







语料库
概念
语料库是为了某一个或者多个应用专门收集的、有一定结构的、有代表性的、可以被计算机程序检索的、具有一定规模的语料集合。
理解
语料库就是一个“语言数据库”,里面存了一大堆真实的语言材料,比如:
-
书里的句子
-
日常聊天的记录
-
新闻文章
-
电影台词
-
甚至微博、朋友圈的文字……
分类
| 分类标准 | 类型 | 特点 | 例子 |
|---|---|---|---|
| 按语言类型 | 单语语料库 | 仅包含一种语言的数据 | 《现代汉语语料库》 |
| 双语/多语语料库 | 两种或多种语言对齐(如原文与译文对照) | Europarl(欧洲议会平行语料库) | |
| 方言语料库 | 收录特定方言的语音或文本 | 粤语口语语料库 | |
| 按内容形式 | 书面语语料库 | 书籍、新闻、论文等书面文本 | BCC汉语语料库 |
| 口语语料库 | 录音转写的对话、访谈等 | Switchboard(英语电话对话语料库) | |
| 多媒体语料库 | 包含文本、音频、视频等多模态数据 | TV News Channel(电视新闻语料库) | |
| 按标注程度 | 生语料(未标注) | 原始文本,无任何人工标注 | 爬取的网页原始数据 |
| 标注语料库 | 带有词性、句法、语义等标签 | Penn Treebank(英语树库) | |
| 按领域/用途 | 通用语料库 | 覆盖多领域,用于一般语言研究 | COCA(美国当代英语语料库) |
| 专业领域语料库 | 聚焦特定领域(医学、法律、科技等) | PubMed(生物医学论文摘要库) | |
| 学习者语料库 | 收集语言学习者的作文或口语,用于错误分析 | HSK动态作文语料库(汉语学习者) | |
| 按时间维度 | 共时语料库 | 同一时间段内的语言数据 | 2020年Twitter语料库 |
| 历时语料库 | 跨时间段的语言数据,用于研究演变 | COHA(美国英语历史语料库,1810-2009) | |
| 按规模 | 小型语料库 | 通常<100万词,用于特定研究 | 某方言调查录音转写库 |
| 大型语料库 | 海量数据(数亿词以上),适合训练AI模型 | Common Crawl(网页爬取数据,PB级) | |
| 按访问权限 | 开放语料库 | 免费公开下载或在线查询 | OpenSubtitles(电影字幕平行语料库) |
| 受限语料库 | 需申请授权或付费使用 | LDC(美国语言数据联盟)发布的商用语料 |
常用语料库的官方网站
资源
| 名称 | 语言/类型 | 官网/获取链接 | 特点 | 访问权限 |
|---|---|---|---|---|
| BCC汉语语料库 | 中文(多领域) | BCC语料库 | 新闻、文学、口语等,可在线检索 | 免费 |
| 国家语委现代汉语语料库 | 中文(书面语) | www.cncorpus.org-官网首页 | 国家权威语料库,侧重现代汉语 | 需注册申请 |
| THUCNews | 中文(新闻分类) | GitHub | 清华大学开源新闻语料,含分类标签 | 免费开源 |
| COCA | 英语(平衡语料) | English-Corpora: COCA | 美国当代英语,覆盖口语、小说、学术等 | 部分免费/需订阅 |
| BNC | 英语(英国) | [bnc] British National Corpus | 英国国家语料库,1亿词规模 | 部分免费 |
| Europarl | 多语言(平行) | Europarl Parallel Corpus | 欧洲议会演讲文本,21种语言对齐 | 免费 |
| Common Crawl | 多语言(网页) | Common Crawl - Open Repository of Web Crawl Data | 海量网页爬取数据,用于训练大模型(如GPT) | 免费 |
| PubMed | 英语(生物医学) | PubMed | 生物医学论文摘要库 | 免费(部分全文需订阅) |
| OpenSubtitles | 多语言(字幕) | Subtitles - download movie and TV Series subtitles | 电影字幕平行语料,适合翻译研究 | 免费 |
| LDC语料库 | 多语言(商用) | Home | Linguistic Data Consortium | 美国语言数据联盟,提供付费专业语料(如电话录音、标注数据) | 付费授权 |
| CLUBCorpus | 中文(网络用语) | GitHub | 包含微博、贴吧等网络文本 | 免费开源 |
| CHILDES | 多语言(儿童语言) | CHILDES | 儿童语言发展研究数据库 | 免费(需注册) |
其他资源平台
| 平台 | 链接 | 特点 |
|---|---|---|
| Kaggle数据集 | Find Open Datasets and Machine Learning Projects | Kaggle | 用户上传的各类NLP数据集(如新闻、社交媒体) |
| Hugging Face | https://huggingface.co/datasets | 提供预处理好的语料库(如IMDb影评、SQuAD问答) |
| Zenodo | Zenodo | 学术机构共享的研究数据(搜索关键词"corpus"或"text dataset") |
NLTK
官网概念:NLTK(Natural Language Toolkit,自然语言工具包)是 Python 中最著名的自然语言处理(NLP)库之一,由 Steven Bird 和 Edward Loper 在宾夕法尼亚大学开发。
用途
| 功能 | 说明 |
|---|---|
| 文本分词 | 将句子拆分成单词(支持英文、中文等)。 |
| 词性标注(POS) | 识别单词的词性(如名词、动词)。 |
| 命名实体识别(NER) | 提取人名、地名、组织名等实体。 |
| 句法分析 | 分析句子结构(如依存句法树)。 |
| 词形还原(Lemmatization) | 将单词还原为基本形式(如 "running" → "run")。 |
| 情感分析 | 判断文本情感倾向(正面/负面)。 |
| 语料库管理 | 内置 50+ 语料库(如古腾堡计划电子书、Twitter 样本)。 |
| 机器学习接口 | 支持文本分类、聚类等任务(需结合 scikit-learn 等库)。 |
安装
# 安装步骤一:使用虚拟环境安装 进入虚拟环境
# 如果忘记怎么创建NLP conda create -n NLP python=3.9 之后使用conda init 即可
activate NLP
# 使用conda 安装nltk 确认是否进入虚拟环境(NLP) D:\project\giteeproject\python-practice\day32>
conda install nltk
# 查看是否安装成功 是否有nltk
conda list
# 安装步骤二:直接使用pip install nltk 安装到现有环境上 记住exit退出虚拟环境哈
pip install nltk使用
CMD命令使用
import nltk
# #下载常用数据集和模型
# nltk.download('popular')
# nltk.download('punkt_tab')
# nltk.download('averaged_perceptron_tagger_eng')
# # 有点慢别下载了
# # nltk.download('reuters')
# from nltk.tokenize import word_tokenize
# from nltk import pos_tag
#
# text = "NLTK makes NLP easy!"
# tokens = word_tokenize(text) # 分词
# tags = pos_tag(tokens) # 词性标注
# print(tags)
# #有的人说你怎么 知道下载那个库的很简单 看console的提示会提示需要安装那个语料库到nltk_data中
# #官网练习
# import nltk
# nltk.download('brown')
# 美国总统就职演讲的这个来测试
from nltk.corpus import inaugural, reuters, brown, stopwords, gutenberg
print(inaugural.words())
# 加载语料库 nltk.corpus.语料库名.fileids() from nltk.corpus import gutenberggutenberg.fileids() 列出语料库中所有文件ID(如['shakespeare-hamlet.txt', ...])。
print(inaugural.fileids())
# nltk.corpus.语料库名.raw(fileid) gutenberg.raw('shakespeare-hamlet.txt') 返回原始文本(字符串格式)。
print(inaugural.raw('2025-Trump.txt'))
# nltk.corpus.语料库名.words(fileid) gutenberg.words('shakespeare-hamlet.txt') 返回单词列表(已分词)。
print(inaugural.words('2025-Trump.txt')) # 输出笑死有特朗普那味儿了 thank you very much ['Thank', 'you', '.', 'Thank', 'you', 'very', 'much', ...]
# nltk.corpus.语料库名.sents(fileid) gutenberg.sents('shakespeare-hamlet.txt') 返回句子列表(每句已分词)。
print(inaugural.sents('2025-Trump.txt')) # [['Thank', 'you', '.'], ['Thank', 'you', 'very', 'much', ',', 'everybody', '.'], ...]
# 内置语料库 nltk.corpus.reuters reuters.fileids() 路透社新闻语料库(适用于文本分类)。这个有点慢别试了
# print(reuters.fileids())
# nltk.corpus.brown brown.categories() 布朗语料库(多领域英语文本,含分类标签)。
print(brown.categories())
# nltk.corpus.stopwords stopwords.words('english') 获取停用词列表(支持多种语言)。
print(stopwords.words('english'))
# 语料库统计 FreqDist() from nltk import FreqDistfd = FreqDist(gutenberg.words())fd.most_common(10) 统计词频并返回最高频词。
from nltk import FreqDist
fd = FreqDist(gutenberg.words())
print(fd.most_common(10))
# nltk.Text() text = nltk.Text(gutenberg.words())text.concordance("love") 生成可交互文本对象,支持上下文查询。
text = nltk.Text(gutenberg.words())
print(text.concordance("love"))
# 自定义语料库 PlaintextCorpusReader from nltk.corpus import PlaintextCorpusReadercorpus = PlaintextCorpusReader("path/to/files", ".*\.txt") 从本地文件夹加载自定义文本语料库。
from nltk.corpus import PlaintextCorpusReader
import os
current_dir = os.getcwd()
corpus = PlaintextCorpusReader(current_dir+"\\day32\\nltk_corpus", r".*\.txt")
print(f"PlaintextCorpusReader fileids:{corpus.fileids()}")
# TaggedCorpusReader from nltk.corpus import TaggedCorpusReadercorpus = TaggedCorpusReader("path", ".*", sep="/") 加载带标签的语料库(如词性标注)。
from nltk.corpus import TaggedCorpusReader
corpus = TaggedCorpusReader(current_dir+"\\day32\\nltk_corpus", ".*", sep="/")
print(f"TaggedCorpusReader fileids:{corpus.fileids()}")spyder使用
# 进入虚拟环境
activate NLP
# 进入spyder
spyder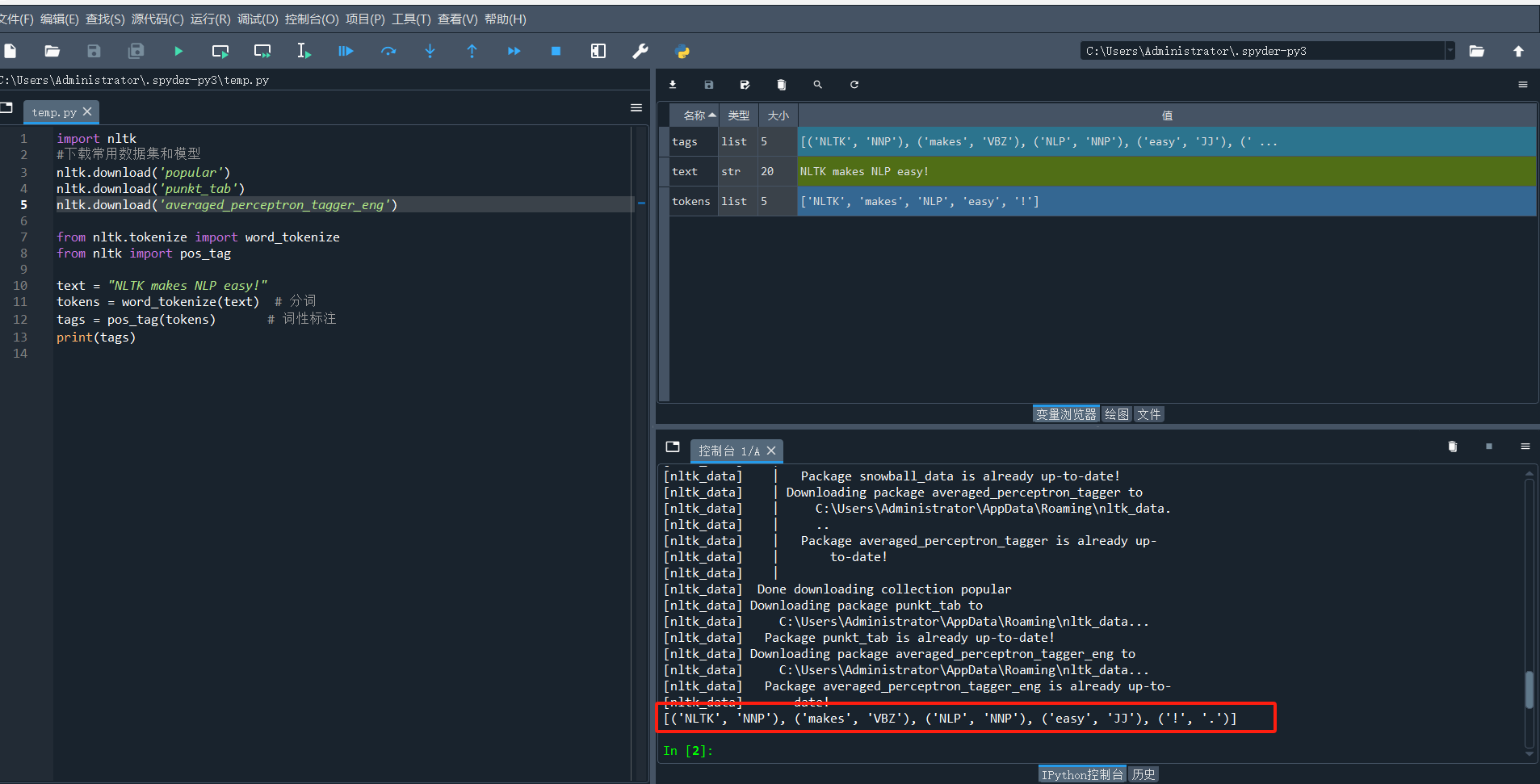
适用场景
-
学术研究:语言学分析、语料库探索。
-
入门学习:理解 NLP 基础任务(如分词、标注)。
-
快速原型开发:小型文本处理项目。
如果需要处理中文或大规模数据,建议结合 jieba(中文分词)、spaCy 或 Hugging Face 使用。
常用命令
| 功能 | 代码示例 | 说明 |
|---|---|---|
| 安装与数据下载 | pip install nltknltk.download('popular') | 安装NLTK并下载常用数据集(首次使用必运行)。 |
| 文本分词 | from nltk.tokenize import word_tokenizetokens = word_tokenize(text) | 将句子拆分为单词列表(英文默认支持,中文需配合jieba)。 |
| 词性标注(POS) | from nltk import pos_tagtags = pos_tag(tokens) | 标注每个单词的词性(如名词NN、动词VB)。 |
| 停用词过滤 | from nltk.corpus import stopwordsstop_words = set(stopwords.words('english')) | 加载英文停用词列表,用于过滤无关词汇(如"the", "a")。 |
| 词形还原 | from nltk.stem import WordNetLemmatizerlemmatizer = WordNetLemmatizer()lemmatizer.lemmatize("running") | 将单词还原为基本形式(输出"run")。 |
| 命名实体识别(NER) | from nltk import ne_chunkentities = ne_chunk(pos_tag(tokens)) | 识别文本中的人名、地名等(需先分词和词性标注)。 |
| 句子分词 | from nltk.tokenize import sent_tokenizesentences = sent_tokenize(text) | 将段落拆分为句子列表。 |
| 频率分布分析 | from nltk import FreqDistfdist = FreqDist(tokens)fdist.most_common(10) | 统计词频,输出最高频的10个词。 |
| 情感分析 | from nltk.sentiment import SentimentIntensityAnalyzersia.polarity_scores(text) | 返回情感极性分数(如{'neg': 0.1, 'pos': 0.8})。 |
| 加载内置语料库 | from nltk.corpus import gutenberggutenberg.fileids() | 访问古腾堡计划电子书等内置语料库。 |
| 功能分类 | 方法/函数 | 代码示例 | 说明 |
|---|---|---|---|
| 加载语料库 | nltk.corpus.语料库名.fileids() | from nltk.corpus import gutenberggutenberg.fileids() | 列出语料库中所有文件ID(如 ['shakespeare-hamlet.txt', ...])。 |
nltk.corpus.语料库名.raw(fileid) | gutenberg.raw('shakespeare-hamlet.txt') | 返回原始文本(字符串格式)。 | |
nltk.corpus.语料库名.words(fileid) | gutenberg.words('shakespeare-hamlet.txt') | 返回单词列表(已分词)。 | |
nltk.corpus.语料库名.sents(fileid) | gutenberg.sents('shakespeare-hamlet.txt') | 返回句子列表(每句已分词)。 | |
| 内置语料库 | nltk.corpus.reuters | reuters.fileids() | 路透社新闻语料库(适用于文本分类)。 |
nltk.corpus.brown | brown.categories() | 布朗语料库(多领域英语文本,含分类标签)。 | |
nltk.corpus.stopwords | stopwords.words('english') | 获取停用词列表(支持多种语言)。 | |
| 语料库统计 | FreqDist() | from nltk import FreqDistfd = FreqDist(gutenberg.words())fd.most_common(10) | 统计词频并返回最高频词。 |
nltk.Text() | text = nltk.Text(gutenberg.words())text.concordance("love") | 生成可交互文本对象,支持上下文查询。 | |
| 自定义语料库 | PlaintextCorpusReader |
| 从本地文件夹加载自定义文本语料库。 |
TaggedCorpusReader |
| 加载带标签的语料库(如词性标注)。 |
常用内置语料库列表
| 语料库名 | 描述 | 加载方式 |
|---|---|---|
gutenberg | 古腾堡计划电子书 | from nltk.corpus import gutenberg |
webtext | 网络论坛和聊天记录 | from nltk.corpus import webtext |
inaugural | 美国总统就职演说 | from nltk.corpus import inaugural |
movie_reviews | 影评数据集(情感分析) | from nltk.corpus import movie_reviews |
wordnet | 英语词汇数据库(同义词等) | from nltk.corpus import wordnet |
jieba
NLTK 的局限:默认支持英文分词(word_tokenize),对中文直接使用会按空格/标点切分,效果差。
安装
# 安装步骤一:使用虚拟环境安装 进入虚拟环境
activate NLP
# 使用conda 安装jieba确认是否进入虚拟环境(NLP) D:\project\giteeproject\python-practice\day32>
conda install jieba
# 查看是否安装成功 是否有jieba
conda list
# 安装步骤二:直接使用pip install jieba安装到现有环境上 记住exit退出虚拟环境哈
pip install jieba使用
# 导入这个不会导入下的子模块的 比如这个jieba.analyse 需要手动导入
import jieba,inspect
import jieba.analyse # 关键步骤!
import jieba.posseg as pseg # 词性标注同理
# 精确模式分词 jieba.lcut() words = jieba.lcut("自然语言处理很有趣") 默认模式,返回分词列表(最常用)。
# 无法通过inspect.signature 或者help(jieba.lcut) 或者print(jieba.lcut.__doc__)
# print(jieba.lcut.__doc__)
# help(jieba.lcut)
# print('lcut函数参数:%s' % inspect.signature(jieba.lcut)) # 输出这样的参数是无法看的(*args, **kwargs)由于使用的事cpython来写的无法查看 只能查看官网https://github.com/fxsjy/jieba
# 实际参数(sentence, cut_all=False, HMM=True, use_paddle=False)
# 参数解释 s str 必填 需要分词的字符串(支持 Unicode)。
# cut_all bool False 控制分词模式: - False:精确模式(默认),最精准的切分,适合文本分析。 - True:全模式,输出所有可能的词语组合,速度快但可能有冗余。
# HMM bool True 是否启用 Hidden Markov Model(隐马尔可夫模型)识别未登录词(如新词、网络用语)。 - True:启用(推荐)。- False:关闭(对已知词典中的词效果更好)。
# use_paddle bool False 是否使用 PaddlePaddle 深度学习框架 加速分词(需安装 paddlepaddle 库)。- True:启用 Paddle 模式,适合长句和新词发现。 - False:禁用(默认)。
print(f"lcut默认模式,返回分词列表(最常用):{jieba.lcut('自然语言处理很有趣')}")
# jieba.cut() for word in jieba.cut("我爱Python", cut_all=False): print(word) 返回生成器,适合逐词处理。
for word in jieba.cut("我爱Python", cut_all=False): print(word)
# 全模式分词 jieba.lcut(..., cut_all=True) words = jieba.lcut("深度学习", cut_all=True) 输出所有可能组合(如“['深度', '学习']”)。
words = jieba.lcut("深度学习", cut_all=True)
print(words)
# 搜索引擎模式 jieba.lcut_for_search() words = jieba.lcut_for_search("北京大学") 对长词再切分(如“北京/大学/北京大学”)。
words = jieba.lcut_for_search("北京大学")
print(words)
# 加载自定义词典 jieba.load_userdict() jieba.load_userdict("jieba/chinese_dict.txt") 每行格式:词语 [词频] [词性](如云计算 5 n)。
print(inspect.signature(jieba.load_userdict))
import jieba
# 加载前的默认分词
text = "李小福是创新办主任,他毕业于清华大学。"
print("加载前:", "/ ".join(jieba.cut(text)))
# 加载用户词典
jieba.load_userdict("./jieba/chinese_dict.txt") # 文件路径
# 加载后的分词效果
print("加载后:", "/ ".join(jieba.cut(text)))
# 测试新词
print("新词测试:", "/ ".join(jieba.cut("八一双鹿男篮和超文本链接")))
# 调整词频 jieba.add_word() jieba.add_word("区块链", freq=100) 强制调整单个词的权重(freq越高越不易被切开)。
jieba.add_word("深度学习", freq=200, tag="n")
jieba.add_word("神经网络")
print("动态添加:", "/ ".join(jieba.cut("深度学习和神经网络很重要")))
# jieba.del_word() jieba.del_word("深度学习") 删除词典中的词。
jieba.del_word("深度学习")
print("删除词典中的词:", "/ ".join(jieba.cut("深度学习和神经网络很重要")))
# 关键词提取 jieba.analyse.extract_tags() keywords = jieba.analyse.extract_tags(text, topK=5, withWeight=True) 基于TF-IDF算法提取关键词(topK指定数量)。
text = "深度学习是人工智能的核心技术,深度学习需要大量数据和算力支持。"
# 提取前3个关键词,带权重
tags = jieba.analyse.extract_tags(text, topK=3, withWeight=True)
for word, weight in tags:
print(f"{word}: {weight:.4f}")
# jieba.analyse.textrank() keywords = jieba.analyse.textrank(text, topK=5) 基于TextRank算法提取关键词。
tags = jieba.analyse.textrank(text, topK=3, withWeight=True)
for word, weight in tags:
print(f"{word}: {weight:.4f}")
# 词性标注 jieba.posseg.lcut() import jieba.posseg as psegpairs = pseg.lcut("我爱编程") 返回(词, 词性)元组列表(如('我', 'r'))。
words = pseg.lcut("清华大学是中国的顶尖高校")
for word, flag in words:
print(f"{word}({flag})", end=" ")
# 并行分词 jieba.enable_parallel() jieba.enable_parallel(4) 启用多线程加速(需提前初始化)。
# POSIX 系统:类 Unix 系统(如 Linux、macOS)支持并行分词。
# 非 POSIX 系统:Windows 默认不支持此功能,因为依赖 multiprocessing 的底层实现差异。
# windows下不支持
# jieba.enable_parallel(2)
# long_text = ["自然语言处理很有趣"] * 100000
# result = jieba.lcut(" ".join(long_text))
# jieba.disable_parallel() # 关闭并行
# print(f"分词数量: {len(result)}")
# 重置词典 jieba.initialize() jieba.initialize() 清空自定义词典,恢复默认状态。
jieba.load_userdict("./jieba/chinese_dict.txt") # 文件路径
jieba.initialize() # 确保新词典生效
print(jieba.lcut("未登录词如:李二狗"))常见命令
| 分类 | 方法/函数 | 代码示例 | 说明 | 参数说明 |
|---|---|---|---|---|
| 基础分词 | jieba.cut() | seg_list = jieba.cut("我爱自然语言处理", cut_all=False, HMM=True) | 返回生成器,需用 list() 或 "/".join() 转换结果。 | - cut_all: 是否全模式(默认False)- HMM: 是否使用HMM模型(默认True) |
jieba.lcut() | seg_list = jieba.lcut("我爱自然语言处理") | 直接返回分词结果的列表(list)。 | 同 cut(),但返回列表。 | |
| 搜索引擎模式 | jieba.cut_for_search() | seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院") | 对长词再切分,适合搜索引擎应用。 | 无特殊参数。 |
jieba.lcut_for_search() | seg_list = jieba.lcut_for_search("小明硕士毕业于中国科学院") | 同 cut_for_search(),但返回列表。 | 无特殊参数。 | |
| 词典管理 | jieba.load_userdict() | jieba.load_userdict("user_dict.txt") | 加载用户自定义词典文件。 | - f: 文件路径或文件对象(UTF-8编码)。 |
jieba.add_word() | jieba.add_word("深度学习", freq=200, tag="n") | 动态添加单个词语到词典。 | - word: 词语- freq: 词频(可选)- tag: 词性(可选)。 | |
jieba.del_word() | jieba.del_word("机器学习") | 从词典中删除词语。 | - word: 要删除的词语。 | |
| 关键词提取 | jieba.analyse.extract_tags() | tags = jieba.analyse.extract_tags(text, topK=20, withWeight=False) | 基于TF-IDF算法提取关键词。 | - topK: 返回关键词数量- withWeight: 是否返回权重- allowPOS: 允许的词性列表。 |
jieba.analyse.textrank() | tags = jieba.analyse.textrank(text, topK=20, withWeight=False) | 基于TextRank算法提取关键词。 | 同 extract_tags()。 | |
| 词性标注 | jieba.posseg.lcut() | words = jieba.posseg.lcut("我爱自然语言处理") | 返回带词性标注的分词列表(如 pair(word='我', flag='r'))。 | 同 lcut(),但每个词附带词性标记。 |
| 并行分词 | jieba.enable_parallel() | jieba.enable_parallel(4) | 启用并行分词(需多核CPU)。 | - num: 使用的CPU核心数(默认全部)。 |
| 初始化/重置 | jieba.initialize() | jieba.initialize() | 重新初始化分词器(加载词典后可能需要调用)。 | 无参数。 |
常用词性标注对照表
| 词性标签 | 含义 | 示例 |
|---|---|---|
n | 名词 | 中国 |
v | 动词 | 学习 |
a | 形容词 | 美丽 |
r | 代词 | 我们 |
m | 数词 | 一百 |
eng | 英文单词 | Python |
代码路径为day32下所有代码

















 51万+
51万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









