






机器人操作的视觉预训练计算机视觉和 NLP 领域预训练的基础模型
我们如何教会机器人操纵物体?最常见的方法是使用领域内的数据从头开始训练端到端模型(见图 1)。深度学习中关于机器人操纵的大多数开创性研究都采用了这种方法 [ 1、2、3 ]。然而,这种方法的数据密集程度过高。Levine 等人 [ 1 ] 的训练过程需要 14 个机械臂执行 800,000 次抓取尝试。Andrychowicz 等人 [ 2 ] 则需要通过模拟获得 100 年的机器人经验。虽然他们的成果令人钦佩,但也很难扩展。

图 1:标准机器人操作训练流程。(来源:Nair 等人[12])
计算机视觉和 NLP 采用了截然不同的方法。CV 和 NLP 不是从头开始训练模型,而是依赖于可重复使用的预训练基础模型。在 CV 中,可以依赖预训练的 ResNet 或 Vision Transformer。如果特定任务需要,可以使用少量特定于领域的数据来微调模型。在 NLP 中,工作流程甚至更简单。只需购买 GPT-4 积分并使用即时工程执行零样本微调 — 几乎不需要任何特定于任务的数据。
我们希望有一个类似的机器人操控基础模型。然后,我们可以简单地下载模型,通过少量领域内演示对其进行微调,并期待获得出色的结果(见图 2)。是什么阻碍了我们?

图 2:新改进的机器人操作训练程序。(来源:Nair 等人[12])
这些基础模型的架构细节已经花了很多笔墨:GPT-4 对 Transformers 的使用,或者 ResNet 对跳过层的使用。这些细节无疑很重要,但没有什么能阻止机器人研究人员使用这些相同的架构——一定有其他东西阻碍了我们。要理解,我们必须退后一步,不去考虑模型本身,而是看看它们所训练的数据。
在 CV 中,原型数据集是 ImageNet [ 4 ],其中包含超过 1400 万张图片 — 只需在此数据集上进行训练,模型就可以发展出复杂的视觉理解能力。如果一家大型科技公司想要获得更好的视觉理解能力,那么从网络上收集图片很容易实现自动化,而且本质上是可扩展的。谷歌内部的 JFT 数据集就是明证,其中包含超过 40 亿张图片 [ 5 ]。
NLP 没有像 ImageNet 这样的原型数据集,但每个大型语言模型都是用类似的数据进行训练的:从网络上抓取的数十亿个标记,例如 Common Crawl、Wikipedia 或 Reddit 数据集。来自网络的文本数据非常丰富,而且相对容易收集。
机器人操作没有互联网规模、领域相关的数据集——这是开发机器人基础模型的关键限制。在这篇博文中,我假设了这样的数据集可能是什么样子。
网络图片
有人可能会问:为什么不直接使用标准的视觉基础模型?机器人的典型输入是来自机器人摄像头的图像数据,那么为什么不直接使用 ResNet-50 [ 6 ] 或 CLIP [ 7 ] 呢?依靠现有的强大模型是一种很好的直觉。Parisi 等人 [ 8 ] 在模拟中尝试了这种方法,其表现明显优于从头开始训练策略。
然而,标准图像基础模型学习到的表示与机器人操作不太匹配。为了理解原因,让我们检查一下机器人在测试时可能会遇到的一些输入图像:



机器人操作是一项非常广泛的任务,因此很难对机器人摄像头数据做出概括。但我们可以做出以下观察:
- 机器人会遇到许多不同的物体
- 机器人需要同时关注图像的语义(图像中的物体是什么?)和空间信息(物体在三维空间中的什么位置?)。
- 前景和背景都很重要。通常,前景会捕获语义,而前景和背景结合起来会捕获空间信息。
现在,我们来看看来自 ImageNet 的几张图像:

来自 ImageNet 的样本图像。
这些图像都包含一个或几个主要物体。背景信息很少,在某些情况下(例如苹果)根本没有背景。图像的重点是传达语义而不是空间信息。这些图像与测试时安装在机器人上的摄像头所看到的分布相差甚远。
虽然这些图像是从 ImageNet 中选出的,但它们也代表了网络上的平均图像。如果您在 Google 图片上输入任意搜索词,典型图像将具有这些特征。因此,像大多数视觉基础模型一样,依赖未经过滤的网络图像作为训练数据,对于机器人操作来说并不适合。
此外,视觉基础模型经过训练后会忽略机器人任务所必需的特征。对于 Vision Transformer 模型,我们可以使用注意力可视化来粗略了解模型认为图像的哪些部分很重要。让我们来看看 CLIP 的一些注意力可视化:

CLIP 的注意力可视化。
我们看到模型学会了忽略背景!这是因为视觉基础模型通常以分类损失为基准(并且经常以此为训练)。为了在分类上表现良好,忽略背景是有意义的,因为它与特定任务无关。然而,对于机器人操作任务来说,这是一个严重的错误。
因此,不仅训练数据远远偏离分布,而且典型的视觉基础模型在构建图像表示时会丢弃基本信息。请注意,可以通过端到端微调基础模型(而不是让模型冻结)来恢复信息。然而,这需要大量计算和数据,此时我们正在失去依赖现有基础模型所获得的优势。
有人可能会说,如果我们想要可推广的模型,我们就不应该太担心数据质量,而应该直接扩大规模。然而,有令人信服的经验证据表明,分布不匹配对机器人操作确实很重要。Majumdar 等人 [ 9 ] 训练视觉表征模型的数据量比 CLIP 少 70 倍,但在他们测试的所有 7 个基准测试中,其表现都远远优于 CLIP。他们之所以能做到这一点,是因为他们使用了以自我为中心的视频数据,这更适合机器人操作任务。(我将在后面的博客文章中详细介绍这种类型的数据。)
需要明确的是,在网络图像上训练的视觉基础模型所提供的表征对于机器人操控仍然有帮助——以它们为起点比从头开始训练能带来更好的结果 [ 8,10 ]。但要在机器人操控方面取得真正令人信服的结果,还需要其他数据源。
视频数据
图像忽略了机器人操作任务的一个重要部分:顺序决策。在机器人操作中,机器人不会收集单个图像,而是视频数据,即随时间变化的图像序列。由于图像随时间发生,因此未来的图像取决于过去的图像。此外,未来的图像取决于机器人的动作,因为机器人会影响其环境。依赖视频数据而不是图像数据意味着我们的训练数据将更好地匹配测试时的数据。
一个标准的视频数据集是 Kinetics [ 11 ],它由 YouTube 上人类采取行动(演奏乐器、握手、投掷标枪)的视频组成。Kinetics 的另一个优势是它描述的是人类的动作,而不是静态的环境。由于人类动作与机器人动作相似,机器人可以了解其动作如何影响其环境,这是机器人操控问题的另一个关键部分。

从 Kinetics 数据集中抽取帧样本 [ 11 ]
请注意,为了捕捉视频数据的连续性,你必须使用适当的训练目标,例如时间对比学习 [ 12 ]。与图像重建或分类等标准视觉目标相比,该目标的研究较少,理解程度也不高。出于这个原因,一些机器人论文将视频分成独立的帧,然后应用标准 CV 目标 [ [13 ]。虽然 Radosavovic 等人 13 ]的理论基础不如时间对比学习,但他们用这种方法取得了有竞争力的结果。
自我中心视频
请注意,在机器人操纵装置中,摄像头安装在机器人上。我们可以利用这一事实,使用人类的第一人称镜头或以自我为中心的视频数据——现在我们的训练数据与测试时的数据更加接近!
除了第一人称视角外,以自我为中心的视频数据通常包含人手与物体的交互。机器人操纵装置通常有机械手,或者至少有受人手启发的附属物。因此,这种数据对于教导机器人与环境交互特别有用。
最广泛使用的以自我为中心的数据集是 Ego4D [ 14 ],但也有更具体的数据集。例如,Epic Kitchens [ 15 ] 专门关注人类在厨房中的行为。

来自 Ego4D 数据集的样本帧 [ 14 ]
Ego4D 目前在机器人视觉表现方面得到广泛应用。[ 9、12、13 ] 。不幸的是,自我中心数据不像通用视频那样容易扩展。网络上仍有相当数量的自我中心数据,但远少于通用视频。Kinetics 纯粹是通过抓取 YouTube 数据创建的,而 Ego4D 则是通过雇佣佩戴面部摄像头的人创建的。
机器人视频
使数据完全分布的最后一步是将我们自己限制在机器人实际观察到的摄像机数据上。
有许多数据集采用了这种方法,最著名的是 Bridge 数据集 [ 16 ]。

来自 Bridge 数据集的样本帧 [ 16 ]
然而,这比以自我为中心的人类视频更不可扩展:收集更多此类数据需要使用机械臂和研究生进行实时数据收集。Bridge 数据集仅包含 7,200 个演示 — 与标准机器学习数据集相比,这只是小数目。
讨论
到目前为止,对于最好使用哪种数据源,研究界还没有达成共识。有大量的机器人学论文使用不同的预训练视觉表示模型,但无法对它们进行比较,因为这种选择只是整个机器人操作堆栈的一个组成部分。机器人学论文还必须考虑:
- 网络架构(ResNet、ViT、EfficientNet、使用 FiLM 层)
- 硬件(Franka Emika Panda、WidowX、UR10)
- 策略学习方法(行为克隆、强化学习、视觉奖励函数)
- 任务规范(自然语言、独热任务编码)
由于还有许多其他活动部件,因此不可能将预训练的视觉表示的贡献分离出来。一些论文提供了消融,但没有一篇是全面的。迄今为止最好的消融是由 Majumdar 等人提供的。[ 9 ],他们使用自我中心数据(Ego4D 和 5 个较小的自我中心数据集)和网络图像数据(ImageNet)。然而,在他们进行的所有实验中,自我中心数据占数据的 75% 以上,因此很难得出任何有意义的结论。
最终,我考虑的所有预训练数据(从网络图像到机器人视频)都可以改善机器人操作的结果。我怀疑,这些数据源中的任何一个,只要由大型科技公司大规模扩展,都可以实现最先进的结果。更好的问题是“应该扩展哪个数据源”?我最好的猜测是,在线视频数据在可扩展性和领域相关性之间取得了良好的平衡——但这需要通过经验来确定。
几点说明:
- 据我所知,在使用未过滤的在线视频进行机器人操控方面存在研究空白。我找到了多篇使用网络图像数据 [ 8 , 10 ]、自我中心数据 [ 12 , 13 , 17 ] 和机器人视频数据 [ 18 , 19 ] 的机器人操控论文,但没有一篇论文依赖于更通用的视频数据集,如 Kinetics。
- 大多数最新的机器人视觉表示学习论文都依赖于 Ego4D 数据集。这是有道理的,因为它是一个大型、精心策划的数据集,包含与领域相关的数据。很难确定对该数据集的依赖是否表明了自我中心数据的优越性,或者 Ego4D 的质量尤其如此。
- Ego4D 是通过雇佣佩戴面部摄像头的人创建的,因此他们的方法很难扩展。然而,YouTube 和其他地方有大量以自我为中心的数据尚未被利用。这将是扩展 Ego4D 或构建单独的更大数据集的一种有前途的方法。
- 最终,最好的选择可能是使用多种数据模式的组合。Majumdar 等人 [ 9 ] 和 Radosavovic 等人 [ 13 ] 都使用了自我中心数据和网络图像的组合。
实用建议
如果机器人研究人员想要获得强大的视觉表现,他们应该使用什么?
我的建议是 Meta 的开源 VC-1 模型[ 9 ]。该模型是一个使用图像蒙版自动编码训练的 Vision Transformer (ViT-B)。(这意味着输入模型的任何视频数据都会转换为单独的帧)。他们的数据由 6 个以自我为中心的数据集和整个 ImageNet 组成。
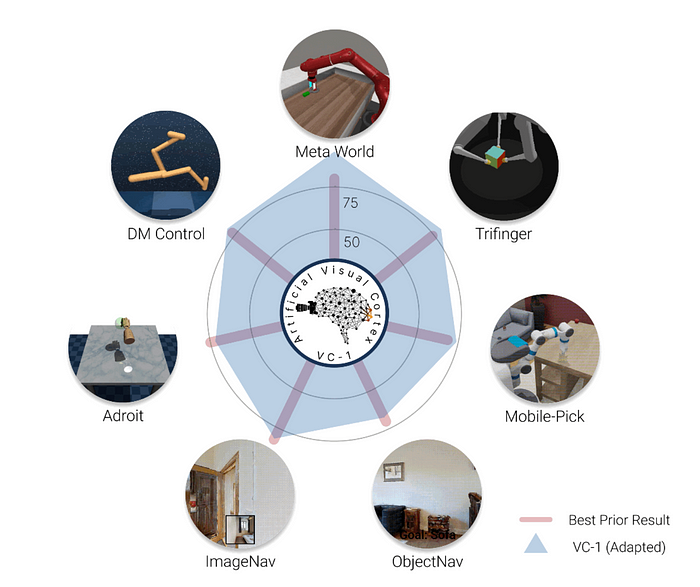
VC-1 在各种基准测试中的表现可视化。(来源)
他们在模拟中对 7 种不同的标准机器人操作任务中的各种基线进行了 VC-1 评估,每个任务都使用固定的策略学习方法。虽然 R3M [ 12 ] 和 MVP [ 13 ] 等其他模型在特定任务上表现更好,但 VC-1 的全面表现最佳。
M [ 12 ] 和 MVP [ 13 ] 等其他模型在特定任务上表现更好,但 VC-1 的全面表现最佳。
我最强烈的建议是,机器人研究人员应该使用某种形式的视觉预训练,而不是什么都不做。许多著名的机器人操作论文都没有使用视觉预训练 [ 1 , 3 , 20 ]。虽然机器人的视觉预训练问题还远未解决,但仍有各种模型的表现比没有好得多。
博客原文:专业人工智能社区















 4005
4005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









