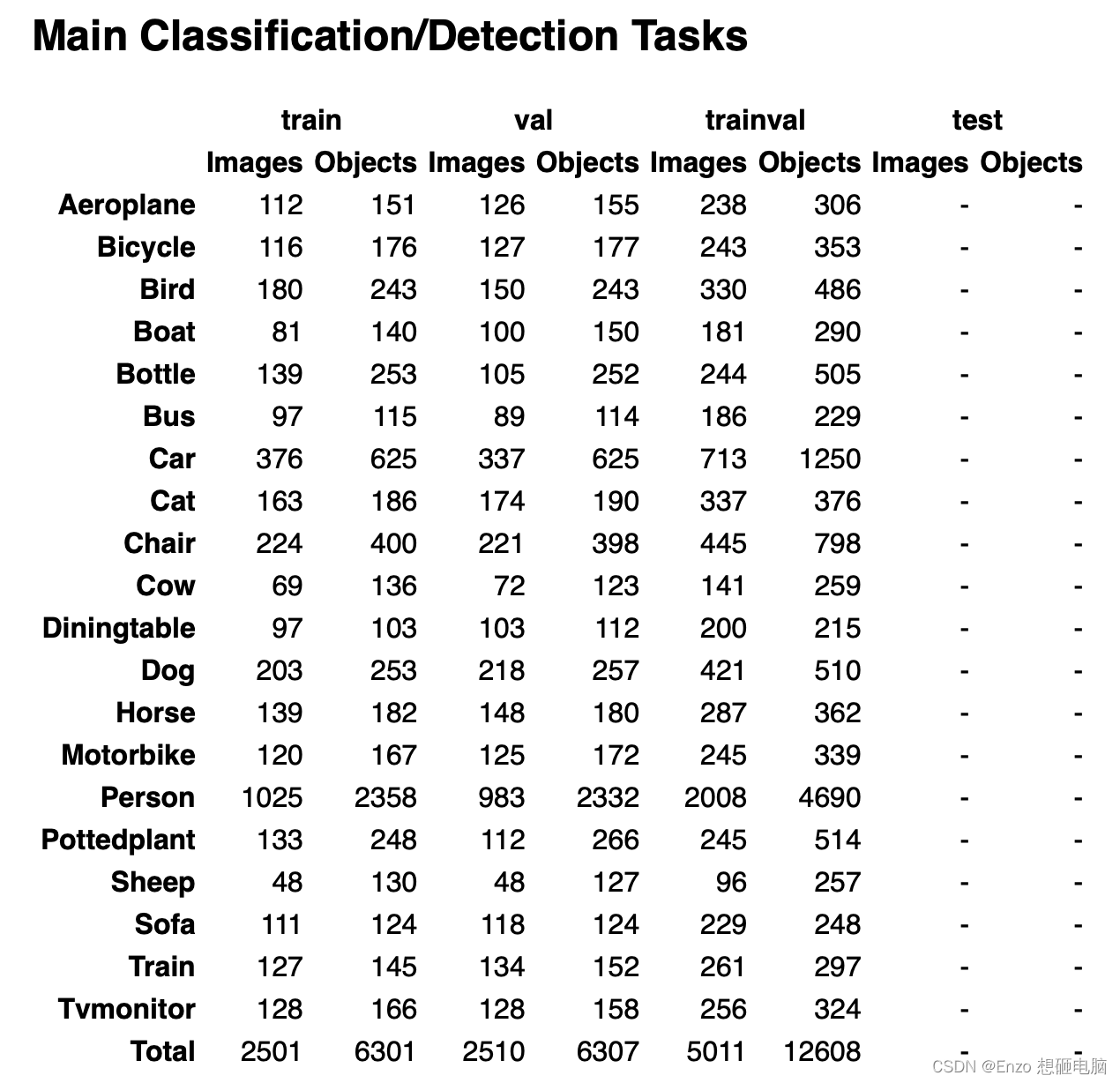
2)图片和待检测物在类别的分布详情
trainval 为 train 和 val 的和
5、标注准则

6、标注文档解析
标注原文档 示例
(路径示例:/pascal-voc-2012/VOC2012/Annotations/2007_000027.xml)
<annotation>
<folder>VOC2012</folder>
<filename>2007_000392.jpg</filename>
<source>
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
</source>
<size>
<width>500</width>
<height>332</height>
<depth>3</depth>
</size>
<segmented>1</segmented>
<object>
<name>horse</name>
<pose>Right</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>100</xmin>
<ymin>96</ymin>
<xmax>355</xmax>
<ymax>324</ymax>
</bndbox>
</object>
<object>
<name>person</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>198</xmin>
<ymin>58</ymin>
<xmax>286</xmax>
<ymax>197</ymax>
</bndbox>
</object>
</annotation>
解析函数
from lxml import etree
def parse_xml(class_dict, xml_path):
data_dict = {}
tree_root = etree.parse(xml_path)
# file name
data_dict['filename'] = tree_root.find("filename").text
class_list = []
coord_list = []
area_list = []
for object in tree_root.findall("object"):
# class
obj_class = class_dict[object.find("name").text]
class_list.append(obj_class)
# bounding box
bbox = object.find("bndbox")
xmin = float(bbox.find("xmin").text)
ymin = float(bbox.find("ymin").text)
xmax = float(bbox.find("xmax").text)
ymax = float(bbox.find("ymax").text)
coord_list.append([xmin, ymin, xmax, ymax])
# area
area = (ymax - ymin) * (xmax - xmin)
area_list.append(area)
data_dict['labels'] = class_list
data_dict['boxes'] = coord_list
data_dict['area'] = area_list
return data_dict
class_dict = {
"aeroplane": 1,
"bicycle": 2,
"bird": 3,
"boat": 4,
"bottle": 5,
"bus": 6,
"car": 7,
"cat": 8,
"chair": 9,
"cow": 10,
"diningtable": 11,
"dog": 12,
"horse": 13,
"motorbike": 14,
"person": 15,
"pottedplant": 16,
"sheep": 17,
"sofa": 18,
"train": 19,
"tvmonitor": 20
}
xml_path = '/pascal-voc-2012/VOC2012/Annotations/2007_000027.xml'
data = parse_xml(class_dict, xml_path)
print(data)
输出
{'filename': '2008_000008.jpg',
'labels': [13, 15],
'boxes': [[53.0, 87.0, 471.0, 420.0], [158.0, 44.0, 289.0, 167.0]],
'area': [139194.0, 16113.0]
}
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











