







文章目录
- 前言: 该文章会一直更新遇到环境安装问题,使用他/她人博客解决方法,并附解决方法博客链接。
- 二十三、解决torchrun的端口冲突问题--RuntimeError: The server socket has failed to listen on any local network address. The server socket has failed to bind to [::]:29500 (errno: 98 - Address already in use). The server socket has failed to bind to ?UNKNOWN? (errno: 98 - Address already in use).
- 二十二、解决 VSCode 中的 ImportError: attempted relative import with no known parent package
- 二十一、yolov5热力图报错RuntimeError('one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [1, 3, 20, 15, 85]], which is output 0 of SigmoidBackward0, is at version 2; expected version 0 instead. Hint: the backtrace further above shows the operation that failed to compute its gradient. The variable in question was changed in there or anywhere later. Good luck!')
- 二十、yolov5报错AttributeError: 'FreeTypeFont' object has no attribute 'getsize'
- 十九、yolov5报错AttributeError: 'Upsample' object has no attribute 'recompute_scale_factor'
- 十八、nvidia-smi无法查看进程id
- 十七、Exception has occurred: CUDAMismatchException
- 十六、Ninja is required to load C++ extensions
- 十五、vscode如何构建.vscode来建立launch.json
- 十四、yolov5报错 RuntimeError: Output 0 of SelectBackward0 is a view and is being modified inplace. This view is the output of a function that returns multiple views. Such functions do not allow the output views to be modified inplace. You should replace the inplace operation by an out-of-place one.
- 十三、loss spike (loss 突刺)问题
- 十二、Exception has occurred: RuntimeError The server socket has failed to listen on any local network address. The server socket has failed to bind to [::]:29500 (errno: 98 - Address already in use). The server socket has failed to bind to ?UNKNOWN? (errno: 98 - Address already in use).问题
- 十一、LLAVA模型No slot '1' specified on host 'localhost'问题
- 十、llava遇到wandb: Network error (TransientError), entering retry loop.相关问题
- 九、PyTorch 中出现的 "compute_indices_weights_linear not implemented for 'Byte' torch" 错误
- 八、pycharm的debug无法显示变量内容
- 七、vscode界面无监视WATCH解决方法
- 六、OSError: [E050] Can't find model 'en_core_web_sm'.
- 五、ImportErrorImportError: cannot import name ‘UnencryptedCookieSessionFactoryConfig‘ from pyramid问题及解决方案
- 四、Could not load library libcudnn_cnn_train.so.8 问题及解决方案
- 三、args = parser.parse_args() SystemExit: 2 解决方案
- 二、VSCode报错:an ssh installation couldn‘t be found的解决方案
- 一、解决: _configtest.c:2:10: fatal error: mpi.h: No such file or directory #include <mpi.h>
前言: 该文章会一直更新遇到环境安装问题,使用他/她人博客解决方法,并附解决方法博客链接。
二十三、解决torchrun的端口冲突问题–RuntimeError: The server socket has failed to listen on any local network address. The server socket has failed to bind to [::]:29500 (errno: 98 - Address already in use). The server socket has failed to bind to ?UNKNOWN? (errno: 98 - Address already in use).
问题:torchrun默认端口被占用,需给定一个端口。
解决方法:我使用vscode的launch.json给定端口,具体如下:
{
"name": "train",
"type": "python",
"request": "launch",
// "python": "/home/miniconda3/envs/rt/bin/python", // 指定python解释器
"program": "/home/miniconda3/envs/rtdetr/bin/torchrun",
"console": "integratedTerminal",
"justMyCode": false,
"args": [
"--master_port", "12345", // 添加这一行来指定端口
"--nproc_per_node", "1",
"/prompt_detr/rtdetrv2_pytorch/tools/train.py",
],
"env": { // 设置环境变量
"CUDA_VISIBLE_DEVICES": "0"
}
},
特别说明:"--master_port", "12345"必须在"/prompt_detr/rtdetrv2_pytorch/tools/train.py",之前,否则设定端口不起作用!
二十二、解决 VSCode 中的 ImportError: attempted relative import with no known parent package
问题:导入包的问题,写了相应文件方法却无法导入,如下图:
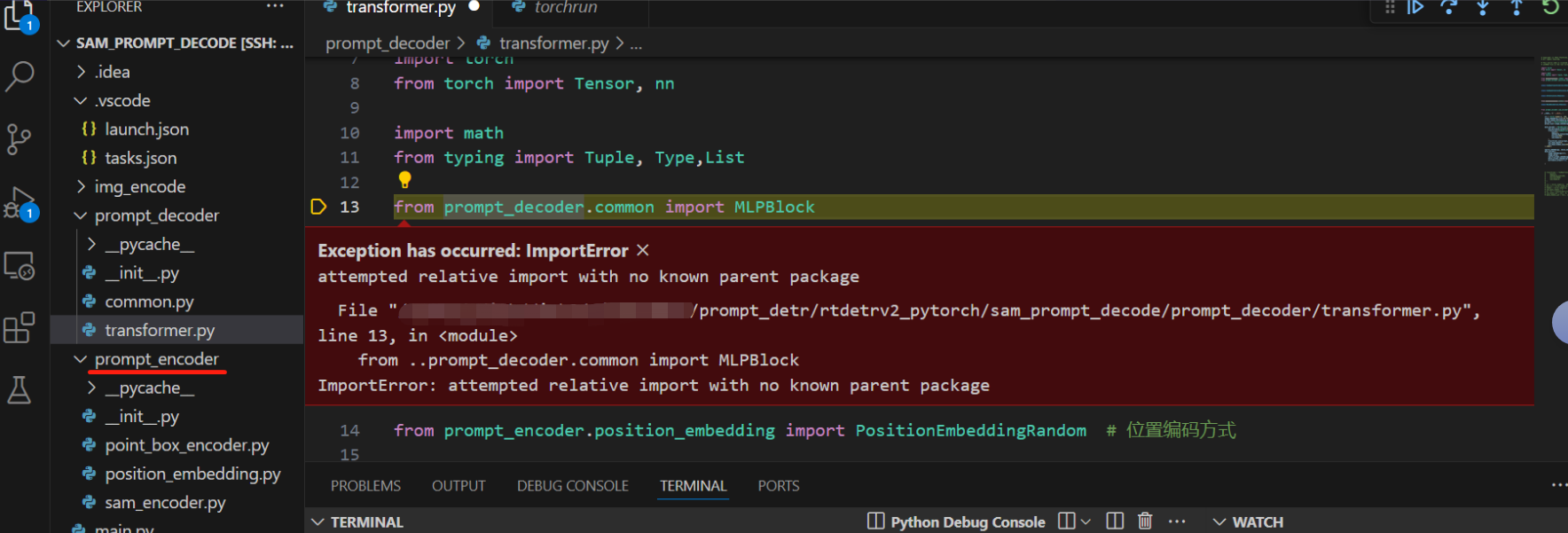
解决方法:代码中使用sys.path.apend给出路径,如下代码。
import sys
sys.path.append('/prompt_detr/rtdetrv2_pytorch/sam_prompt_decode')
from prompt_decoder.common import MLPBlock
我是这样解决的,但我想使用__init__.py应该也可以解决。
二十一、yolov5热力图报错RuntimeError(‘one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [1, 3, 20, 15, 85]], which is output 0 of SigmoidBackward0, is at version 2; expected version 0 instead. Hint: the backtrace further above shows the operation that failed to compute its gradient. The variable in question was changed in there or anywhere later. Good luck!’)
问题:which is output 0 of SigmoidBackward0, is at version 2; expected version 0 instead.
原因:做热力图时候使用yolov5-6.0版本的Detect类中的sigmoid出现了问题,有问题代码如下:
if not self.training: # inference
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)
z.append(y.view(bs, -1, self.no))
解决方法:修改代码如下
if not self.training: # inference
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
xy, wh, conf = x[i].sigmoid().split((2, 2, self.nc + 1), 4)
xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, conf), 4)
z.append(y.view(bs, self.na * nx * ny, self.no))
二十、yolov5报错AttributeError: ‘FreeTypeFont’ object has no attribute ‘getsize’
问题:AttributeError: ‘FreeTypeFont’ object has no attribute ‘getsize’
原因:pillow版本问题导致,按照10.0以上版本导致错误。
解决方法:直接pip重新安装pillow版本小于10.0,参考安装‘pip install pillow==9.5.0’
十九、yolov5报错AttributeError: ‘Upsample’ object has no attribute ‘recompute_scale_factor’
问题:yolov5遇到报错AttributeError: ‘Upsample’ object has no attribute ‘recompute_scale_factor’
原因:这个是因为torch版本原因导致的
解决方法:更换torch版本或修改torch版本源码
将torch\nn\modules\upsampling.py文件的154行代码return F.interpolate(input, self.size, self.scale_factor, self.mode, self.align_corners, recompute_scale_factor=self.recompute_scale_factor)改成return F.interpolate(input, self.size, self.scale_factor, self.mode, self.align_corners)。代码如下:
def forward(self, input: Tensor) -> Tensor:
# return F.interpolate(input, self.size, self.scale_factor, self.mode, self.align_corners,
# recompute_scale_factor=self.recompute_scale_factor)
return F.interpolate(input, self.size, self.scale_factor, self.mode, self.align_corners)
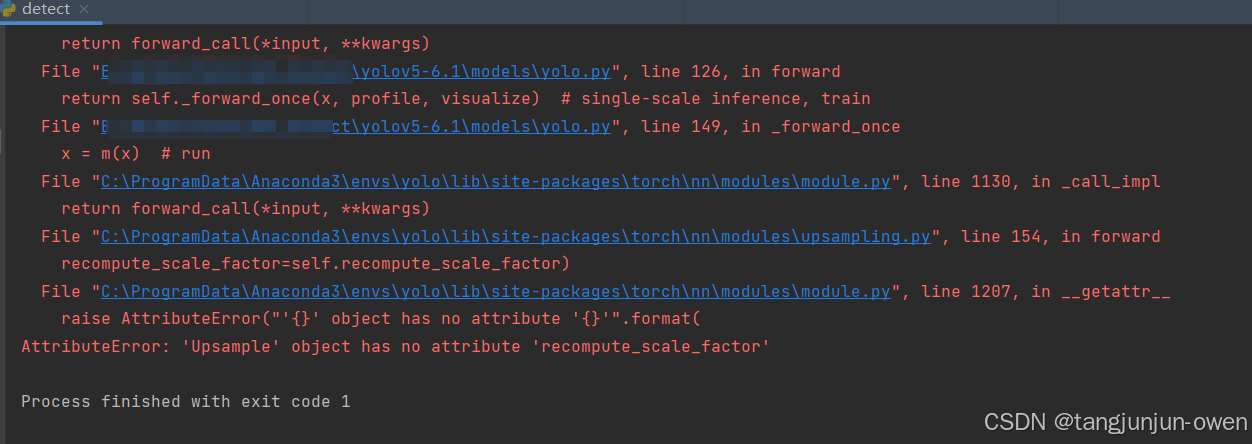
报错图
十八、nvidia-smi无法查看进程id
问题:当你使用nvidia-smi无法查看进程,特别是训练模型的进程,而占了显存
任务:kill 隐藏进程,特别是占了显存进程
解决方法:使用命令fuser -v /dev/nvidia*直接查看进程(其中*表示所有显卡,如想查看0号卡,就替换0即可),再使用kill -9 **杀死进程
十七、Exception has occurred: CUDAMismatchException
问题:CUDA不匹配

问题描述:我使用transformer=4.40.0版本库,torch使用2.1.0版本运行llama3模型,此时cuda是11.6不会出现任何问题,但我使用deepspeed加速时候,出现此类问题,需要cuda版本是12.1才能匹配。这种情况,就是直接重装cuda版本。
解决方法:重装cuda版本
解决时间:2024-08-27
十六、Ninja is required to load C++ extensions
问题:RuntimeError: Ninja is required to load C++ extensions
在加载一个使用C++扩展的模块时遇到了这个问题,提示需要安装Ninja才能加载这些扩展。

解决方法:
sudo apt-get update
sudo apt-get install ninja-build
参考链接:https://blog.csdn.net/qq_38964360/article/details/135224551
解决时间:2024-08-27
十五、vscode如何构建.vscode来建立launch.json
点击run的Add Configuration即可,如下图:

在按照以下步骤即可实现,如下:

解决时间:2024-07-19
十四、yolov5报错 RuntimeError: Output 0 of SelectBackward0 is a view and is being modified inplace. This view is the output of a function that returns multiple views. Such functions do not allow the output views to be modified inplace. You should replace the inplace operation by an out-of-place one.
问题:推理时候出现这种错误

原因:是推理梯度未关闭。
解决方法:
使用with torch.no_grad(),如下:
with torch.no_grad():
pred = model(im)[0]
解决时间:2024-03-8
十三、loss spike (loss 突刺)问题
问题:loss突刺问题:

这个问题比较难,但这是大模型会遇到的一个问题,大致是浅层学的很好梯度长时间不更新,深层一直更新,到某个点爆发导致浅层更新,故而w总体增大,导致loss增大。其参考博客为https://www.51cto.com/article/778469.html。我调小学习率可大致解决,论文有的是直接跳过突刺部分,如使用前200 steps的权重和跳过这些数据。
解决时间:2024-03-7
十二、Exception has occurred: RuntimeError The server socket has failed to listen on any local network address. The server socket has failed to bind to [::]:29500 (errno: 98 - Address already in use). The server socket has failed to bind to ?UNKNOWN? (errno: 98 - Address already in use).问题
问题:vscode需debug模型llava时报错,如下:
Exception has occurred: RuntimeError
The server socket has failed to listen on any local network address. The server socket has failed to bind to [::]:29500 (errno: 98 - Address already in use). The server socket has failed to bind to ?UNKNOWN? (errno: 98 - Address already in use).
实际是端口port问题。
原因:实际是端口port问题。
解决方法:
在launch.json文件中env环境变量设置,如下:
"env": {
"MASTER_PORT":"8400",
},
解决时间:2024-02-21
十一、LLAVA模型No slot ‘1’ specified on host 'localhost’问题
问题:deepspeed选择显卡报错问题
原因:deepspeed不友好"CUDA_VISIBLE_DEVICES": "1"设置。
解决方法:
使用include变量解决,如下:
"--include","localhost:0,1",
vscode的launch.json文件配置:

官网格式:deepspeed --include localhost:1 …
解决时间:2024-01-18
十、llava遇到wandb: Network error (TransientError), entering retry loop.相关问题
问题:wandb: Network error (TransientError), entering retry loop.
wandb: / 0.000 MB of 0.006 MB uploaded
解决方法:系统环境配置:
os.environ["WANDB_API_KEY"] = YOUR_KEY_HERE
os.environ["WANDB_MODE"] = "offline"

解决方法链接:https://blog.csdn.net/ZJFJhanxi/article/details/134099508
解决时间:2024-01-17
九、PyTorch 中出现的 “compute_indices_weights_linear not implemented for ‘Byte’ torch” 错误
原因:通常是由于数据类型不匹配或不支持所使用的操作。
解决方法:数据类型转换:检查你的数据类型是否正确。如果你的数据类型是 ‘Byte’,尝试将它转换为其他适合的数据类型,比如 ‘Float’ 或 ‘Double’。
# 将数据类型从 'Byte' 转换为 'Float'
tensor_float = tensor_byte.to(dtype=torch.float32)
解决时间:2024-01-09
八、pycharm的debug无法显示变量内容
解决方法:确认debug模式的设置:在PyCharm的“Run”菜单中选择“Edit Configurations”,确保debug模式的“Debugger”设置为“Python Debugger”,并且“Debug Console”选项被选中。
解决时间:2024-01-08

七、vscode界面无监视WATCH解决方法
解决方法:启动debug模式,代码空白处或指着变量右击鼠标,点击下图红框即可。
解决时间:2023-12-28

六、OSError: [E050] Can’t find model ‘en_core_web_sm’.
原因:没有相关库
解决方法:下载安装即可
解决时间:2023-12-25
我运行成功方法:
下载:
可以使用命令下载:python3 -m spacy download en_core_web_sm
也可以直接使用链接手动下载(链接来源命令):
https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.7.1/en_core_web_sm-3.7.1-py3-none-any.whl
安装:
pip install en_core_web_sm-3.7.1/en_core_web_sm-3.7.1-py3-none-any.whl
通过运行:

其它安装方法:https://zhuanlan.zhihu.com/p/566343999?utm_id=0
推荐sapcy库学习博客:https://blog.csdn.net/YWP_2016/article/details/102851532
五、ImportErrorImportError: cannot import name ‘UnencryptedCookieSessionFactoryConfig‘ from pyramid问题及解决方案
原因:torch版本兼容问题
解决方法:更改低版本或调整环境
解决时间:2023-12-25
查看链接:点击这里
我的方法:
官网下载apex库这里
修改setup.py内容,如下:

在使用官网命令这里:
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" ./
四、Could not load library libcudnn_cnn_train.so.8 问题及解决方案
原因:高版本torch版本自带cudnn文件导致
解决方法:更改低版本或调整环境
解决时间:2023-12-20
查看链接:点击这里
三、args = parser.parse_args() SystemExit: 2 解决方案
解决方法:args = parser.parse_args()改成如下:
args = parser.parse_args(args=[])
查看链接:点击这里
解决时间:2023-12-14
二、VSCode报错:an ssh installation couldn‘t be found的解决方案
在PowerShell中执行如下命令:
Add-WindowsCapability -Online -Name OpenSSH.Client~~~~0.0.1.0
查看链接:点击这里
解决时间:2023-12-14
一、解决: _configtest.c:2:10: fatal error: mpi.h: No such file or directory #include <mpi.h>
核心命令:
sudo apt install libopenmpi-dev
pip install mpi4py
查看链接:点击这里
解决时间:2023-12-13



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











