







文章目录
- 引言
- 摘要
- 一、引言
- 二、文献研究
- 三、方法-PDFTriage: Structured Retrieval from Document Metadata
- 四、数据集构建-Dataset Construction
- 五、实验
- 六、结果与分析
-
- 6.1 PDFTriage生成的答案优于基于检索的方法-PDFTriage yields better answers than retrieval-based approaches
- 6.2 PDFTriage提高了答案的质量、准确性、可读性和信息量-PDFTriage improves answer quality, accuracy, readability, and informativeness
- 6.3 PDFTriage需要检索更少的标记以生成更好的答案-PDFTriage requires fewer retrieved tokens to produce better answers
- 与方法相关的数据
引言
最近狂学RAG内容,特别是如何有效检索。碰到PDFTriage文章是来解决结构层次的文档,对PDF、网页和演示文稿等文档具有自然的结构,包括不同的页面、表格、章节等。将这些结构化的文档表示为纯文本与用户对这些具有丰富结构的文档的心理模型不一致。当系统需要查询文档以获取上下文时,这种不一致性尤为明显,即使是看似简单的问题也可能使QA系统出错。为了弥合这一处理结构化文档的基本差距,我们提出了一种名为PDFTriage的方法,使模型能够基于结构或内容检索上下文。

摘要
Large Language Models (LLMs) have issues with document question answering (QA) in situations where the document is unable to fit in the small context length of an LLM. To overcome this issue, most existing works focus on retrieving the relevant context from the document, representing them as plain text. However, documents such as PDFs, web pages, and presentations are naturally structured with different pages, tables, sections, and so on. Representing such structured documents as plain text is incongruous with the user’s mental model of these documents with rich structure. When a system has to query the document for context, this incongruity is brought to the fore, and seemingly trivial questions can trip up the QA system. To bridge this fundamental gap in handling structured documents, we propose an approach called PDFTriage that enables models to retrieve the context based on either structure or content. Our experiments demonstrate the effectiveness of the proposed PDFTriage-augmented models across several classes of questions where existing retrieval-augmented LLMs fail. To facilitate further research on this fundamental problem, we release our benchmark dataset consisting of 900+ human-generated questions over 80 structured documents from 10 different categories of question types for document QA. Our code and datasets will be released soon on Github.
大型语言模型(LLMs)在处理文档问答(QA)时,面临的一个问题是当文档无法适应LLM的上下文长度时。为了解决这个问题,大多数现有工作集中在从文档中检索相关上下文,并将其表示为纯文本。然而,如PDF、网页和演示文稿等文档具有自然的结构,包括不同的页面、表格、章节等。将这些结构化的文档表示为纯文本与用户对这些具有丰富结构的文档的心理模型不一致。当系统需要查询文档以获取上下文时,这种不一致性尤为明显,即使是看似简单的问题也可能使QA系统出错。为了弥合这一处理结构化文档的基本差距,我们提出了一种名为PDFTriage的方法,使模型能够基于结构或内容检索上下文。我们的实验表明,在几个问题类别上,所提出的PDFTriage增强型模型比现有的检索增强型LLM更有效。为了促进对该基本问题的进一步研究,我们发布了包含超过900个针对80份结构化文档的人工生成问题的数据集,涵盖了10种不同类别的文档QA问题类型。我们的代码和数据集将在不久后在Github上发布。
一、引言
When a document does not fit in the limited context window of an LLM, different strategies can be deployed to fetch relevant context. Current approaches often rely on a pre-retrieval step to fetch the relevant context from documents (Pereira et al., 2023; Gao et al., 2022). These pre-retrieval steps tend to represent the document as plain text chunks, sharing some similarity with the user query and potentially containing the answer. However, many document types have rich structure, such as web pages, PDFs, presentations, and so on. For these structured documents, representing the document as plain text is often incongruous with the user’s mental model of a structured document. This can lead to questions that, to users, may be trivially answerable, but fail with common/current approaches to document QA using LLMs. For instance, consider the following two questions:
Q1 “Can you summarize the key takeaways from pages 5-7?” Q2 “What year[in table 3] has the maximum revenue?”
当文档不适合LLM的有限上下文窗口时,可以部署不同的策略来获取相关上下文。当前的方法通常依赖于预检索步骤从文档中获取相关上下文(Pereira et al., 2023; Gao et al., 2022)。这些预检索步骤倾向于将文档表示为纯文本块,这些文本块与用户查询具有某些相似性,并可能包含答案。然而,许多文档类型都有丰富的结构,如网页、PDF、演示文稿等。对于这些结构化的文档,将其视为纯文本往往与用户对结构化文档的心理模型不一致。这可能导致对于用户来说可能是微不足道的问题,但在使用LLMs进行文档QA时却失败了。例如,考虑以下两个问题:
Q1:“你能总结第5-7页的关键要点吗?” Q2:“表3中哪一年的收入最高?”
In the first question, document structure is explicitly referenced (“pages 5-7”). In the second question, document structure is implicitly referenced (“in table 3”). In both cases, a representation of document structure is necessary to identify the salient context and answer the question. Considering the document as plain text discards the relevant structure needed to answer these questions. We propose addressing this simplification of documents by allowing models to retrieve the context based on either structure or content. Our approach, which we refer to as PDFTriage, gives models access to metadata about the structure of the document. We leverage document structure by augmenting prompts with both document structure metadata and a set of model-callable retrieval functions over various types of structure. For example, we introduce the fetch_pages(pages: list[int]) function, which allows the model to fetch a list of pages. We show that by providing the structure and the ability to issue queries over that structure, PDFTriage-augmented models can reliably answer several classes of questions that plain retrieval-augmented LLMs could not.
在第一个问题中,明确引用了文档结构(“第5-7页”)。在第二个问题中,隐式引用了文档结构(“表3中”)。在这两种情况下,都需要文档结构的表示来识别重要的上下文并回答问题。如果将文档视为纯文本,则会丢失回答这些问题所需的相关结构。我们建议通过允许模型基于结构或内容检索上下文来解决这种简化处理文档的方式。我们称之为PDFTriage的方法,使模型能够访问有关文档结构的元数据。我们通过增强提示词既包括文档结构元数据,也包括一组可调用的检索函数,覆盖各种类型的结构,从而利用文档结构。例如,我们引入了fetch_pages(pages: list[int])函数,允许模型提取一系列页面。我们表明,通过提供结构和对结构发出查询的能力,PDFTriage增强型模型可以可靠地回答几类问题,而这些问题是普通检索增强型LLM无法回答的。
In order to evaluate our approach, we construct a dataset of roughly 900 human-written questions over 90 documents, representing 10 different categories of questions that users might ask. Those categories include “document structure questions”, “table reasoning questions”, and “trick questions”, among several others. We will release the dataset of questions, documents, model answers, and annotator preferences. In addition, we release the code and prompts used.
为了评估我们的方法,我们构建了一个包含大约900个人工编写的问题的数据集,涵盖了10种不同类别的问题,这些问题可能是用户询问的。这些类别包括“文档结构问题”、“表格推理问题”以及“棘手问题”等。我们将发布包含问题、文档、模型答案和注释者偏好的数据集。此外,我们还将发布使用的代码和提示词。
二、文献研究
2.1 工具和检索增强的LLM-Tool and Retrieval Augmented LLMs
Tool-augmented LLMs have become increasingly popular as a way to enhance existing LLMs to utilize tools for responding to human instructions (Schick et al., 2023). ReAct (Yao et al., 2022) is a few-shot prompting approach that leverages the Wikipedia API to generate a sequence of API calls to solve a specific task. Such task-solving trajectories are shown to be more interpretable compared to baselines. Self-ask (Press et al., 2022) prompt provides the follow-up question explicitly before answering it, and for ease of parsing uses a specific scaffold such as “Follow-up question:” or “So the final answer is:”. Toolformer (Schick et al., 2023) uses self-supervision to teach itself to use tools by leveraging the few-shot capabilities of an LM to obtain a sample of potential tool uses, which is then fine-tuned on a sample of its own generations based on those that improve the model’s ability to predict future tokens. TALM (Parisi et al., 2022) augments LMs with non-differentiable tools using only text along with an iterative technique to bootstrap performance using only a few examples. Recently, Taskmatrix (Liang et al., 2023) and Gorilla (Patil et al., 2023) have focused on improving the ability of LLMs to handle millions of tools from a variety of applications. There have also been many works focused on benchmarks for tool-augmented LLMs (Li et al., 2023; Zhuang et al., 2023). These include API-Bank (Li et al., 2023), focused on evaluating LLMs’ ability to plan, retrieve, and correctly execute step-by-step API calls for carrying out various tasks, and ToolQA (Zhuang et al., 2023) that focused on question-answering using external tools.
随着工具增强型LLM变得越来越流行,作为一种利用工具响应人类指令来增强现有LLM的方法(Schick et al., 2023)。ReAct(Yao et al., 2022) 是一种少量示例提示方法,它利用Wikipedia API生成一系列API调用来解决特定任务。这种任务解决轨迹被证明比基线更具可解释性。Self-ask(Press et al., 2022) 提示明确地提供了后续问题,并为了便于解析使用了特定的框架,如“Follow-up question:”或“So the final answer is:”。Toolformer(Schick et al., 2023) 使用自我监督教自己使用工具,通过利用LM的少量示例能力获取潜在工具使用的样本,然后基于那些能够提高模型预测未来令牌能力的样本进行微调。TALM(Parisi et al., 2022) 使用仅文本以及迭代技术来引导性能提升,仅需几个例子即可。最近,Taskmatrix(Liang et al., 2023) 和Gorilla(Patil et al., 2023) 专注于提高LLMs处理来自各种应用程序的数百万个工具的能力。此外,还存在许多关注于工具增强型LLM基准的工作(Li et al., 2023; Zhuang et al., 2023)。这些包括API-Bank(Li et al., 2023),专注于评估LLMs规划、检索并正确执行逐步API调用以完成各种任务的能力,以及ToolQA(Zhuang et al., 2023),专注于使用外部工具进行问答。
Retrieval-augmented language models aim to enhance the reasoning capabilities of LLMs using external knowledge sources for retrieving related documents (Asai et al., 2022; Gao et al., 2022; Lin et al., 2023; Yu et al., 2023; Zhao et al., 2023; Feng et al., 2023). In particular, HyDE (Gao et al., 2022) generates a hypothetical document (capturing relevance patterns) by zero-shot instructing an instruction-following LLM, then encodes the document into an embedding vector via an unsupervised contrastively learned encoder, which is used to retrieve real documents that are similar to the generated document. More recently, Feng et al. (2023) proposed InteR that iteratively refines the inputs of search engines and LLMs for more accurate retrieval. Specifically, InteR uses search engines to enhance the knowledge in queries using LLM-generated knowledge collections whereas LLMs improve prompt formulation by leveraging the retrieved documents from the search engine. For further details on augmented language models, see the recent survey (Mialon et al., 2023).
检索增强语言模型旨在通过外部知识源增强LLMs的推理能力,以检索相关文档(Asai et al., 2022; Gao et al., 2022; Lin et al., 2023; Yu et al., 2023; Zhao et al., 2023; Feng et al., 2023)。特别是HyDE(Gao et al., 2022) 通过零样本指令指导一个遵循指令的LLM生成一个假设文档(捕捉相关模式),然后通过无监督对比学习编码器将该文档编码为嵌入向量,用于检索与生成文档相似的真实文档。更近一步,Feng等人(2023) 提出了InteR,它迭代地细化搜索引擎和LLMs的输入,以获得更准确的检索。具体来说,InteR使用搜索引擎利用LLM生成的知识集合来增强查询中的知识,而LLMs则通过利用从搜索引擎检索到的文档来改进提示词的制定。有关增强语言模型的更多细节,请参阅最新的综述(Mialon et al., 2023)。
2.2 问答系统-Question Answering
Much of the existing work in QA does not ground the questions in structured documents, instead primarily focusing on extractive QA tasks such as GLUE (Wang et al., 2018). For example, text-only documents in QA datasets, like SQuAD (Rajpurkar et al., 2016) and NaturalQuestions (Kwiatkowski et al., 2019), don’t contain tables or figures. Document Question Answering. Several datasets have been constructed to benchmark different aspects of document-focused question-answering. DocVQA (Mathew et al., 2021) is a visual question-answering dataset focused that uses document scans. A recent work by Landeghem et al. (2023) focused on a dataset for document understanding and evaluation called DUDE, which uses both scans and born-digital PDFs. Both DUDE and DocVQA have questions that can be answered short-form; DUDE answers average roughly 3.35 tokens and DocVQA tokens average 2.11 tokens. QASPER (Dasigi et al., 2021) is a dataset focused on information-seeking questions and their answers from research papers, where the documents are parsed from raw LATEX sources and the questions are primarily focused on document contents. The PDFTriage evaluation dataset seeks to expand on the question types in these datasets, getting questions that can reference the document structure or content, can be extractive or abstractive, and can require long-form answers or rewrites.
大多数现有的问答系统(QA)并未基于结构化文档提出问题,而是主要集中在如GLUE(Wang et al., 2018)等数据集上的提取式问答任务。例如,像SQuAD(Rajpurkar et al., 2016)和NaturalQuestions(Kwiatkowski et al., 2019)这样的QA数据集中的纯文本文档不包含表格或图表。文件问答系统。已经构建了一些数据集来评估不同方面的文档聚焦问答。DocVQA(Mathew et al., 2021)是一个视觉问答数据集,专注于使用文档扫描。Landegeh等人(2023)最近的工作关注的是名为DUDE的数据集,用于文档理解和评估,它使用了扫描和原生数字PDF。DUDE和DocVQA都有可以简短回答的问题;DUDE的答案平均约为3.35个标记,而DocVQA的答案平均约为2.11个标记。QASPER(Dasigi et al., 2021) 是一个专注于从研究论文中寻求信息的问题及其答案的数据集,其中文档是从原始LATEX源解析出来的,问题主要集中在文档内容上。PDFTriage评估数据集旨在扩展这些数据集的问题类型,获取可以引用文档结构或内容、可以是提取式或抽象式并且可能需要长篇回答或重写的问题。
三、方法-PDFTriage: Structured Retrieval from Document Metadata
The PDFTriage approach consists of three steps to answer a user’s question, shown in Figure 1:
- Generate document metadata (Sec. 3.1): Extract the structural elements of a document and convert them into readable metadata.
- LLM-based triage (Sec. 3.2): Query the LLM to select the precise content (pages, sections, retrieved content) from the document.
- Answer using retrieved content (Sec. 3.3): Based on the question and retrieved content, generate an answer.
PDFTriage方法包括三个步骤来回答用户的问题,如图1所示:
- 生成文档元数据(第3.1节):提取文档的结构元素并将其转换为可读的元数据。
- 基于LLM的分类(第3.2节):查询LLM以选择回答查询所需的精确内容(页面、章节、检索的内容)。
- 使用检索到的内容回答问题(第3.3节):根据问题和检索到的内容生成答案。
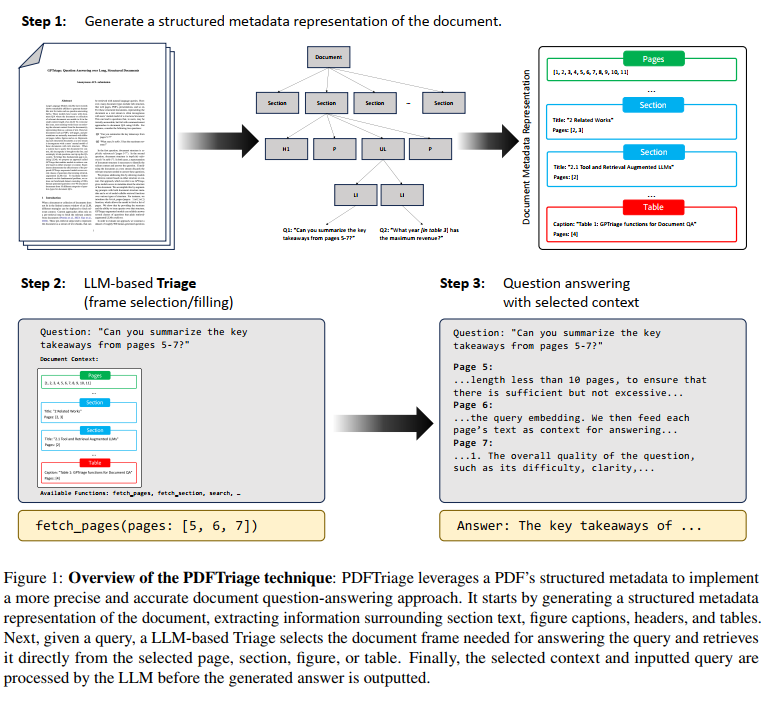
3.1 文档表示-Document Representation
We consider born-digital PDF documents as the structured documents that users will be interacting with. Using the Adobe Extract API, we convert the PDFs into an HTML-like tree, which allows us to extract sections, section titles, page information, tables, and figures. The Extract API generates a hierarchical tree of elements in the PDF, which includes section titles, tables, figures, paragraphs, and more. Each element contains metadata, such as its page and location. We can parse that tree to identify sections, section-levels, and headings, gather all the text on a certain page, or get the text around figures and tables. We map that structured information into a JSON type, that we use as the initial prompt for the LLM. The content is converted to markdown. An overview of this process is shown at the top of Figure 1.
我们考虑原生数字PDF文档作为用户将要交互的结构化文档。使用Adobe Extract API,我们将PDF转换成类似HTML的树形结构,这允许我们提取章节、章节标题、页面信息、表格和图表。Extract API生成一个包含章节标题、表格、图表、段落等元素的PDF层次树。每个元素包含元数据,例如其页码和位置。我们可以解析该树来识别章节、章节级别和标题,收集特定页面上的所有文本,或获取图表和表格周围的文本。我们将这些结构化信息映射为JSON格式,并将其用作LLM初始提示的一部分。内容被转换为Markdown格式。这一过程的概述显示在图1顶部。
3.2 LLM查询文档-LLM Querying of Document
PDFTriage utilizes five different functions in the approach: fetch_pages, fetch_sections, fetch_table, fetch_figure, and retrieve. As described in Table 2, each function allows the PDFTriage system to gather precise information related to the given PDF document, centering around structured textual data in headers, subheaders, figures, tables, and section paragraphs. The functions are used in separate queries by the PDFTriage system for each question, synthesizing multiple pieces of information to arrive at the final answer. The functions are provided and called in separate chat turns via the OpenAI function calling API, though it would be possible to organize the prompting in a ReAct (Yao et al., 2022) or Toolformer (Schick et al., 2023)-like way.
PDFTriage利用了五种不同的函数来进行查询:fetch_pages、fetch_sections、fetch_table、fetch_figure 和 retrieve。如表2所述,每个函数允许PDFTriage系统获取与给定PDF文档相关的精确信息,围绕标题、副标题、图表、表格和章节段落中的结构化文本数据。这些函数在每个问题上由PDFTriage系统分别查询,综合多条信息得出最终答案。函数通过OpenAI函数调用API在单独的聊天回合中提供和调用,尽管也可以以ReAct(Yao et al., 2022)或Toolformer(Schick et al., 2023)的方式组织提示。

3.3 问答系统-Question Answering
To initialize PDFTriage for question-answering, we use the system prompt format of GPT-3.5 to input the following:
“You are an expert document question answering system. You answer questions by finding relevant content in the document and answering questions based on that content.”
Document:
Using user prompting, we then input the query with no additional formatting. Next, the PDFTriage system uses the functions established in Section 2 to query the document for any necessary information to answer the question. In each turn, PDFTriage uses a singular function to gather the needed information before processing the retrieved context. In the final turn, the model outputs an answer to the question. For all of our experiments, we use the gpt-35-turbo-0613 model.
为了初始化PDFTriage进行问答,我们使用GPT-3.5的系统提示格式输入以下内容:
“您是一个专家文档问答系统。您通过在文档中找到相关的内容来回答问题。”
文档:<文档的文本元数据>
然后,通过用户提示输入查询,不添加额外格式。接下来,PDFTriage系统使用第2节建立的函数查询文档以获取回答问题所需的任何信息。在每次轮次中,PDFTriage使用单一函数收集所需信息,然后处理检索到的上下文。在最后一轮中,模型输出问题的答案。对于我们的所有实验,我们使用gpt-35-turbo-0613模型。
四、数据集构建-Dataset Construction
To test the efficacy of PDFTriage, we constructed a document-focused set of question-answering tasks. Each task seeks to evaluate different aspects of document question-answering, analyzing reasoning across text, tables, and figures within a document. Additionally, we wanted to create questions ranging from single-step answering on an individual document page to multi-step reasoning across the whole document.
为了测试PDFTriage的有效性,我们构建了一个专注于文档的任务问答数据集。每个任务旨在评估文档问答的不同方面,分析跨文本、表格和文档内的图形的推理。此外,我们希望创建从单个文档页面上的单步回答到整个文档的多步推理的问题范围。
We collected questions using Mechanical Turk. The goal of our question collection task was to collect real-world document-oriented questions for various professional settings. For our documents, we sampled 1000 documents from the Common Crawl to get visually-rich, professional documents from various domains, then subsampled 100 documents based on their reading level (Flesch, 1948). By collecting a broad set of document-oriented questions, we built a robust set of tasks across industries for testing the PDFTriage technique.
我们使用Mechanical Turk收集问题。我们的目标是收集针对各种专业环境的真实世界文档导向问题。对于我们的文档,我们从Common Crawl中抽取了1000份文档以获取来自不同领域的视觉丰富、专业的文档,然后根据其阅读水平(Flesch, 1948)进一步从中抽取100份文档。通过收集广泛的文档导向问题,我们构建了一个跨越多个行业的强大任务集,用于测试PDFTriage技术。
In order to collect a diverse set of questions, we generated our taxonomy of question types and then proceeded to collect a stratified sample across the types in the taxonomy. Each category highlights a different approach to document-oriented QA, covering multi-step reasoning that is not found in many other QA datasets. We asked annotators to read a document before writing a question. They were then tasked with writing a salient question in the specified category.
为了收集多样化的问题集,我们生成了问题类型的分类,并随后按该分类中的类型进行了分层抽样。每个类别突出了不同的文档导向QA方法,涵盖了在许多其他QA数据集中未找到的多步推理。我们要求标注者在编写问题之前先阅读文档,然后按照指定类别撰写相关问题。
For our taxonomy, we consider ten different categories along with their associated descriptions:
- Figure Questions (6.5%): Ask a question about a figure in the document.
- Text Questions (26.2%): Ask a question about the document.
- Table Reasoning (7.4%): Ask a question about a table in the document.
- Structure Questions (3.7%): Ask a question about the structure of the document.
- Summarization (16.4%): Ask for a summary of parts of the document or the full document.
- Extraction (21.2%): Ask for specific content to be extracted from the document.
- Rewrite (5.2%): Ask for a rewrite of some text in the document.
- Outside Questions (8.6%): Ask a question that can’t be answered with just the document.
- Cross-page Tasks (1.1%): Ask a question that needs multiple parts of the document to answer.
- Classification (3.7%): Ask about the type of the document.
对于我们的分类,我们考虑了十个不同的类别及其相关的描述: - 图形问题 (6.5%):询问文档中的一个图形。
- 文本问题 (26.2%):询问关于文档的问题。
- 表格推理 (7.4%):询问关于文档中表格的问题。
- 结构问题 (3.7%):询问关于文档结构的问题。
- 概括 (16.4%):请求对文档的部分或全部内容进行总结。
- 提取 (21.2%):请求从文档中提取特定内容。
- 改写 (5.2%):请求改写文档中的某些文本。
- 外部问题 (8.6%):提出无法仅凭文档回答的问题。
- 跨页任务 (1.1%):需要多个部分的文档来回答的问题。
- 分类 (3.7%):询问文档的类型。
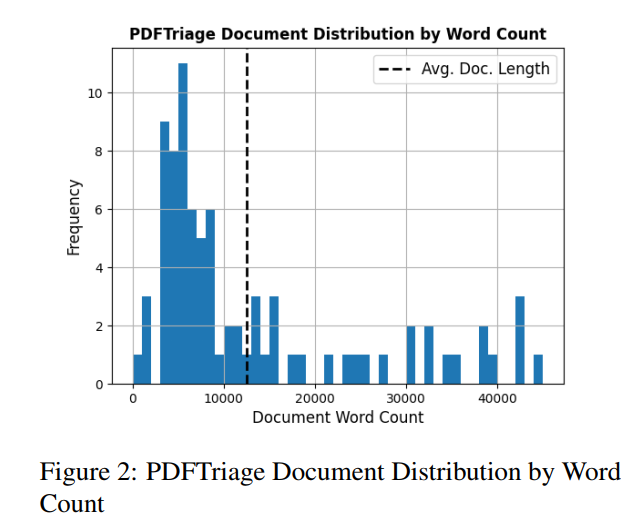
In total, our dataset consists of 908 questions across 82 documents. On average a document contains 4,257 tokens of text, connected to headers, subheaders, section paragraphs, captions, and more. In Figure 2, we present the document distribution by word count. We provide detailed descriptions and examples of each of the classes in the appendix.
总计,我们的数据集包括82个文档中的908个问题。平均而言,文档包含4,257个标记的文本,连接到标题、副标题、章节段落、图注等。在图2中,我们展示了按字数划分的文档分布情况。我们在附录中提供了每个类别的详细描述和示例。
五、实验
We outline the models and strategies used in our approach along with our baselines for comparison. The code and datasets for reproducing our results will be released soon on Github.
我们概述了在我们的方法中使用的模型和策略,以及用于比较的基线。用于重现我们结果的代码和数据集将在不久后在Github上发布。
5.1 PDFTriage
For our primary experiment, we use our PDFTriage approach to answer various questions in the selected PDF document dataset. This strategy leverages the structure of PDFs and the interactive system functions capability of GPT-3.5 to extract answers more precisely and accurately than existing naive approaches.
对于我们的主要实验,我们使用PDFTriage方法来回答选定PDF文档数据集中的各种问题。该策略利用PDF的结构和GPT-3.5的交互系统功能来更精确和准确地提取答案,而不是现有的简单方法。
5.2 检索基线-Retrieval Baselines
Page Retrieval: For our first baseline, we index the pages of each individual document using text-embedding-ada-002 embeddings. Using cosine similarity, we retrieve the pages most similar to the query embedding. We then feed each page’s text as context for answering the given question until we reach the context window limit for a model.
Chunk Retrieval: In our second baseline, we concatenate all the document’s text before chunking it into 100-word pieces. We then index each chunk using text-embedding-ada-002 embeddings before using cosine similarity calculations to retrieve the chunks most similar to the query embedding. Finally, we feed each chunk’s textual contents as context for answering the given question until we reach the context window limit for a model.
Prompting: For both retrieval baselines, we use the following prompt to get an answer from GPT-3.5:
“You are an expert document question answering system. You answer questions by finding relevant content in the document and answering questions based on that content.”
Document: <retrieved pages/chunks>
Question:
页面检索:对于我们的第一个基线,我们使用text-embedding-ada-002嵌入对每个单独文档的页面进行索引。使用余弦相似度,我们检索与查询嵌入最相似的页面。然后我们将每个页面的文本作为上下文用于回答给定的问题,直到达到模型的上下文窗口限制。
块检索:在我们的第二个基线中,我们在将文档的所有文本拼接成100个单词的块之前进行处理。然后我们使用text-embedding-ada-002嵌入对每个块进行索引,并使用余弦相似度计算检索与查询嵌入最相似的块。最后,我们将每个块的文本内容作为上下文用于回答给定的问题,直到达到模型的上下文窗口限制。
提示词:对于两种检索基线,我们使用以下提示词从GPT-3.5获取答案:
“您是一个专家文档问答系统。您通过在文档中找到相关的内容来回答问题。”
文档:<检索到的页面/块>
问题:<问题>
5.3 人工评估-Human Evaluation
To measure any difference between PDFTriage and the retrieval baselines, we established a human labeling study on Upwork. In the study, we hired 12 experienced English-speaking annotators to judge the answers generated by each system. Please see Appendix A to see the full annotation questions for each question-document and its generated answers (for the overview, we use a sample question) as well as demographic information about the annotators.
Our questions seek to understand several key attributes of each question-document pair as well as the associated general questions:
- The overall quality of the question, such as its difficulty, clarity, and information needed for answering it.
- The category of the question, using the taxonomy in section 4.
- The ranking of each generated answer for the given question-document pair.
- The accuracy, informativeness, readability/understandability, and clarity of each generated answer.
为了衡量PDFTriage与检索基线之间的差异,我们在Upwork上建立了一项人工标注研究。在研究中,我们聘请了12位有经验的英语母语标注者来评判每个系统生成的答案。请参阅附录A以查看每个问题-文档及其生成答案的完整注释问题(对于概览,我们使用了一个示例问题)以及标注者的详细信息。
我们的问题是为了解多个关键属性,包括:
- 问题的整体质量,例如其难度、清晰度和回答所需的信息。
- 使用第4节中的分类法对问题类别进行分类。
- 给定问题-文档对的每个生成答案的排名。
- 每个生成答案的准确性、信息量、可读性/易理解性和清晰度。
六、结果与分析
In Table 1, we present the annotated question difficulty of each question in our sample. Overall, the largest group of questions (43.3%) were categorized as Easy while roughly a third of questions were categorized as Hard for various reasons.
在表1中,我们展示了样本中每个问题的注释难度。总体而言,最大的问题组(43.3%)被归类为简单问题,而大约三分之一的问题由于各种原因被归类为难题。
In addition to question difficulty, we asked annotators to categorize questions by type using the same categories as Section 4. Our annotation framework results in a dataset that’s diverse across both question types and question difficulties, covering textual sections, tables, figures, and headings as well as single-page and multi-page querying. The diversity of questions allows us to robustly evaluate multiple styles of document-centered QA, testing the efficacy of PDFTriage for different reasoning techniques.
除了问题难度外,我们还要求标注者使用第4节中的分类法对问题进行分类。我们的注释框架结果是一个在问题类型和问题难度上都多样化的数据集,涵盖了文本部分、表格、图形和标题以及单页和多页查询。这种多样性的问题使我们能够稳健地评估多种文档中心QA风格,测试PDFTriage在不同推理技术上的有效性。
6.1 PDFTriage生成的答案优于基于检索的方法-PDFTriage yields better answers than retrieval-based approaches
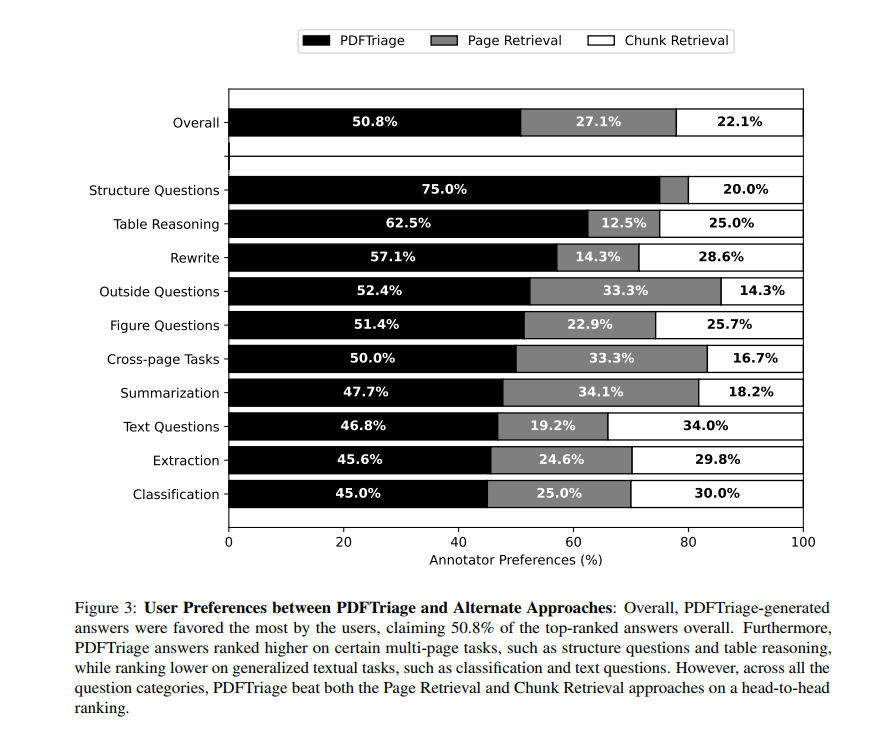
In our annotation study, we asked the annotators to rank PDFTriage compared to our two baselines, Page Retrieval and Chunk Retrieval (Section 5). In Figure 3, we found that annotators favored the PDFTriage answer over half of the time (50.7%) and favored the Chunk Retrieval approach over the Page Retrieval approach. When comparing different provided answers for the same question, PDFTriage performs substantially better than current alternatives, ranking higher than the alternate approaches across all the question types.
在我们的注释研究中,我们让标注者对我们两种基线(页面检索和块检索)与PDFTriage进行排名(见第5节)。如图3所示,我们发现标注者更倾向于选择PDFTriage答案超过一半的时间(50.7%),并且更偏好块检索方法而非页面检索方法。当比较同一问题的不同提供的答案时,PDFTriage的表现显著优于当前的替代方案,在所有问题类型中均排名较高。
6.2 PDFTriage提高了答案的质量、准确性、可读性和信息量-PDFTriage improves answer quality, accuracy, readability, and informativeness
In our annotation study, we also asked the annotators to score PDFTriage, Page Retrieval, and Chunk Retrieval answers across five major qualities: accuracy, informativeness, readability/understandability, and clarity. We hoped to better understand the strengths of each answer for users in document question-answering tasks. In Table 3, we show that PDFTriage answers score higher than Page Retrieval and Chunk Retrieval across all answer qualities except for Clarity. Crucially, PDFTriage had the highest scores for Overall Quality and Answer Accuracy. For annotator agreement, we calculated an average Cohen’s kappa score of 0.584.
在我们的注释研究中,我们还要求标注者在五个主要质量方面对PDFTriage、页面检索和块检索的答案进行评分:准确性、信息量、可读性/易理解性及清晰度。我们希望更好地了解每种答案在文档问答任务中的优势。在表3中,我们显示PDFTriage的答案在所有答案质量方面得分均高于页面检索和块检索,除了清晰度。关键的是,PDFTriage在整体质量和回答准确性方面得分最高。对于标注者的一致性,我们计算了平均Cohen’s kappa得分为0.584。
In Appendix A, we provide a high-resolution breakdown of annotations for “Overall Quality” and “Accuracy” by question category. We find that PDFTriage tends to be stronger for categories like summarization, table reasoning, extraction, and figure questions which require multi-step reasoning across different parts of a document. Additionally, PDFTriage performs similarly to Page Retrieval and Chunk Retrieval on other more generalized reasoning tasks, such as text questions and classification.
在附录A中,我们提供了按问题类别细分的“整体质量”和“准确性”的高分辨率注释。我们发现PDFTriage在需要跨不同文档部分进行多步推理的类别中表现更为强劲,如概括、表格推理、提取和图形问题。此外,PDFTriage在其他更通用的推理任务上表现与页面检索和块检索相似,例如文本问题和分类。
6.3 PDFTriage需要检索更少的标记以生成更好的答案-PDFTriage requires fewer retrieved tokens to produce better answers
For the PDF document sample, the average token length of retrieved PDFTriage text is 1568 tokens (using the GPT-3.5 tokenizer). The average metadata length of textual inputs in document JSONs is 4,257 tokens (using the GPT-3.5 tokenizer).
对于PDF文档样本,检索到的PDFTriage文本的平均标记长度为1568个标记(使用GPT-3.5分词器)。文档JSON中文本输入的平均元数据长度为4,257个标记(使用GPT-3.5分词器)。
While PDFTriage utilizes more tokens than Page Retrieval (3611 tokens on average) and Chunk Retrieval (3934 tokens on average), the tokens are retrieved from multiple sections of the document that are non-consecutive. Furthermore, the sections used in Page Retrieval and Chunk Retrieval are often insufficient for answering the question, as indicated by lower answer quality scores on average for “Overall Quality” and “Accuracy”. However, simply concatenating all the document’s text together would not ultimately replace PDFTriage due to both context window limits and the need to perform multi-hop reasoning for document QA tasks. PDFTriage helps overcome this issue through the multi-stage querying of the document, retrieving and adding context as needed for different document QA tasks.
虽然PDFTriage使用的标记数量多于页面检索(平均每篇文档3611个标记)和块检索(平均每篇文档3934个标记),但这些标记是从多个非连续部分的文档中检索出来的。此外,页面检索和块检索使用的部分通常不足以回答问题,这反映在“整体质量”和“准确性”的较低得分上。然而,简单地将整个文档的文本拼接在一起并不能最终替代PDFTriage,因为存在上下文窗口限制,并且需要执行多跳推理来完成文档QA任务。PDFTriage通过多阶段查询文档克服了这一问题,根据不同的文档QA任务需求检索并添加上下文。
与方法相关的数据
{
"code": 200,
"data": {
"headers": [
{
"page": 2,
"bbox": [
237,
96,
449,
255
],
"text": "如何再次拿起书 [美]艾伦·雅各布斯 著魏瑞莉 译",
"type": "Header",
"contain_formula": false,
"font_size": 15.468750953674316,
"font_name": "STZhongsong",
"children": null
},
{
"page": 3,
"bbox": [
285,
123,
353,
163
],
"text": "目录",
"type": "Title",
"contain_formula": false,
"font_size": 22.680002212524414,
"font_name": "SimSun",
"children": null
},
{
"page": 3,
"bbox": [
99,
158,
383,
744
],
"text": "我们还能拿起书吗可以帮我开一份书单吗当我们阅读时,大脑在做什么书荒了怎么办从你最喜欢的作家那里模仿阅读请拿着笔读书电子书也是书从“读完了”到“读懂了”手机的诱惑废寝忘食为什么有些人不读诗不同的书,区别对待你为什么没办法看完整本书",
"type": "Header",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "MicrosoftYaHei",
"children": null
},
{
"page": 4,
"bbox": [
100,
62,
345,
362
],
"text": "你不可能读完所有的书嘘——别说话重读是浪费时间吗这本书很好,但我不喜欢阅读需要独处,也需要社交不期而遇当你第一次拿起书",
"type": "Header",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "MicrosoftYaHei",
"children": null
},
{
"page": 5,
"bbox": [
98,
88,
542,
200
],
"text": "那些讨厌看书,或者对阅读毫无兴趣的人,也许会觉得这本书索然无味。但是如果有谁曾体验过阅读带来的种种乐趣(愉悦、智慧、快乐)——即使这已是很久以前的事情,这本书就是为你们而写的。",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 6,
"bbox": [
218,
122,
420,
163
],
"text": "我们还能拿起书吗",
"type": "Title",
"contain_formula": false,
"font_size": 22.680002212524414,
"font_name": "SimSun",
"children": null
},
{
"page": 6,
"bbox": [
71,
194,
567,
746
],
"text": "有一次我正在书房阅读时,我十几岁的儿子走进来,歪着 [1] 头看了看我手里的书。那是莫提默·艾德勒和查尔斯·范 [2] 多伦的经典之作《如何阅读一本书》。“哦,老天,”他说,“去年老师要求我们读了这本书。也许我从中学到了一些阅读技巧,不过在那之后,我就再也不想看书了。”1940年,莫提默·艾德勒出版了《如何阅读一本书》,后来他说完全没想到这本书会迅速走红,并且常销不衰。虽然在某些方面艾德勒的阅读品味很“精英派”——他相信有些书是伟大的、最值得阅读的,这些书籍激励了他的一生——但是《如何阅读一本书》极好地继承了美国的平民主义传统,因为整本书背后隐藏的理念是:要想具备熟练阅读高难度文本的能力,你并不一定要支付高额的学费去接受大学教育;相反,你只需要一点儿指导——读一本传授阅读技巧和策略的书,然后从这里起步,按照自己的方式成为一个博学之人,让自己有能力去攀登人类精神财富的大山。而面对这座大山,艾德勒谦称他也不过刚刚从山脚起步。艾德勒的建议是,阅读的训练过程就像查尔斯·阿特拉斯的“动感压力”健身项目 [3] 一样,目的是为一般的美国人提供一个实际可行的方案,激发他们自身的进取精神。(《如何阅读一本书》中有一些劝勉的章节跟查尔斯·阿特拉斯的言论非常相似:“你只能依靠你自己的大",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 7,
"bbox": [
72,
66,
568,
717
],
"text": "脑,对眼前的文字反复加工,只有这样,你才可以从‘只能看懂一小部分’的状态逐步上升到‘能看懂一大部分’的状态。”这段表述跟查尔斯·阿特拉斯的“动感压力”健身法有异曲同工之妙,因为后者也强调健身要循序渐进,而不是用沉重的健身器材来“压出一块又一块肌肉”。)过去很少有美国人能上大学,而能够进入那些注重发展文学和艺术的大学的美国人更是少之又少。因此,在那个时代,为了提升自信,人们极其渴望得到艾德勒的指导。30年之后,美国的社会结构发生了极大的变化,因此艾德勒邀请查尔斯·范多伦帮他修改这本阅读指导手册。多亏美国政府在“二战”后通过了议案,决定为众多退役士兵支付大学学费,这大大提高了美国的大学生人口比例。有人可能会以为在这种情况下,艾德勒的指导大概就不那么有价值了。但是,艾德勒对此反驳说,大学只是致力于传播既成的事实,却忽略了对这些事实内容的理解,因此,美国人上大学的比例升高,并不意味着他们的阅读能力也随之提高了。而且,1940年后,人们的生活中出现了一件新事物:电视机。美国人的注意力变得更加分散,更加缺乏引导,阅读活动逐渐退出了人们的日常生活,甚至被视为反常举动,因此艾德勒认为他的书会历久弥新。艾德勒的这些看法当然是正确的。不过,要是当时他能预知美国在之后30年中的变化,他会说些什么呢?看到现在我们身边有这么多令人分散注意力的新事物,或许他也会非常失落地放弃阅读事业了。毕竟,在1972年,美国人能收看的电视台",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 8,
"bbox": [
72,
70,
567,
712
],
"text": "基本上不超过四个,仅有的几台电脑还都是庞然大物,被锁在大学或为数不多的大公司的地下室里。众多精英人士纷纷表达了担忧和感慨,但这并不能说明阅读正在走向衰落。在美国,仍有数以百万的人沉迷于读书,这一点从几百家大型连锁书店的存在就可以得到证明(尽管这些书店也正在努力维持生计),从图书销售网站亚马逊的巨大成功就可以得到证明,从奥普拉读书会的发展壮大就可以得到证明,还有全美教育协会最近一项关于美国民众阅读习惯的调查也表明,文学作品和其他长篇作品的阅读量出现了令人惊奇的 [4] 增长。再来看看这个:2008年1月,苹果公司的总裁史蒂夫·乔布斯接受了《纽约时报》记者的采访。采访中,乔布斯最关注的当然是苹果新产品的发布,不过他也乐意谈谈自己对其他事物的看法,比如说,亚马逊当时新推出的电子书阅读器。“且不说这个产品本身的好坏,事实摆在眼前,那就是人们根本不看书了。”他说,“去年美国有40%的人只看了一本书或者连一本也没看完。这个产品的研发概念从一开始就是错的,因为人们根本不看书了。”两年后,他发布了新产品——苹果平板电脑,并且强调了该产品与苹果公司新开发的网上书店之间的联系,以及这一产品在阅读报纸、杂志——当然了,还有书籍方面的卓越性能。我并不认为在2008年到2010年间,会自发地出现一大批苹果公司的潜在读者客户。",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 9,
"bbox": [
72,
71,
566,
708
],
"text": "我跟很多读者面对面地谈过,也收到过很多读者的来信:我书籍的读者们经常会给我发邮件或写信,而他们的教育背景、人生经历千差万别。就在几周前,我收到了三位读者的来信,他们读了我写的C. S.刘易斯 [5] 的传记:一封是一个加拿大的大学生发来的邮件,她在自己的博客上发表了一篇很长的文章,谈论对那本书的一些看法;一封是一个佛罗里达的高中生打印出来,然后寄给我的,是她对那本书满满一页的评论(总体来说她喜欢这本书,不过觉得有些章节难以理解);还有一封是一位纽约的老妇人寄来的很长的手写信,她半个世纪前曾经跟刘易斯通过信,所以想向我描述一下当时的情况。当然,这些交流都很有限,但是在与读者更加充分地交流后,我发现,尽管他们兴致颇高,却常常缺乏信心:他们不知道自己阅读时的注意力集中程度、谨慎程度和洞察力是否符合要求。这种不确定的感觉在每代人身上都有,只不过呈现方式不同。我尤其好奇的是被如今社会称为“最愚蠢的一代”的年轻人。不断有人声称,对同时存在的多种刺激物的沉溺使这些年轻人无法专注于某一事物,因此他们也就没有能力阅读那些大部头著作。有些年轻人对这种指责不屑一顾,但是大部分年轻人都或多或少地相信这是真的。在无数次被人指责没有能力阅读后,他们就懒得再做尝试了。这不只是十几岁、二十几岁的少年或青年的想法,我遇到过一些40多岁甚至更年长的人也怀有这种心态。他们当中的很多人说,自己以前会读书,不过因为习惯了在线阅读,注意力只能短暂集中,这让他们再也无法静下心,坐下来看完一本书了。他们坐立不安,时不时地打开",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 10,
"bbox": [
72,
71,
567,
740
],
"text": "手机,查看有没有新邮件,或是刷刷微博。正因如此,尼古拉斯·卡尔 [6] 才会写道:最近几年来,我一直有一种不舒服的感觉,觉得某些人或某些东西正在鼓弄我的大脑,重塑中枢神经系统,重组我的记忆。我的思考能力没有消逝(这一点我能感觉到),但它正在变化。我现在的思考方式已经与过去截然不同。当我阅读时,这种感觉最为强烈。全神贯注于一本书或一篇很长的文章,曾经是易如反掌的事,我的大脑能够专注于叙述的演进或论点的转折,我还曾一连数个小时徜徉在长长的诗行里。但如今情况变了。往往在阅读两三页后,我的注意力就会开始转移。我变得焦虑不安,失去了思路,并开始寻找其他事情来做。我感觉自己一直在努力将自己任性的大脑拽回到书本上,过去甘甜如饴的阅读事业已变成一场战斗。最后他十分悲痛地总结道:“我想念以前的大脑。”(在本书后面的章节中,我会详细分析卡尔所处的这种非常具有代表性的尴尬境地。)当然,所有人都能阅读,那些从来没读过书的人可以通过学习来获得阅读能力,而那些丢掉阅读习惯的人也可以再次培 [7] 养这种习惯。大脑具有令人惊奇的可塑性,不过训练大脑需要恒心和耐心。我明白,我这番“你能做到”的积极论调与艾德勒和查尔斯·阿特拉斯的言论并无二致,更不用说巴拉克 [8] ·奥巴马和巴布工程师了。但是美国人自学的传统不容小觑,尤其是将之与时俱进地应用于阅读活动时,效果更是不同",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 11,
"bbox": [
73,
71,
565,
741
],
"text": "凡响。艾德勒和范多伦书中那套阅读方法(“如果这本书属于第一种类型,请使用第三套阅读方法”)和强烈的法规式语气,其实并不太适合现代人的思维方式。艾德勒和范多伦是非常严格的督促者。他们的书中频繁出现的一个词是“责任”,而这个词的承担者基本上就是他们的读者。他们提醒我们,这本书可是很“实用”的,能够实现一些特定的目标,而且“在这一点上,这本实用书的读者们负有特别的责任”,如果“这本实用书的读者认可它提出的目标,并且认为书中推荐的那些方法是正确有效的”,那么他或者她就必须遵从这本书的指示。要是没有尽到这份责任的话,我们就会非常担心艾德勒和范多伦会如何处置自己。在《如何阅读一本书》中有一段很奇怪的话。艾德勒和范多伦谈论了关于“权威书籍”的阅读,他们所说的“权威书籍”并不只是宗教教义、经典,还包括那些在某个特定团体内拥有绝对权威的书。在讨论这类阅读活动的时候,艾德勒和范多伦再次打出了“读者的责任”这一旗号,并做了大肆渲染:一本权威书的读者有责任搞清楚这本书的意思,并在某种“真正意义”上认为它说得对。要是读者自己做不到,他就有责任求助于有能力做到这一点的人。这个人可以是神父或祭司,也可以是团队中的上级,或者是这位读者的教授。在任何情况下,读者都应该接受别人提供的理解方案。本质上,读者不能随心所欲地阅读,但是作为回报,他得到了一种满足感,这是在阅读其他书时可能永远也无法获得的感受。",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 12,
"bbox": [
72,
71,
568,
758
],
"text": "我从这段话的开头几句中读出了一种对“权威书籍”的怀疑态度,不过最后一句(“他得到了一种满足感,这是在阅读其他书时可能永远也无法获得的感受。”)让我有些惆怅,看起来艾德勒和范多伦并不是很介意动用这套权威。这种态度在他们强调《如何阅读一本书》的读者的责任时,体现得更加明显。若说《如何阅读一本书》的很多读者喜欢这种腔调的话,我并不会感到意外:正是这种言辞激烈的语句帮助读者增强了 [9] 毅力、强化了决心。(乔治·奥威尔曾经写过他的一位小学同学的故事,那位同学有一次考得很糟,考试结束后,他满怀懊悔地希望考前能被人用藤条打一顿,这样他就会更努力地复习了。)毕竟,在那些希望阅读更多书的人中,有一大部分人把阅读当作了一种提升自我的途径,多亏了他们,《如何阅读一本书》才会不断被重印至今。为了增加自己的知识储备,你当然可以读书,关于这一点,我在后面的章节里会具体谈到,但我想先谈谈其他问题。请暂时忘记正确的阅读方式,先问问自己为什么要阅读。首先,且最重要的原因是,读书能带来极大的乐趣,阅读是人类的一大乐事,而那种“动感压力”健身法式的阅读则完全忽略了这一点。莫提默·艾德勒的合著者查尔斯·范多伦可能已经意识到了,在《如何阅读一本书》中,有些章节太过强调“责任”,因此在1985年,他出版了《阅读的乐趣——鼎力推荐189位世界顶级作家及其著作》。这本书的封面上印有艾德勒的评价,还有著名编辑克里夫顿·费迪曼 [10] 的评论:“范多伦先生是少有的真正善于读书的人,他读书没有什么特定目的,纯粹是",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 13,
"bbox": [
71,
69,
567,
742
],
"text": "为了乐趣。他的作品激励着我们既深入又愉悦地发掘那些好书中无限多变的领域。”尽管这里强调了乐趣、激情和愉悦,但“读者的责任”这一符咒却很难消退,这一点在费迪曼自己的书中也有体现——《一生的读书计划》,这里的关键词 [11] 是“计划”。实际上,不管范多伦的导读多么富有激情,《阅读的乐趣》中仍然充斥着跟费迪曼一样行文富有条理的权威作家的名字,还有全书结尾处的那份“十年阅读计划”,其内容和选文顺序都“绝不仅仅是建议性质的”。现在,范多伦可能已经赢得了一些平民的支持,因为他在《阅读 [12] 的乐趣》2008年的修订版中,加入了J. K.罗琳,甚至是 [13] 卡尔·希尔森的名字——不过这两位作家最终能够入选这样一个本质上极富指导性、权威性的名单,还是有点儿奇怪的。这种自我帮助、自我提升的阅读模式似乎深深地植根于美国文化中:即使是极为体贴和仁爱的评论家迈克尔·德达 [14],在其著作《畅游书海》中也难抵诱惑地列出了一份包含16本著作的重要书单,并声称如果读者能认认真真地看完这些书,“你基本上可以了解世界上所有的文学作品”。真的是这样吗?“了解世界上所有的文学作品”,只要我读完这16本书就能做到?这么快就能见效?[这是美国人一直以来乐于相信的一类事情:基督教福音传道者,后来成为欧柏林大学第一任校长的查尔斯·芬尼,曾在1835年断言:“(宗教)复兴的正确方法与种植小麦、稻子的正确方法从哲学(以及科学)上讲是相通的。我相信,实际",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 14,
"bbox": [
71,
68,
568,
759
],
"text": "上 我 很 确 定 : 相 较 而 言 , 宗 教 复 兴 的 失 败 率 会 更 低 一 点儿。”种植小麦,劝说人加入基督教,向人们敞开文学世界的大门——做成这些事都需要合适的装备、恰当的技巧,并严格按照指示行事。]把艾德勒、范多伦和费迪曼等人的书当作卖弄学问之作,这样做很容易,但是正如前面谈到的,美国的广大读者群,或者说其中很大一部分人无法直接获取阅读的乐趣,而是非要用一堆责任义务来分割本来可以得到的乐趣。照他们的想法来看,那些未被证实对自己有益的书将会受到质疑——至于“为了乐趣而读书”,或者“乐趣”本身,则从道义上来讲就是不合理的。托马斯·福斯特的作品《如何像教授一样阅读文学作 [15] 品》和《如何像教授一样阅读小说》正是利用了人们的这种焦虑心理:两本书都暗示受过良好训练、公认的行业专家能够最好地完成阅读活动,并含蓄地承诺这种专业技能至少有一部分是可以被传授给普通读者的。作为一名文学教授,我必须承认,第一次看到福斯特的书时,我心想:“像教授一样读书?天哪,那可就糟了!”(不过福斯特设想的当然是位完美的教授。)在学术性阅读这一问 [16] 题上,我非常赞同小说家扎迪·史密斯在几年前接受采访时表达的观点:总的来说,我觉得我的学生时代,尤其是临毕业的那一年,真的是我一生中最幸福的时光。但是——但是!我觉得学校生活中有很多事是极为烦闷和荒谬的,让人难以忍受。有太多的个人生活经历被隔断在学校的院墙之外。尤其是在",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 15,
"bbox": [
74,
543,
564,
729
],
"text": "[1] 莫提默·艾德勒(Mortimer J. Adler,1902—2001):美国哲学家、作家、著名编辑。——译者注[2] 查尔斯·范多伦(Charles van Doren,1926— ):美国作家、编辑,编辑修改了艾德勒于1940年出版的《如何阅读一本书》,该书1972年出版的新版由两人共同署名。——译者注[3] 查尔斯·阿特拉斯(Charles Atlas,1892—1972):意大利裔美国健身专家。“动感压力”是阿特拉斯自创的一套运动课程,分为12课和1节终生课程,配以照片指导,并鼓励练习者交流提问。———编者注",
"type": "Footnote",
"contain_formula": false,
"font_size": 12.375000953674316,
"font_name": "SimSun",
"children": null
},
{
"page": 15,
"bbox": [
74,
71,
563,
520
],
"text": "英语系,那种对严肃、专业的过度追求,还有对本该模棱两可、难以归类的阅读行为的严格监管,让我觉得很难适应……我一直觉得英语系中弥漫着一股失望之情。学生们觉得:我们这些聪明人被召集到了这里,准备聆听教诲,可所学的竟然就是……这种东西?小说?它们实在是……太没用了……这种心态让我很沮丧。有些人对小说的态度太令人尴尬了,他们是那么想从这些小说中得到别的东西。但是不管这种获得专业技能的承诺对一部分人来说多么具有吸引力(同样诱人的还有艾德勒和范多伦给出的与之类似的步骤式指令,以及费迪曼提供的由经过检验的权威书籍组成的填鸭式书单),对另一部分人来说,这只会让他们觉得阅读是一种苦役。我儿子就是其中之一:正是《如何阅读一本书》飘散出来的种种责任、义务和美德的芳香把他吓跑了。还有很多人跟我儿子一样,其中有对阅读缺乏自信的人,也有从来都不读书的人,还有不再读书并对此心怀愧疚的人——尤其是那些沉迷于网络世界的人。所以在此我想提出一种完全不同的对阅读的解读模式。",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 16,
"bbox": [
74,
65,
565,
739
],
"text": "[4] “美国国家艺术基金会的研究报告《阅读势头见长》记录了美国近代文学史上出现的重大转折点。调查结果显示,20多年来,美国成人群体的文学阅读量第一次出现了增长。在持续几十年的下降趋势后,此次面向全美人口所做的广泛调查所涉及的各个年龄群体的阅读量实际上都出现了明显的增长。”这份报告所依据的各项调查都是在2008年进行的。——原注[5] C. S.刘易斯(Clive Staples Lewis,1898—1963):爱尔兰裔英国知名作家及神学家。1950年,刘易斯出版了奇幻小说《狮子、女巫和魔衣柜》,此后的6年里,他继续以故事中的纳尼亚王国为主题,每年出版一本小说,共同组成了奇幻文学巨著《纳尼亚传奇》。他被誉为“最伟大的牛津人”,也是20世纪最具领导地位的作家兼思想家之一。——译者注[6] 尼古拉斯·卡尔(Nicholas Carr,1959— ):美国科技作家,原《哈佛商业评论》执行主编,成名作为《IT不再重要》。作品《浅薄》入选了亚马逊畅销书百强,于2010年底在中国出版,此书引发了“互联网是否让人类变得越来越浅薄”的热烈讨论。——译者注[7] 值得注意的是,尽管存在着我之前提到过的种种担忧,但是大多数人仍对阅读颇有好感,而且根据西北大学社会学家的一组研究报告,人们都满心希望以后能增加阅读量:“90%的人相信阅读是‘有效利用时间的方式’。他们觉得自己本该读得更多,因为几乎没有人认为阅读‘是一件难事’。他们期待着以后能多读些书。当被问到‘你觉得未来的几个月到几年内,你的阅读量是会增加、减少还是保持不变?’时,45%的受访者认为会增加,3%的受访者认为会减少,还有51%的受访者认为会保持不变。人们尤其希望阅读更多具有教育意义或能够改善生活的书,比如说非虚构类的文学作品、报纸,还有《圣经》 。”一项英国的调查表明,人们确实相信他们的阅读量增加了。“尽管阅读一事面临着来自各类新媒体的挑战,而且人们的休闲方式也越来越多,但是几乎没有人觉得他们的阅读量比5年前有所减少。大部分受访者(约占80%)都认为自己的阅读量没有变化或有所增加。”——原注[8] 巴布工程师:英国著名卡通节目《巴布工程师》的主人公,带领小伙伴们建造美好的城市。他们的口号是:“我们一定行!”——编者注[9] 乔治·奥威尔(George Orwell,1903—1950):英国小说家、散文家。——译者注[10] 克里夫顿·费迪曼(Clifton Fadiman,1904—1999):美国作家、编辑、电视和电台节目主持人,其作品《一生的读书计划》已在中国出版。——译者注",
"type": "Text",
"contain_formula": false,
"font_size": 12.375000953674316,
"font_name": "SimSun",
"children": null
},
{
"page": 17,
"bbox": [
71,
67,
569,
372
],
"text": "[11] 1960年,费迪曼出版了这本书,当时的书名是“克里夫顿·费迪曼一生的阅读计划”。——原注[12] J. K.罗琳(Joanne Kathleen Rowling,1965— ):系列小说《哈利·波特》的作者。——译者注[13] 卡尔·希尔森(Carl Hiaasen,1953— ):美国小说家、专栏作家,其代表作《脱衣舞娘》《我爱猫头鹰》都曾被改编为同名电影。——译者注[14] 迈克尔·德达(Michael Dirda,1948— ):美国书评家,1993年获得普利策新闻奖。——译者注[15] 这两本书均已在中国出版,中译本书名为“如何阅读一本文学书”和“如何阅读一本小说”。——编者注[16] 扎迪·史密斯(Zadie Smith,1975— ):英国小说家,代表作有《白牙》《论美》等。——译者注",
"type": "Text",
"contain_formula": false,
"font_size": 12.375000953674316,
"font_name": "SimSun",
"children": null
},
{
"page": 18,
"bbox": [
196,
122,
442,
164
],
"text": "可以帮我开一份书单吗",
"type": "Title",
"contain_formula": false,
"font_size": 22.680002212524414,
"font_name": "SimSun",
"children": null
},
{
"page": 18,
"bbox": [
72,
196,
566,
748
],
"text": "每年会有好多人请我帮忙(一般来说都是我的学生,不过也有朋友和熟人,甚至还有不知道怎么得知了我电子邮箱的陌生人),让我为他们列出阅读书单。“亲爱的雅各布教授,您能不能给我推荐一些今年夏天读的书?”或者是“亲爱的教授,您认为所有受过教育的人都应该读的10本最重要的书是什么?”我不喜欢第二个问题的原因应该显而易见了,不过对于第一个问题,我实在是一点儿也烦不起来,因为它实际上是在以问题的形式表达赞美和恭维。尽管如此,我从来都不会接受这类请求。原因有两个,都关乎我所认为的阅读的价值与乐趣。第一,如果提问者只是想要一份西方文学名著的书单(《伊利亚特》《神曲》《哈姆雷特》《失乐园》《卡拉马佐夫兄弟》),他们随便在哪儿都能找到,而且很有可能已经知道那些书单的内容了。所以,应该假设他们是想让我推荐一些其他的书,不过我从来都不清楚,或许他们自己也不知道,他们想要的究竟是什么。我的感觉是,他们想要的要么是那些对我来说非常重要的书(从这个角度来看,这种提问的确是对我的恭维),要么是那些被期刊杂志称为“被遗忘的杰作”的书。但是满足后一个标准的书实在是太多太多了,而仅仅因为我自己喜欢一本书,就认为别人也会觉得它有意思、有帮助,这种想法是毫无根据的。别人的兴趣、爱好或者个人需求可能跟我并不一样。",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 19,
"bbox": [
73,
67,
566,
737
],
"text": "现在,如果有人对我说:“这里列出了我最喜欢的10本书,你能帮我推荐其他几本我可能会喜欢的书吗?”我也许会更愿意,也更有准备来回答他的问题。但是这种情况基本上从没出现过,真是太遗憾了:我极为讨厌人们索要那种笼统的、抽象的、脱离语境的书单,但极为乐意向我认识的那些与我兴趣、品味相投的人推荐书籍。不久前,当我阅读尼尔·斯蒂芬 [1] 森的长篇科幻小说《飞越修道院》时,老是会想起一位朋友,他对这种书非常感兴趣。所以我一看完它,就立刻冲到附近的书店又买了一本,送到他家,并极力推荐,请他尽快开始阅读。当然,我并不确定朋友最后会不会喜欢这本书,但是我知道他会对书中的故事情节极为感兴趣,而且,最重要的是,我知道我们一定会就斯蒂芬森的故事展开一些愉快的谈话。正因如此,1907年的诺贝尔文学奖得主、英国作家鲁德亚德·吉卜林曾说:“除非一个人非常了解另外一个人,否则他就无法向对方荐书,即使是推荐最好的书。如果一个人很想看书,他应该虚心求教于那些了解他人生经历的年长者,并听取他们的建议,尤其重要的是,跟对方多聊聊当初最吸引自己的那些书。”有了这样的友情和共同爱好后,荐书是一件乐事,否则它会立刻成为一项沉重的责任(而且很有可能是毫无意义的责任),而我并不喜欢把阅读跟沉重的责任搅到一起。在很多情况下,这些请求与提问者实际阅读的内容之间并没有什么关系,他们只想读完书,要的只是结果——他们渴望说出“好了,现在我可以把这本书从清单上画掉了”之类的话。 [2] 在理查德·罗德里格斯闻名于世的自传《如饥似渴》中,他描述了自己曾经受到这种求知冲动驱使的经历。“小学",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 20,
"bbox": [
72,
68,
566,
754
],
"text": "四年级的时候,”他写道,“我开始着手实施一个宏伟的阅读计划。”他请老师们为他列出了“最重要的书”,然后就开始遵照这些书单一本一本地读,完全不考虑这些书的真正价值在何处。我决定在笔记本上记下读完的那些书的中心思想。读完《鲁滨孙漂流记》后,我记下这本书的中心思想是“学会独立生存很重要”;读完《呼啸山庄》后,我记下了要警惕“情绪失控”的危险。重读这些简短的道德评价常常会让我感到泄气,我无法相信这就是阅读的真正价值所在。但在后来的很多年中,这是我获取书籍教育意义的唯一途径。当然,成年读者不会再像小时候的罗德里格斯那样单纯了,这一点千真万确:那些向我索要书单的人是不会把书的中心思想写在笔记本或学习卡片上的。但是他们和罗德里格斯的区别其实也没有想象中的那么大:他们有着同样的责任感。比如,罗德里格斯阅读柏拉图《理想国》时的体会对很多年长者来说并不陌生:“我得时不时地看看封面上的评论,提醒自己这本书是讲什么的,不过……我读完了这本书中的每一个字。当我读完最后一个字的时候,我很坚定地告诉自己,我看完《理想国》了。带着一种强烈的自豪感,我郑重其事地从书单上画掉了柏拉图的名字。”所以我经常谢绝向别人荐书的原因之一,就是不想助长这种思维习惯。而这种否定中也有肯定的一面,那就是我一贯主张的基本阅读准则,或者可以说是一条不可更改的准则:随兴而读。我是从评论家和诗人兰德尔·贾雷尔 [3] 那里学到这条",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 21,
"bbox": [
72,
70,
562,
754
],
"text": "准则的,他曾经遇到过一位学识渊博的学者兼评论家,后者每年都要重读一遍吉卜林的小说《吉姆》。贾雷尔对此所做的评论是:这位评论家说他每年都要读一遍《吉姆》。他读《吉姆》的动机很简单,就是出于兴致:不是为了教育别人,也不是为了批评挑错,只是出于热爱——他读这本书,就跟当初吉卜林写这本书一样,只是因为他喜欢,他想要读,难以克制这份兴致。对他来说,读这本书不是为了准备一场演讲或者写出一篇文章,阅读本身就是结果。他读这本书并不是为了从中获取什么,而只是想读它。这不正是艺术作品对我们的要求吗?里尔克说过,艺术作品一直都在对我们传达一种理念:你必须改变你的人生。它要求我们也把事物本身作为结果,而不是过程或工具,也就是说,我们要了解并热爱事物本身。在人生中那些积极进取、渴望向上和坚强有力的时刻,这种改变也许是超出了我们自身能力的;但当我们出神地读、听、看时,这种改变绝对是我们力所能及的。在这种时刻我们能够做出选择,选择让我们的一部分天性顺从其自然的欲望。所以,最后我要对你说一句话:随兴而读!随兴而读!乍看上去,贾雷尔的这段话可能是自相矛盾的:他先是提出要为了读书而读书,接下来又说,读书是因为书要求“你必须改变自己的人生”。不过这种语言上的矛盾只是表面。那些无须理由就应当去读的书恰恰是在要求我们不计较好处地改变自己的人生;它要求我们停止计算得失,它要求我们完全出于快乐和兴趣去做一件事,而不是因为在我们评估各种行为价值",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 22,
"bbox": [
71,
66,
567,
732
],
"text": "的大脑数据表或记账簿中,这件事是有一定价值的(本杰明·富兰克林就有这么一本账簿 [4] )。在《如何阅读一本书》的开篇,艾德勒和范多伦解释,人们阅读的首要目的是获取信息和增长知识,但是接着他们又有些抱歉地补充道:当然,除了获取信息和增长知识外,阅读还有其他的目的,那就是娱乐消遣。不过,本书将不会涉及“为乐趣而阅读”的内容。这种阅读方式,不需要什么努力,也没有任何规则。每个认识字的人只要愿意,都可以从阅读一本书中得到乐趣。但是理查德·罗德里格斯的故事却让我有些怀疑上述说法。在我看来,这一点并不难理解:小的时候,我们总被灌输这样的观念——阅读对你有多么大的好处,阅读能带来多么丰富的营养和充足的信息,所以阅读不可能是愉快的,为了乐趣而阅读从根本上来说就是不对的。艾德勒和范多伦选用的“娱乐消遣”一词表现出了他们的这些怀疑。与我刚才所用的“乐趣”一词相比,“娱乐消遣”带有一层轻视,而且前面常常加上“仅仅是”。格雷厄姆 [5] ·格林把自己作品中自认为称得上是文学的虚构作品叫作“小说”,剩下的那些紧张刺激的故事,例如《斯坦布尔列车》和《布赖顿硬糖》,则被他称为“娱乐作品”。而“乐趣”一词的含义更加宽泛:既有罪恶的快乐,也有永久的快乐。艾德勒和范多伦不想惹上麻烦,只是做了简单的区分,将“娱乐消遣”当作没有价值的部分,而把信息和知识当作与",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 23,
"bbox": [
71,
69,
568,
724
],
"text": "之对立的高尚部分。但是这样划分阅读目的会让你无法理解乐趣的含义,从而在乐趣到来时对它产生误解。所以我对那些请我推荐书目的人说:看在上帝的分儿上,读书不是给大脑吃有机蔬菜,更不是(这个比喻稍微有些抽象了)坐上“思维健身器”逐字逐页地阅读,仿佛正盯着卡路里的消耗数值——这种辛苦费力的运动会让你在征服了《米德尔 [6] 马契》后获得一些不甚愉快的成就感,但这根本就不是阅读,而是C. S.刘易斯说的“社会与道德保健”。在刘易斯看来(我也非常赞同他的这一观点),当批评家,尤其是被他称为“警惕派”的成员们说服其他人他们就是阅读活动最合适的监护者以及应该读什么书的最佳评判者时,上文提到的情况就会应运而生。刘易斯写这段话的时候,英国 [7] 的“警惕派”首领是他在剑桥大学的同事F. R.利维斯; [8] 而在我所处的时代,没有人比哈罗德·布鲁姆更像“警惕派”成员了。布鲁姆写了一本书,书名是“如何读,为什么读”,不过,它其实应该叫“读什么,思考什么”。这本书是由很多小章节构成的,分别谈到了布鲁姆认为可以当作文学评判标杆的小说、故事和诗歌等。在这些章节里,布鲁姆只是告诉你每部作品的重要之处,并用概括性的语言解释了作品的含义。虽然在“概述”部分中,布鲁姆给出了一些看起来具有操作性的建议,不过综合整本书中的建议,他就是在说“照我说的去做”。",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 24,
"bbox": [
71,
70,
569,
737
],
"text": "布鲁姆难以容忍那些想在非经典书籍上花费精力的人,语气听起来就像他已经有了一套自己的宗教违禁书单。看看这一段吧。2003年,他说当代美国作家中只有四位“值得称道”,他们是菲利普·罗斯 [9] 、托马斯·品钦 [10] 、科马克·麦卡锡 [11] 和唐·德里罗 [12] 。当然,布鲁姆并没有暗示,其他没那么优秀的作家的作品就不应该读——只不过读后面这些作品就是在浪费我们的时间。(这倒是引出了一个很有意思的问题:为什么布鲁姆要在 [13] 《如何读,为什么读》一书中提到托妮·莫里森的《所罗门之歌》呢?很显然,按照他对当代美国小说家的看法,莫里森并不算是一流作家。实际上,他虽然赞同莫里森有一定的才能,却并没有直接赞扬她的哪一部作品——他只是提到比起她的《宠儿》来,他更喜欢《所罗门之歌》,他还这样预测了她的职业发展动向:“她的实力很强,我敢说她将来一定会有大成就。”真是个含糊其词的家伙!)由此我们大概可以了解对于《哈利·波特》系列小说大受欢迎一事,布鲁姆该有多么不舒服。在这个问题上,布鲁姆并不够理智。举个例子,他是这么记录自己第一次阅读J. K.罗琳作品时的感受的:“在阅读的过程中,我发现每次小说中的人物开始走路时,作者都会写‘迈开双腿’。于是我开始在一个信封的背面记下这个短语出现的次数,在记录了几十次之后,我就不再看这本书了。”“几十次”到底是多少次呢?我想至少得是二三十次吧。也就是说,布鲁姆在《哈利·波特与魔法石》的某些章节(或者是半本书?大半本书?)中看到同一个",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 25,
"bbox": [
72,
70,
567,
737
],
"text": "短语出现了二三十次,这就要求这本书里包含不下二三十次人物走动的场景。但我不会再探讨这个问题,我并不想鼓励读者自己去数一遍,更不是觉得如果我比布鲁姆少数了二十次,就更接近真实结果。古代雅典人将人类分成两个群体,一个群体拥有极高的智慧和美德,另一个群体则没有这些天赋,也就成为被嘲笑与被奴役的对象。当布鲁姆阐述他对阅读的这些观点时,他的语气非常像古代雅典人。他直截了当地表示那些读《哈利·波特》的人恐怕不会,也不可能去读其他类型的书。“有一大群《哈利·波特》的读者是肯定不会去读那些层次更高的作品的,比 [14] 如肯尼斯·格雷厄姆的《柳林风声》,或是刘易斯·卡 [15] 洛尔的《爱丽丝梦游仙境》。”在另外一段话中,他写道:“读《哈利·波特》并不能引领我们的孩子去读吉卜林的经典儿童文学作品《原来如此》和《丛林之书》,更不会引领 [16] 他们去读瑟伯 的《十三座钟》、格雷厄姆的《柳林风声》,或者是卡洛尔的《爱丽丝梦游仙境》。”这些极为斩钉截铁的论断,是他在2007年接受《新闻周刊》杂志的采访时,针对《哈利·波特》系列的热销所做的:“我觉得这是世界人民阅读能力的极大衰退。”布鲁姆极为严肃地使用了“阅读能力”这个词,他怀疑那些读《哈利·波特》的人并不是真的在读书。在他看来,J. K.罗琳的读者们不算是真正的读者,他们从她书中获取的主要好处只不过是“能暂时从屏幕前解脱出来”,这样他们“可能就不会完全忘记翻书页的感觉,翻任何一本书的感觉”。但是如",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 26,
"bbox": [
71,
68,
568,
737
],
"text": "果他们看完这本书之后永远也不去阅读“层次更高的作品”,这么做还有什么益处呢?“假如,你实在没办法接受劝说去读更好的书,那么J. K.罗琳的书也可以凑个数”——不过,说实话,“罗琳的书又有多少实际的教育意义呢?……如果一本书不能丰富充实你的思想、精神或者人格,那为什么还要读它呢?”确实如此,为什么不继续待在屏幕前面呢?如果这就是你所擅长的事情,如果你并不拥有极高的智慧。 [17] 2000年8月,布鲁姆在与雷·苏亚雷斯一起参加吉姆·莱勒 [18] 主持的新闻访谈节目时,强调了自己的这一观点 。 苏 亚 雷 斯 评 论 道 : “ 看 来 你 是 没 办 法 接 受 有 人 这 么说,‘好吧,至少他们在读书’,不管他们所说的是成人还是孩子。”布鲁姆回答道:“雷,他们并不是真的在读书。他们的眼球扫过书页,他们翻过每一页,但他们的思维已经被陈词滥调所麻痹。没人对他们提出要求。没有……他们没有发生任何变化。他们被一种你所说的非现实或者回避现实的事物所控制。”最近《华盛顿邮报》引用了一位叫埃里克·威廉森的教授对他学生所下的论断:“教室里几乎每个学生都声称斯蒂芬· [19] [20] [21]金是比唐纳德·巴塞尔姆、威廉·沃尔曼更优秀的作家,甚至在英语系中也是如此。这些学生并不为阅读低层次的作品感到羞愧。”让我们先不谈斯蒂芬·金跟巴塞尔姆、沃尔曼孰优孰劣(我不知道威廉森教授是否对他在这件事上面的意见做过解释),只是考虑一下,我们是不是真的希望人们带着羞愧感去读巴塞尔姆、沃尔曼或者其他人的作品",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 27,
"bbox": [
72,
69,
568,
758
],
"text": "——不是因为他们沉迷于《死去的父亲》或是觉得《起起伏伏》写得好,而是因为他们想让别人看到自己在读这样的书, [22]而一旦威廉森教授发现他们手上拿着一本《狂犬惊魂》,就一定会对他们大加羞辱。极为势利而又才华出众的评论家德怀特·麦克唐纳 [23] 所说的一段话中包含着更多的智慧。他自称是一个“保守的无政府主义者”:“嗯,我是说,作为一个无政府主义者,我并不想把人们掌控在自己手中,强迫他们接受某种文化。我认为他们应该做出自己的选择。如果他们想去博物馆或者音乐会,那没问题,但是他们不应该被诱导去做这些事,或者因为做这些事而蒙羞。”在我看来,布鲁姆的论调只会对读者产生两种影响:其一是让他们扬扬自得——“是的,我,还有其他少数几个像我一样的人,读的是正确的作品”。其二是吓坏他们——“我怎么可能达到那么高的标准呢?”这两种反应都与真正的阅读无关。在这个问题上与布鲁姆意见相左的刘易斯设想了一群受过教育的成年人在接受了“警惕派”的良好调教后,扬扬得意地讨论着最近所读之书的情景,“可是唯一真正亲近文学的人,却是屋后卧室里的那个正在读《金银岛》的小男孩。他藏在被窝里,借着手电筒的光亮看书。”(这孩子读的也可能是《哈利·波特》。)说到这儿,有一条来自另外一个读者阵营的信息非常值得提及。美国LCD Soundsystem(液晶音响系统)乐队的主唱詹姆斯·墨菲谈到了他自己的阅读经历:“我真的很想写一部专著为‘装模作样’这个词正名……我觉得这个词已经沦落得像‘讽刺’一样了。就是这种以偏概全的词语解释将人们与有",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 28,
"bbox": [
72,
68,
567,
750
],
"text": "趣的感受、文化体验以及可能会发生的苦恼远远隔离开来。装模作样也可以带来其他结果。你知道吗?我第一次读《万有引力之虹》,是因为我觉得这会让我显得比较有个性。这就是我最初的动机。但是现在那本书我已经读过6遍了,我觉得它非常有趣、非常棒,我理解了书中的意思。有时候你不能害怕丢脸。”年轻人常常通过装模作样来展示他们想成为什么样的人,他们可能在有限的范围内发现了一些好的事物,然后他们就用自己有限的知识和经验竭尽全力去追求这些事物。他们看到了敬佩或者在某些方面吸引他们的人,然后就开始模仿这些优秀之人的各种喜好。这种模仿会造成越来越多的装模作样,但在很多情况下,装模作样最终成了现实:我们所渴望拥有的品味常常会成为我们自己的品味。(对威士忌、香烟、毒品、羊杂碎,还有书籍的品味都是如此。)“成就来自模仿”这句话是真的,而且非常重要。“装模作样也可以带来其他结果。”这句话充满了智慧。然而我们确实也需要最终摆脱装模作样,因为有些事情,发生在小罗德里格斯身上是情有可原,甚至令人感动的,但发生在成熟的成年人身上,却只会让人讨厌。一个孩子不为了向任何人炫耀,只是带着纯粹的热情和兴趣去读书,这很美好。刘易斯也是因为这一点才会认同人们阅读并不深奥的通俗书籍。 [24] 在他之前,G. K.切斯特顿也抱有同样想法。切斯特顿生活在维多利亚时代,他为当时大受欢迎的廉价惊险小说辩护。“我认为,再找不到哪本书有着比当今年轻人热衷的底层文学更可笑夸张的荒诞情节了。”切斯特顿承认这些书并不属",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 29,
"bbox": [
72,
69,
567,
745
],
"text": "于真正意义上的“文学”,因为“在一个想象的世界里,几个虚构的人物不受干扰地上演故事,这样的传统比上流艺术遵循的法则更深刻,更古老。我们每个人小时候都曾编造过故事,幻想过戏剧性的角色,但我们从来没想过要去认真研究巴尔扎克的作品,然后修改自己脑子里的剧本”。在很多方面我很赞同布鲁姆的意见,对他长期以来坚持推崇最优秀的小说和诗歌心存感激,但就上述问题而言,我坚定地站在刘易斯和切斯特顿这一边。去读那些能带给你快乐的东西(至少大部分时候能带给你快乐的东西),且不要怀有任何愧疚。即便你是那种少见的,只能从人们称之为巨著的作品中获得乐趣的人,也不要只把这类书当作你唯一的精神食粮。如果你天天都去最高档的餐厅吃饭,也会腻味的。巨著的伟大之处有一部分在于它们对读者的要求:它们的含义不容易被解 [25] 读,也不容易把握。诗人W. H.奥登曾经写过:“一个人无须每天都花费精力去解读一首伟大的诗歌,这是不太必要的。真正的杰作应该留到‘精神的盛大节日’再读。”留到我们自己的圣诞节或者复活节,而不是每个寻常日。值得注意的是,在小罗德里格斯看来正确而又严肃的事情(阅读名作,并且只读名作),却被奥登视为“不必要”。这其实并没有那么矛盾。“不必要”的并不是名作本身,而是这样的想法:在任何时候,我作为一名读者,都应该准备好,达到这本书对我的要求,迎接挑战去读懂它。这些挑战对还没有做好准备的读者(他们可能10岁、20岁,也可能60岁)来说重达千钧,结果就会导致阅读变成我之前提过的如“坐上思维健身器”一般痛苦的经历。谁会喜欢这样的经历呢?",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 30,
"bbox": [
73,
72,
567,
732
],
"text": " [26] 在沃尔特·肯的自传《精英教育的迷失:一个优等生所受的不良教育》一书结尾,他回忆起自己刚从普林斯顿大学毕业时读到的一本书。在此前的人生中,他只是为了取悦他人而读书,这些人主要是他的老师。过去的他就是一个愤世嫉俗版的罗德里格斯,只把阅读当作一种能够获取其他好东西的工具。(“我依赖自己模仿权威人物的能力,不断重复他们的思想,就像那是我自己得出的结论一样……学习除了是一种猎取别人思想的途径外,还是什么?智慧不就是狡猾地猎取别人的思想吗?”)但是尝到甜头后,他看到了这种行为的空虚,他的所有理想瞬间破裂了,这让他几乎完全崩溃:“我的文化水平在提高,但是我的思想却丧失了对外延世界的感知能力,退回到了愚蠢无知的状态。”但正是在这个时刻,当再没人命令他或期望他做任何事时,他随手拿起《哈克贝利·费恩历险记》看了起来,然后他又看了《远大前程》。就是这样:姗姗来迟、磕磕绊绊、极其偶然又非常难以置信,我的教育终于开始了。我不知道它能带给我什么,它能赢得谁的赞许,也不知道它需要多久才能完成(我心里有个声音说,一辈子),但是这一次,我破例没有关注这些问题。我独自一人待在房间里,眼睛布满血丝,筋疲力尽,忘记了对自我提升的追求,遗忘自我,只想读书。我不再想填补空白,只想把自己当成一片空白,等待被这些内容来填补。他最后说:“我只想看看这些作家是怎么想的。”人生中第一次,沃尔特·肯在随兴而读。",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 31,
"bbox": [
74,
691,
565,
742
],
"text": "[1] 尼尔·斯蒂芬森(Neal Stephenson,1959— ):美国著名赛伯朋克流派科幻作家。1992年出版的《雪崩》是他迄今为止最重要的作品,也奠定了他赛伯朋克宗",
"type": "Footnote",
"contain_formula": false,
"font_size": 12.375000953674316,
"font_name": "SimSun",
"children": null
},
{
"page": 31,
"bbox": [
72,
69,
567,
669
],
"text": "无论何时,选择做一个自由阅读者,开始这种全新的生活,都为时不晚。肯的自传出版没多久后,凯瑟琳·沙因 [27]在《纽约时报》上发表了一篇精彩的文章,称自己是一名“少年文盲”,意指她少年时期中止了阅读,尤其是文学阅读,直到成年后才重新开始。她在文中写到,她曾经因为找不到她喜欢读并能一直读下去的书而感到沮丧。“有个柜子里放着我前男友留下的东西,我想起来其中有一个包,里面有一本查尔斯·狄更斯的《我们共同的朋友》平装版,那是我前男友最喜欢的书。几天之后,我从这本细腻优美的书中抬起头,暗骂自己以前浪费了太多时间,睿智的上帝早已经清楚地为我指明了接下来的人生应该如何度过,那就是读狄更斯的书。”对沙因来说,这是一个“关键时刻”,而且“要不是我以前那么无知的话,这一刻可能也不会发生”。也就是说,当她做好准备的时候,她遇到了一大批精彩的好书——这个时候她能够理解它们提供给她的信息。“第一次读《哈克贝利·费恩历险记》的时候,我35岁。上个月,我第一次读了《我的安东尼娅》,这真的是一种恩典。要是……我14岁的时候就已经读过《哈克贝利·费恩历险记》了,我还会在35岁的时候重读一遍吗?也许吧,但是那样就不会有身为成年人第一次阅读这本书时的绝妙感受了。”所以好书正在等待着你。这一点你大可放心:当兴致来临时,它们会为你做好准备。",
"type": "Text",
"contain_formula": false,
"font_size": 16.49250030517578,
"font_name": "SimSun",
"children": null
},
{
"page": 32,
"bbox": [
72,
87,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 444
444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











