






参数是如何更新的
二层模型
线性回归:
我们有
n
n
n个样本,每个样本有
k
k
k个属性即
k
k
k元。
对于第
j
j
j个样本的所有属性
x
i
x_i
xi,其组织方式假设是:
A j = A j ( x i ; w i , b ) = ∑ i = 0 k ( w i ∗ x i ) + b A_j=A_j(x_i;w_i,b)= \sum_{i=0}^k(w_i*x_i)+b Aj=Aj(xi;wi,b)=∑i=0k(wi∗xi)+b;
矩阵写法:
A
j
=
W
T
X
A_j =\mathbf {W^T}\mathbf {X}
Aj=WTX;
A
j
A_j
Aj并不是矩阵,而是一个标量。
我们称
A
j
A_j
Aj为属性函数(仅笔者这么称呼)。
属性函数还有其他形式吗?
- MaxPooling层:从 l l l个属性值,选择最大的一个, 0 ≦ l ≦ k 0\leqq l\leqq k 0≦l≦k;
- MeanPooling层:对 l l l个属性值求平均, 0 ≦ l ≦ k 0\leqq l\leqq k 0≦l≦k;
- Dropout层:随机丢掉/保留一部分属性;
- 全连接层: A j = A j ( x i ; w i , b ) = ∑ i = 0 l ( w i ∗ x i ) + b A_j=A_j(x_i;w_i,b)= \sum_{i=0}^l(w_i*x_i)+b Aj=Aj(xi;wi,b)=∑i=0l(wi∗xi)+b, 0 ≦ l ≦ k 0\leqq l\leqq k 0≦l≦k;可以看清全连接的本质了!
- 卷积层: A j = A j ( x i ; w i , b ) = ∑ i = 0 l ( w i ∗ x i ) + b A_j=A_j(x_i;w_i,b)= \sum_{i=0}^l(w_i*x_i)+b Aj=Aj(xi;wi,b)=∑i=0l(wi∗xi)+b, 0 ≦ l ≦ k 0\leqq l\leqq k 0≦l≦k;可以看清卷积的本质了!
当k=1,即一元线性回归;
当k>1,即多元线性回归。
我们的假设函数是线性的,即
H
j
(
i
n
p
u
t
)
=
a
∗
i
n
p
u
t
+
v
H_j(input)=a*input+v
Hj(input)=a∗input+v
1、这里的
i
n
p
u
t
input
input是什么?
i
n
p
u
t
input
input就是
A
j
A_j
Aj
2、
a
a
a和
v
v
v又是什么?假设函数的参数。
H
j
=
H
(
A
j
)
=
a
∗
(
∑
i
=
0
k
(
w
i
∗
x
i
)
+
b
)
+
v
H_j=H(A_j)=a* \bigl (\sum_{i=0}^k(w_i*x_i)+b\bigr)+v
Hj=H(Aj)=a∗(∑i=0k(wi∗xi)+b)+v
=
∑
i
=
0
k
(
a
w
i
∗
x
i
)
+
(
a
b
+
v
)
\qquad\qquad\quad=\sum_{i=0}^k(aw_i*x_i)+(ab+v)
=∑i=0k(awi∗xi)+(ab+v)
令
a
∗
w
i
=
w
i
a*w_i=w_i
a∗wi=wi,
a
b
+
v
=
b
ab+v=b
ab+v=b,或理解成
a
=
v
=
1
a=v=1
a=v=1,则有:
H
j
=
∑
i
=
0
k
(
w
i
∗
x
i
)
+
b
H_j=\sum_{i=0}^k(w_i*x_i)+b
Hj=∑i=0k(wi∗xi)+b
或者假设函数就是
H
(
i
n
p
u
t
)
=
i
n
p
u
t
H(input)=input
H(input)=input
可以看到假设函数与属性函数是一模一样的。虽然如此,我们要明白“一元线性”中“一元”和“线性”的含义,这里的线性不是指属性函数是线性的(虽然属性函数是线性的),而是指假设函数是线性的。
还有哪里我们对属性函数采用线性操作?
在神经网络中,
A
j
A_j
Aj为卷积层或全连接层的时候,后面会有激活函数,激活函数一般我们会选择非线性的,比如Sigmoid、ReLU,最后一层全连接多分类情况激活函数选择Softmax,二分类情况选择Sigmoid。而
A
j
A_j
Aj为Pooling层或Dropout层的时候,一般都没有显式指出激活函数,但是不代表没有,而是其激活函数
H
j
=
H
(
A
j
)
=
A
j
H_j=H(A_j)=A_j
Hj=H(Aj)=Aj,所以这里就是线性的。
假设函数=逻辑回归中的判别函数Sigmoid=神经网络中隐层激活函数=神经网络中输出层的softmax函数,他们的本质上都是一样的。所以下文中,激活函数也用 H H H来表示。
损失函数/目标函数:
这里使用均方误差MSE为例:
L
=
1
n
∑
j
=
0
n
(
H
j
−
y
j
)
2
L=\frac{1}{n}\sum_{j=0}^n(H_j-y_j)^2
L=n1∑j=0n(Hj−yj)2;
=
1
n
[
(
H
0
−
y
0
)
2
+
.
.
.
+
(
H
n
−
y
n
)
2
]
\quad=\frac{1}{n}[(H_0-y_0)^2+...+(H_n-y_n)^2]
=n1[(H0−y0)2+...+(Hn−yn)2];
以一元线性回归为例
x
j
x_j
xj是指第
j
j
j个样本的
x
x
x属性,
n
n
n表示样本数:
L
=
1
n
[
(
(
w
∗
x
0
+
b
)
−
y
0
)
2
+
.
.
.
+
(
(
w
∗
x
n
+
b
)
−
y
n
)
2
]
L=\frac{1}{n}[((w*x_0+b)-y_0)^2+...+((w*x_n+b)-y_n)^2]
L=n1[((w∗x0+b)−y0)2+...+((w∗xn+b)−yn)2];
如果是3元,
x
j
i
x_{ji}
xji表示第
j
j
j个样本的第
i
i
i个属性,损失函数是这样的:
L
=
1
n
[
(
(
w
0
∗
x
00
+
w
1
∗
x
01
+
w
2
∗
x
02
+
b
)
−
y
0
)
2
+
.
.
.
+
(
(
w
0
∗
x
n
0
+
w
1
∗
x
n
1
+
w
2
∗
x
n
2
+
b
)
−
y
n
)
2
]
L=\frac{1}{n}[((w0*x_{00}+w1*x_{01}+w2*x_{02}+b)-y_0)^2+...+((w0*x_{n0}+w1*x_{n1}+w2*x_{n2}+b)-y_n)^2]
L=n1[((w0∗x00+w1∗x01+w2∗x02+b)−y0)2+...+((w0∗xn0+w1∗xn1+w2∗xn2+b)−yn)2];
也可以在 L L L上乘以 1 2 \frac{1}{2} 21简化求导。
可见,如果我们对 w i w_i wi求偏导会有求和的过程 ∑ \sum ∑。
损失函数求导:
可以看出
L
L
L是复合函数,我们可以使用链式法则(复合函数求导利器)进行求导:
∂
L
∂
w
i
=
2
n
∑
j
=
0
n
(
∂
L
∂
H
(
w
i
)
∗
∂
H
j
∂
A
j
∗
∂
A
j
∂
w
i
)
\frac{ \partial L}{\partial w_i}=\frac{2}{n}\sum_{j=0}^n\Bigl(\frac{ \partial L}{\partial H(w_i)}*\frac{ \partial H_j}{\partial A_j}*\frac{ \partial A_j}{\partial w_i}\Bigr)
∂wi∂L=n2∑j=0n(∂H(wi)∂L∗∂Aj∂Hj∗∂wi∂Aj)
其中:
∂
L
∂
H
j
=
H
j
−
y
j
\frac{ \partial L}{\partial H_j}=H_j-y_j
∂Hj∂L=Hj−yj
∂ H j ∂ A j = a \frac{ \partial H_j}{\partial A_j}=a ∂Aj∂Hj=a
∂ A j ∂ w i = x j i \frac{ \partial A_j}{\partial w_i}=x_{ji} ∂wi∂Aj=xji
所以 ∂ L ∂ w i = 2 n ∑ j = 0 n ( ( H j − y j ) ∗ a ∗ x j i ) \frac{ \partial L}{\partial w_i}=\frac{2}{n}\sum_{j=0}^n\Bigl((H_j-y_j)*a*x_{ji}\Bigr) ∂wi∂L=n2∑j=0n((Hj−yj)∗a∗xji)
我们不妨让a=v=1,则: ∂ L ∂ w i = 2 n ∑ j = 0 n ( ( H j − y j ) ∗ x j i ) \frac{ \partial L}{\partial w_i}=\frac{2}{n}\sum_{j=0}^n\Bigl((H_j-y_j)*x_{ji}\Bigr) ∂wi∂L=n2∑j=0n((Hj−yj)∗xji)
同理: ∂ L ∂ b = 2 n ∑ j = 0 n ( ( H j − y j ) ∗ 1 ) \frac{ \partial L}{\partial b}=\frac{2}{n}\sum_{j=0}^n\Bigl((H_j-y_j)*1\Bigr) ∂b∂L=n2∑j=0n((Hj−yj)∗1)
使用梯度下降进行参数更新:
w
i
=
w
i
+
η
∗
∂
L
∂
w
i
w_i=w_i+η*\frac{ \partial L}{\partial w_i}
wi=wi+η∗∂wi∂L
=
w
i
+
η
∗
2
n
∑
j
=
0
n
(
(
H
j
−
y
j
)
∗
a
∗
x
j
i
)
\quad=w_i+η*\frac{2}{n}\sum_{j=0}^n\Bigl((H_j-y_j)*a*x_{ji}\Bigr)
=wi+η∗n2∑j=0n((Hj−yj)∗a∗xji)
b
=
b
+
η
∗
∂
L
∂
b
b=b+η*\frac{ \partial L}{\partial b}
b=b+η∗∂b∂L
=
b
+
η
∗
2
n
∑
j
=
0
n
(
(
H
j
−
y
j
)
∗
1
)
\quad=b+η*\frac{2}{n}\sum_{j=0}^n\Bigl((H_j-y_j)*1\Bigr)
=b+η∗n2∑j=0n((Hj−yj)∗1)
注意观察上面参数更新的式子,由3部分组成: η η η、 H j − y j H_j-y_j Hj−yj和 x j i x_{ji} xji,其中 η η η是超参数学习率, R e s = H j − y j Res=H_j-y_j Res=Hj−yj称为残差,即假设函数的输出与真实样本标记之差, x j i x_{ji} xji是样本 j j j的第 i i i个特征值。
如果
n
=
1
n=1
n=1,就是随机梯度下降法SGD;
如果
n
=
n=
n=所有样本数,就是批梯度下降法BGD;
如果
1
<
n
<
1<n<
1<n<所有样本数,就是小批梯度下降法MBGD;
####################################################
逻辑回归
属性函数
A
j
=
∑
i
=
0
k
(
w
i
∗
x
i
)
+
b
A_j = \sum_{i=0}^k(w_i*x_i)+b
Aj=∑i=0k(wi∗xi)+b
假设函数 H j = 1 1 + e − A j H_j=\frac{1}{1+e^{-A_j }} Hj=1+e−Aj1
损失函数:交叉熵损失函数
极大似然估计(Maximum Likelihood Estimation,MLE)角度理解:
M
L
E
=
1
n
∏
j
=
0
n
(
H
j
y
j
∗
(
1
−
H
j
)
1
−
y
j
)
MLE=\frac{1}{n}\prod_{j=0}^n\biggl(H_j^{y_j}*(1-H_j)^{1-y_j}\biggr)
MLE=n1∏j=0n(Hjyj∗(1−Hj)1−yj)
n
n
n表示样本数;
对MLE做等价变形:两边同时取对数
L
=
1
n
∑
j
=
0
n
(
y
j
∗
l
o
g
(
H
j
)
+
(
1
−
y
j
)
∗
l
o
g
(
1
−
H
j
)
)
L=\frac{1}{n}\sum_{j=0}^n\biggl(y_j*log(H_j)+(1-y_j)*log(1-H_j)\biggr)
L=n1∑j=0n(yj∗log(Hj)+(1−yj)∗log(1−Hj))
损失函数
L
L
L越大,证明我们得到的
w
i
,
b
w_i,b
wi,b越好,我们习惯损失函数越小越好,所以对右边取负:
L
=
−
1
n
∑
j
=
0
n
(
y
j
∗
l
o
g
(
H
j
)
+
(
1
−
y
j
)
∗
l
o
g
(
1
−
H
j
)
)
L=-\frac{1}{n}\sum_{j=0}^n\biggl(y_j*log(H_j)+(1-y_j)*log(1-H_j)\biggr)
L=−n1∑j=0n(yj∗log(Hj)+(1−yj)∗log(1−Hj))
损失函数求导:
对参数
w
i
w_i
wi求偏导:
∂
L
∂
w
i
=
−
1
n
∑
j
=
0
n
(
∂
L
∂
H
j
∗
∂
H
j
∂
A
j
∗
∂
A
j
∂
w
i
)
\frac{ \partial L}{\partial w_i}=-\frac{1}{n}\sum_{j=0}^n\Bigl(\frac{ \partial L}{\partial H_j}*\frac{ \partial H_j}{\partial A_j}*\frac{ \partial A_j}{\partial w_i}\Bigr)
∂wi∂L=−n1∑j=0n(∂Hj∂L∗∂Aj∂Hj∗∂wi∂Aj)
其中:
∂ L ∂ H j = y j ∗ 1 H j + ( 1 − y j ) ∗ 1 1 − H j ∗ ( − 1 ) \frac{ \partial L}{\partial H_j}=y_j*\frac{1}{H_j}+(1-y_j)*\frac{1}{1-H_j}*(-1) ∂Hj∂L=yj∗Hj1+(1−yj)∗1−Hj1∗(−1)
∂ H j ∂ A j = H j ∗ ( 1 − H j ) \frac{ \partial H_j}{\partial A_j}=H_j*(1-H_j) ∂Aj∂Hj=Hj∗(1−Hj)
∂ A j ∂ w i = x j i \frac{ \partial A_j}{\partial w_i}=x_{ji} ∂wi∂Aj=xji
所以:
∂
L
∂
w
i
=
−
1
n
∑
j
=
0
n
(
(
y
j
∗
1
H
j
−
(
1
−
y
j
)
∗
1
1
−
H
j
)
∗
H
j
∗
(
1
−
H
)
∗
x
j
i
)
\frac{ \partial L}{\partial w_{i}}=-\frac{1}{n}\sum_{j=0}^n\Bigl((y_j*\frac{1}{H_j}-(1-y_j)*\frac{1}{1-H_j})*H_j*(1-H)*x_{ji}\Bigr)
∂wi∂L=−n1∑j=0n((yj∗Hj1−(1−yj)∗1−Hj1)∗Hj∗(1−H)∗xji)
=
−
1
n
∑
j
=
0
n
(
(
y
j
∗
(
1
−
H
j
)
−
(
1
−
y
j
)
∗
H
j
)
∗
x
j
i
)
\qquad=-\frac{1}{n}\sum_{j=0}^n\Bigl((y_j*(1-H_j)-(1-y_j)*H_j)*x_{ji}\Bigr)
=−n1∑j=0n((yj∗(1−Hj)−(1−yj)∗Hj)∗xji)
=
1
n
∑
j
=
0
n
(
(
H
j
−
y
j
)
∗
x
j
i
)
\qquad=\frac{1}{n}\sum_{j=0}^n\Bigl((H_j-y_j)*x_{ji}\Bigr)
=n1∑j=0n((Hj−yj)∗xji)
同理: ∂ L ∂ b = 1 n ∑ j = 0 n ( ( H j − y j ) ∗ 1 ) \frac{ \partial L}{\partial b}=\frac{1}{n}\sum_{j=0}^n\Bigl((H_j-y_j)*1\Bigr) ∂b∂L=n1∑j=0n((Hj−yj)∗1)
可以看到最后的结果和线性回归使用均分误差作为损失函数求导得到的结果是一样的,区别在于假设函数 H H H不一样了。
使用梯度下降进行变量更新不再累述,同样,n决定了使用的是SGB、BGD还是MBGD。
多层模型
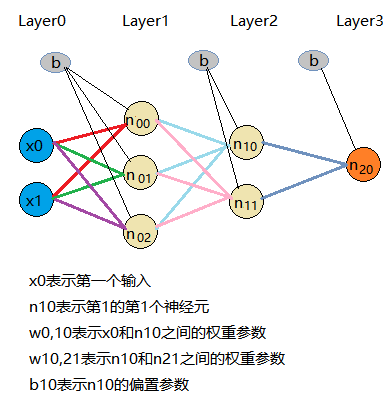
多层网络中,每一层的输出都是特征/属性/元。有最原始的
x
0
x_0
x0、
x
1
x_1
x1等到各个神经元的输出(神经元的输出就是神经元对应激活函数的输出)都是属性。既然是属性,那么其组织方式都是:
A
l
,
s
=
∑
i
=
0
k
(
w
i
s
∗
x
i
)
+
b
l
,
s
A_{l,s}= \sum_{i=0}^k(w_{is}*x_i)+b_{l,s}
Al,s=∑i=0k(wis∗xi)+bl,s;
A
l
,
s
A_{l,s}
Al,s表示对应第
l
l
l层的第
s
s
s个神经元的输入,
l
≥
0
l\ge0
l≥0,
s
≥
0
s\ge0
s≥0;
那么第
l
−
1
l-1
l−1层有
k
k
k个输出(即有
k
k
k个属性到下一层)。
w
i
s
w_{is}
wis表示第
l
−
1
l-1
l−1层的第
i
i
i个神经元与第
l
l
l层的第
s
s
s个神经元之间的权重参数;
激活函数:
H
l
,
s
=
1
1
+
e
−
A
l
,
s
H_{l,s}=\frac{1}{1+e^{-A_{l,s}}}
Hl,s=1+e−Al,s1
H
l
,
s
H_{l,s}
Hl,s表示对应第
l
l
l层的第
s
s
s个神经元的输出,
l
≥
0
l\ge0
l≥0,
s
≥
0
s\ge0
s≥0;
输入样本
j
j
j,其有
k
=
2
k=2
k=2个属性,那么网络是怎么传播的?
神经元
n
10
n_{10}
n10
输入:
A
1
,
0
=
w
00
,
10
∗
x
0
+
w
01
,
10
∗
x
1
+
b
1
,
0
A_{1,0}=w_{00,10}*x_0+w_{01,10}*x_1+b_{1,0}
A1,0=w00,10∗x0+w01,10∗x1+b1,0
输出:
H
1
,
0
=
H
(
A
1
,
0
)
=
1
1
+
e
−
A
1
,
0
H_{1,0}=H(A_{1,0})=\frac{1}{1+e^{-A_{1,0}}}
H1,0=H(A1,0)=1+e−A1,01
神经元
n
11
n_{11}
n11的输入与输出略;
神经元
n
12
n_{12}
n12的输入与输出略;
神经元
n
20
n_{20}
n20的输入:
A
2
,
0
=
w
10
,
20
∗
H
1
,
0
+
w
11
,
20
∗
H
1
,
1
+
w
12
,
20
∗
H
1
,
2
+
b
2
,
0
A_{2,0}=w_{10,20}*H_{1,0}+w_{11,20}*H_{1,1}+w_{12,20}*H_{1,2}+b_{2,0}
A2,0=w10,20∗H1,0+w11,20∗H1,1+w12,20∗H1,2+b2,0
神经元
n
20
n_{20}
n20的输出:
H
2
,
0
=
H
(
A
2
,
0
)
H_{2,0}=H(A_{2,0})
H2,0=H(A2,0)
神经元n21的输入与输出略。
神经元n30的输入:
A
3
,
0
=
w
20
,
30
∗
H
2
,
0
+
w
21
,
30
∗
H
2
,
1
+
b
3
,
0
A_{3,0}=w_{20,30}*H_{2,0}+w_{21,30}*H_{2,1}+b_{3,0}
A3,0=w20,30∗H2,0+w21,30∗H2,1+b3,0
神经元n30的输出:
H
3
,
0
=
H
(
A
3
,
0
)
H_{3,0}=H(A_{3,0})
H3,0=H(A3,0)
上面就是前向/前馈传播(Feed-Forward)。
损失函数,以交叉熵损失函数为例:
L
=
−
1
n
∑
j
=
0
n
(
y
j
∗
l
o
g
(
H
o
)
+
(
1
−
y
j
)
∗
l
o
g
(
1
−
H
o
)
)
L=-\frac{1}{n}\sum_{j=0}^n\biggl(y_j*log(H_o)+(1-y_j)*log(1-H_o)\biggr)
L=−n1∑j=0n(yj∗log(Ho)+(1−yj)∗log(1−Ho))
n n n表示样本数; H o H_o Ho表示样本 j j j的输出层的输出;如果输出层有多个神经元,如多分类任务中最后一层的激活函数使用softmax,是将特征值限定在[0,1]之间,这样 H o H_o Ho和 y j y_j yj都是向量。
要更新隐层与输出层之间的参数,可以求偏导如下:
∂
L
∂
w
o
=
−
1
n
∑
j
=
0
n
(
∂
L
∂
H
o
∗
∂
H
o
∂
A
o
∗
∂
A
o
∂
w
o
)
\frac{ \partial L}{\partial w_o}=-\frac{1}{n}\sum_{j=0}^n\Bigl(\frac{ \partial L}{\partial H_o}*\frac{ \partial H_o}{\partial A_o}*\frac{ \partial A_o}{\partial w_o}\Bigr)
∂wo∂L=−n1∑j=0n(∂Ho∂L∗∂Ao∂Ho∗∂wo∂Ao)
隐层到输出层之间的参数的更新比较好理解,和两层模型的参数更新一样。那么我们如果更新隐层之间以及输出层和隐层之间的参数呢?之所以有这样的难题是因为损失函数就是作用在输出层上的即 H o − y j H_o-y_j Ho−yj才有意义。可是隐层上又不能使用损失函数 L L L,那么怎么求导并更新参数呢?如果我们把目给聚集在链式求导公式上:
∂ L ∂ H o ∗ ∂ H o ∂ A o ∗ ∂ A o ∂ w o \frac{ \partial L}{\partial H_o}*\frac{ \partial H_o}{\partial A_o}*\frac{ \partial A_o}{\partial w_o} ∂Ho∂L∗∂Ao∂Ho∗∂wo∂Ao
我们可以把上面的公式拆分成3部分:
∂ L ∂ H o \frac{ \partial L}{\partial H_o} ∂Ho∂L 即损失函数对输出函数(假设函数/激活函数)的求导
∂ H o ∂ A o \frac{ \partial H_o}{\partial A_o} ∂Ao∂Ho 即输出函数(假设函数/激活函数)对输入函数(属性函数)的求导
∂ A o ∂ w o \frac{ \partial A_o}{\partial w_o} ∂wo∂Ao 即输入函数(属性函数)对参数的求导
上面3个部分中,只有第1个部分使用了损失函数
L
L
L。第2部分我们可以改成
∂
H
l
∂
A
l
\frac{ \partial H_l}{\partial A_l}
∂Al∂Hl 即l层的输出函数对输入函数的求导,第3部分我们可以改成
∂
A
l
∂
w
l
\frac{ \partial A_l}{\partial w_l}
∂wl∂Al即l层的输入函数对参数的求导。重点看第1部分:
σ
o
=
∂
L
∂
H
o
σ_o = \frac{ \partial L}{\partial H_o}
σo=∂Ho∂L
如果是均方误差损失函数:
σ
=
H
−
y
σ =H-y
σ=H−y
如果是交叉熵损失函数:
σ
=
y
∗
1
H
−
(
1
−
y
)
∗
1
1
−
H
σ =y*\frac{1}{H}-(1-y)*\frac{1}{1-H}
σ=y∗H1−(1−y)∗1−H1
可以看出
σ
σ
σ代表的就是误差,所以反向/逆传播指的就是误差逆传播,即传播的是
σ
σ
σ。
那么误差是怎么逆传播的?
误差的产生也不都是最后一层造成的,前面各层也会后贡献。所以我们要按照各神经元的权重反馈给各个神经元,那么第
l
l
l层的第
s
s
s个神经元的误差:
σ l , s = ∑ i = 0 k ( w i s ∗ σ l + 1 , i ) + b l , s σ_{l,s}= \sum_{i=0}^k(w_{is}*σ_{l+1,i})+b_{l,s} σl,s=∑i=0k(wis∗σl+1,i)+bl,s
其中 w i s w_{is} wis表示第 l + 1 l+1 l+1层的第 i i i个神经元与第 l l l层的第 s s s个神经元之间的权重;b_{l,s}第 l l l层的第 s s s个神经元的偏置;σ_{l+1,i}表示第 l + 1 l+1 l+1层的第 i i i个神经元的误差,显然这里 l l l不为输出层;
对比误差函数 σ l , s σ_{l,s} σl,s和属性函数 A l , s = ∑ i = 0 k ( w i s ∗ x i ) + b l , s A_{l,s}=\sum_{i=0}^k(w_{is}*x_i)+b_{l,s} Al,s=∑i=0k(wis∗xi)+bl,s;可以看出两者是相同的,只是误差函数是对 l + 1 l+1 l+1层的误差进行加权求和,而属性函数是对 l − 1 l-1 l−1层的属性/特征进行加权求和。
至此,我们就得到:
第
l
−
1
l-1
l−1层的第
i
i
i个神经元与第
l
l
l层的第
s
s
s个神经元之间的权重参数
w
i
s
w_{is}
wis的更新公式:
注意:
我们求
σ
l
,
s
σ_{l,s}
σl,s的时候使用的是第
l
l
l层和第
l
+
1
l+1
l+1层之间的权重参数;更新的参数是第
l
−
1
l-1
l−1层和第
l
l
l层之间的权重参数。
w i s = w i s + η ∗ ( σ l , s ∗ ∂ H l , s ∂ A l , s ∗ ∂ A l , s ∂ w i s ) w_{is}=w_{is}+η*\Bigl(σ_{l,s}*\frac{ \partial H_{l,s}}{\partial A_{l,s}}*\frac{ \partial A_{l,s}}{\partial w_{is}}\Bigr) wis=wis+η∗(σl,s∗∂Al,s∂Hl,s∗∂wis∂Al,s)
其中
σ
l
,
s
σ_{l,s}
σl,s来自于
l
+
1
l+1
l+1层,误差由上一层传播而来;
∂ H l , s ∂ A l , s \frac{ \partial H_{l,s}}{\partial A_{l,s}} ∂Al,s∂Hl,s来自于 l l l层,对 l l l层的激活函数求导;
∂ A l , s ∂ w i s = H l − 1 , i \frac{ \partial A_{l,s}}{\partial w_{is}}=H_{l-1,i} ∂wis∂Al,s=Hl−1,i 来自于 l − 1 l-1 l−1层,即第 l − 1 l-1 l−1层第i个神经元的输出;
第
l
l
l层的第
s
s
s个神经元之间的偏置参数
b
s
b_s
bs的更新公式:
b
s
=
b
s
+
η
∗
(
σ
l
,
s
∗
∂
H
l
,
s
∂
A
l
,
s
∗
1
)
b_s=b_s+η*\Bigl(σ_{l,s}*\frac{ \partial H_{l,s}}{\partial A_{l,s}}*1\Bigr)
bs=bs+η∗(σl,s∗∂Al,s∂Hl,s∗1)
梯度弥散与梯度爆炸问题(待完善)
如果激活函数
H
H
H为Sigmoid函数,那么:
∂
H
l
,
s
∂
A
l
,
s
=
H
l
,
s
∗
(
1
−
H
l
,
s
)
\frac{ \partial H_{l,s}}{\partial A_{l,s}}=H_{l,s}*(1-H_{l,s})
∂Al,s∂Hl,s=Hl,s∗(1−Hl,s)
∵
0
≦
H
l
,
s
≦
1
\because0\leqq H_{l,s}\leqq 1
∵0≦Hl,s≦1
∴
0
≦
H
l
,
s
∗
(
1
−
H
l
,
s
)
≦
1
\therefore0\leqq H_{l,s}*(1-H_{l,s})\leqq 1
∴0≦Hl,s∗(1−Hl,s)≦1
总结:文中通过简单的线性回归、二分类等常见机器学习算法,引申至神经网络,使得神经网络参数的更新不再神秘,且使得BP算法更加容易理解!
https://zhuanlan.zhihu.com/p/91675218
















 1662
1662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









