






原来看过一遍,还是忘了,今天在这里做个笔记,给自己提个醒。
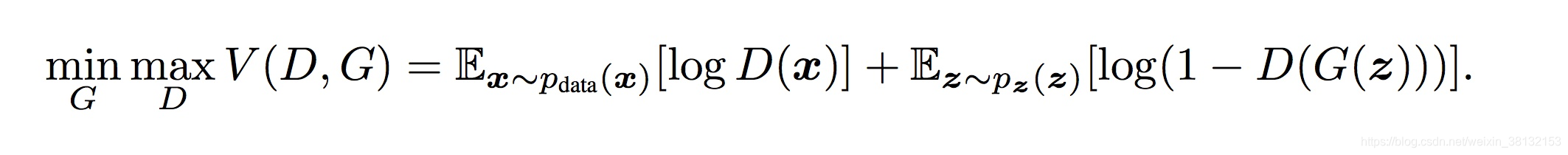
这个公式是最大化D和最小化G,xPdata(x)是样本中采样的真实图片,D(x)是真实图片的概率;zPz(z)指生成一份随机噪声z;G(z)是噪声z通过生成器生成的图片,D(G(z))是这个生成图片是真实图片的概率。期望E是因为每次训练的时候一批一批地输入。
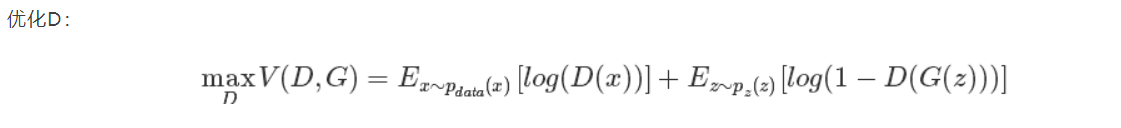
对于D而言,我们希望判定真实图片的概率高,假图片的判别低,但是D(x)和D(G(z))一个大一个小可不行,,所以我们在这里用1-D(G(z)),让两项变得都大,让D最大化。
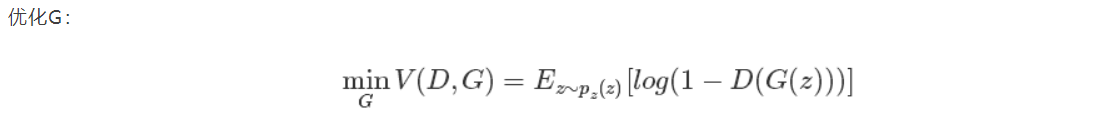
对于G而言,我们希望生成假图片更真实,D(G(z))更大,为了统一,我们就使用1-D(G(z)),让G最小化。
转载自https://blog.csdn.net/on2way/article/details/72773771
https://www.cnblogs.com/dynmi/p/12142722.html

















 582
582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









