





自动驾驶统一框架UniAD
- 摘要
- 方法
- 结果
论文地址:
https://arxiv.org/pdf/2212.10156.pdf
论文代码:
https://github.com/OpenDriveLab/UniAD
摘要
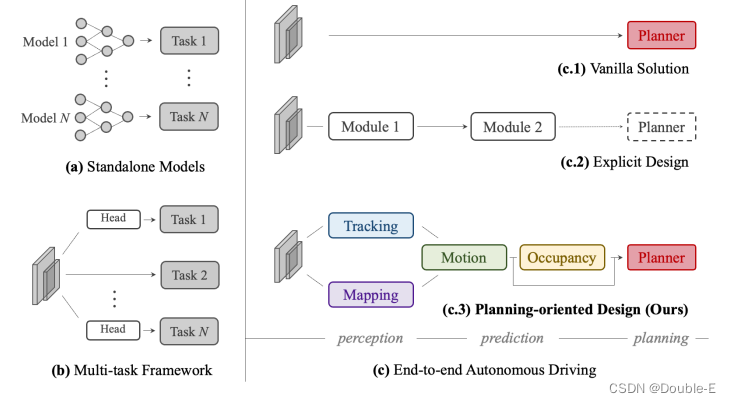
当前自动驾驶主要有两种模型训练方案:(1)一个任务一个模型,这种方法性能一般会更好,如Fig.(a)(2)多任务网络,通过共享backbone,添加多个预测头实现多个任务,这种方法会节省计算资源,如Fig.(b),但是可能会受到累积错误(我的理解是比如跟踪的稳定性与目标检测的准确性是有关系的)或者任务之间的干扰影响(任务与任务之间),因此作者希望设计一个统一的有效框架(UniAD, Unified Autonomous Driving),将整个自动驾驶的驱动任务合并到一个网络中,通过合理的设计,每个模块发挥最大的优势,实验在nuScenes数据集进行了验证,各个任务上都超过了之前的sota水平。
方法
pipeline如下,包含四个decoder-based的transformer感知和预测模块,最后是一个planner,管道之间的各个部分通过query Q来实现连接:
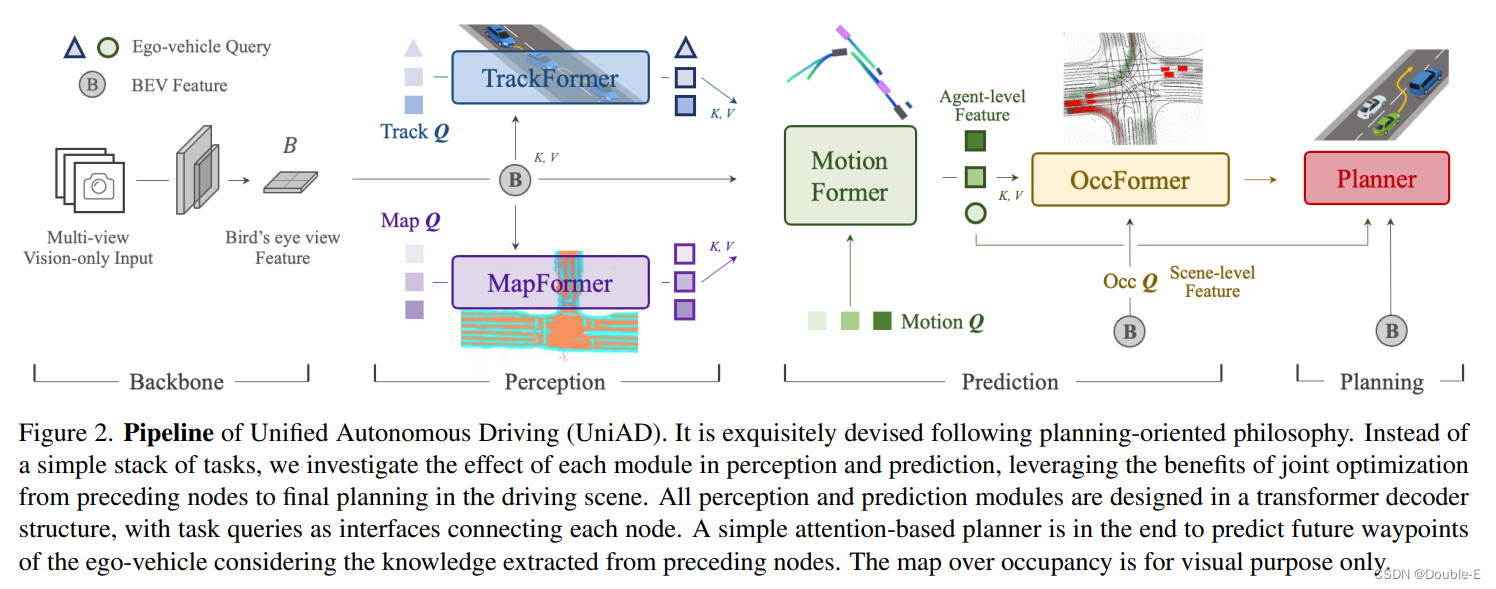
(1)backbone对输入的多视角images提取特征,然后使用BEVformer的编码器将perspective feature转换成BEV(bird’s-eye-view) feature(注意没有使用encoder部分)
(2)感知部分:TrackForme的可学习嵌入(track queries)从BEV feature的agent信息中获得,然后进行检测和跟踪,MapFormer将map queries作为道路元素,比如车道和分隔线,然后对map进行全景分割
(3)预测部分:MotionFormer通过捕获agents和maps之间的交互,然后预测每一个agent的未来轨迹;由于每个agent的行为都会对场景中的其他agent产生重大影响,因此该模块会考虑所有agent联合预测。另外,该模块还包含一个ego-vehicle query,通过显示的自我车辆建模来与其他agent进行交互。OccFormer使用BEV Feature作为query, 在保留agent身份的情况下预测多步的占用。
(4)Planner利用MotionFormer的ego-vehicle query来预测规划结果,并让自己远离OccFormer预测的未来占用区域,避免发生碰撞。
TrackFormer: 它联合执行检测和多目标跟踪(MOT),而无需进行不可微分的后处理。除了用于对象检测的detection query之外,TrackFormer引入了额外的track query来跨帧跟踪agent。在每个time step,初始化的detection query负责检测第一次感知到的agent,而track query则继续对先前帧中未检测到的代理进行建模。这两种query都通过关注BEV feature来捕获agent abstractions。随着场景不断演变,当前帧的track query与SAM(self-attention module)中先前记录的查询交互,以聚合时序信息,直到相应的agent完全消失(在特定时间段内未跟踪)。TrackFormer包含N层,最终输出状态Qa为下游预测任务提供Na个有效agent信息。除了对围绕自我车辆的其他agent进行编码的query外,还在查询集中引入了一个特定的ego-vehicle query,以明确建模自车本身,在规划中进一步使用。举个例子,不仅考虑其他车的运动预测,还考虑自车,因为环境中车与车之间本身会有一定的影响,所以就需要考虑全局进行预测,ego-cehicle query就很说的明显了,在后面的模块中也起到作用。
**MapFormer:**基于2D全景分割方法Panoptic SegFormer进行设计,将道路元素稀疏表示为map query,以帮助下游运动预测,并对位置和结构知识进行编码。对于驾驶场景,将车道、分隔线和路口设置为things,可行驶区域设置为stuff。MapFormer还具有N个堆叠层,每个层的输出结果都受到监督,而只有最后一层中更新的查询Qm被转发到MotionFormer以进行agent-map交互。
MotionFormer: 通过TrackFormer和MapFormer对动态agents和静态map的高度抽象query, MotionFormer预测所有agents的多模态运动。这种范式只需要一次前向推理就可以获得多个agent的轨迹,可以节省将整个场景与每个agent坐标对齐的计算成本。同时考虑未来的动态变化,也将ego-vehicle query输入MotionFormer,是的自我车辆与其他agent产生交互。这个模块的每一层包含三种类型的交互:agent-agent,,agent-map,agent-goal,交互方式可以表示为:
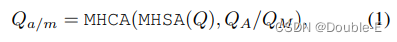
MHCA表示为多头交叉注意力,MHSA表示多头自注意力,由于把注意力集中在目标点上是优化预测轨迹的关键,作者采用可变形注意力设计了一种agent-goal注意力机制,具体如下:
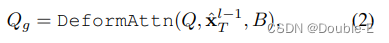
x表示之前的layer预测轨迹的终点。通过这一方法,预测的轨迹可以更进一步精确地根据终点周围的环境进行调整。上面说的三种交互方式是并行的,产生的Qa,Qm,Qg通过concatenate之后输入MLP得到Qctx,然后,Qctx被输入到后续层进行细化,或者被解码为最后一层的预测结果。
MotionFormer的motion query由两部分组成,一部分是前面层输出的Qctx,还有一部分是query position Qpos, Qpos的计算表达式为:
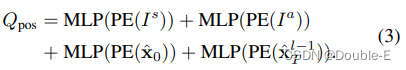
Is表示场景级别的anchors,Ia表示agent级别的anchors,x0表示agent的当前位置,xT则表示预测的目标位置,全部使用正弦位置编码,紧接着输入一个MLP,因为第一层没有xT,使用Is替代。场景级anchors在全局视图中表示先前的运动统计信息,而agent anchors在局部坐标中捕捉可能的意图。它们都是通过k-means算法在地面实况轨迹的端点上进行聚类,以缩小预测的不确定性。与现有知识相反,起点为每个agent提供自定义的位置嵌入,并且预测的端点以从粗到细的方式作为逐层操作的动态anchor。
与直接获取地面实况感知结果(即代理的位置和相应的轨迹)的传统运动预测工作不同,作者在端到端范式中考虑了来自先验模块的预测不确定性。从不完美的探测位置或航向角粗暴地回归地面实况航路点可能导致具有大曲率和加速度的不切实际的轨迹预测。为了解决这一问题,作者采用了非线性平滑器来调整目标轨迹,并在上游模块预测的不精确起点的情况下使其在物理上可行。过程是:
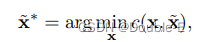
就是让GT与平滑后的轨迹相近。代价函数为:

运动学函数集Φ有五项,包括急动、曲率、弯曲率、加速度和横向加速度。代价函数使目标轨迹正则化以服从运动学约束。这种目标轨迹优化仅在训练中进行,不影响推理。
Prediction: Occupancy Prediction
占用率网格图是一种离散化的BEV表示,其中每个单元都持有一个指示其是否被占用的置信度,而占用率预测任务是揭示网格图在未来如何变化。先前的方法利用RNN结构根据观测到的BEV特征在时间上扩展未来预测。然而,它们依赖于高度手工制作的集群后处理来生成每个agent的占用图,因为它们通过将BEV特征作为一个整体压缩为RNN隐藏状态而大多与agent无关。由于我们时代缺乏agent知识,他们很难预测全局所有agents的行为,这对于理解场景如何演变至关重要
为了解决这一问题,我们提出了OccFormer,在两个方面结合了scene-level和agent-level语义:(1)密集场景特征在展开到未来视野时,通过精心设计的注意力模块获取代agent特征;(2)通过agent-level特征和密集场景特征之间的矩阵乘法,在没有大量后处理的情况下,很容易产生实例占用。
OccFormer由To个序列块组成,其中To表示预测范围。注意,在运动任务中,由于密集表示占用的高计算成本,To通常小于T。每个块将前一层的rich agent(没明白什么叫rich agent)特征Gt和状态(密集特征)F t−1作为输入,并同时考虑instant和scene-level 的信息为timestamp t生成Ft。为了获得具有动力学和空间先验的agent特征Gt,我们在模态维度上从MotionFormer获得最大池化motion query,表示为QX∈R Na×D,其中D为特征维度。然后,通过时间特定的MLP将其与上游track query QA和当前位置嵌入PA融合:
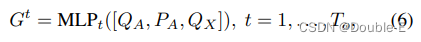
对于scene-level知识,为了训练效率,BEV特征B被缩减到1/4分辨率,以用作输入F0中的第一块。为了进一步节省训练内存,每个块遵循下采样-上采样的方式,其中注意力模块在两者之间,以在1/8下尺度特征处进行pixel-agent交互。
pixel-agent交互旨在在预测未来占用时统一scene和agent级别的理解。将密集特征Ftds作为查询,将实例级特征作为key和value,以随着时间的推移更新密集特征。详细地说,Ftds通过自注意层来对远处网格之间的响应进行建模,然后交叉注意力层对agent特征Gt和每网格特征之间的交互进行建模。此外,为了对齐pixel-agent的对应关系,作者通过注意力掩码来约束交叉注意力,该掩码限制每个像素仅查看在时间步长t占据它的agent。密集特征的更新过程公式化为:
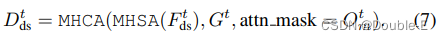
注意掩码Otm在语义上类似于occpancy,并且是通过将附加的agent-level特征和密集特征Ftds相乘而生成的,其中将代理级特征命名为掩码特征Mt=MLP(Gt)。
在等式7中的交互过程之后,Dtds被上采样到B的1/4大小,进一步将具有块输入Ft−1的Dtds相加作为残差连接,得到的特征F t被传递到下一个块。
I**nstance-level occupancy:**它表示每个代理的身份都被保留的占用情况。它可以简单地通过矩阵乘法获得。形式上,为了得到BEV特征B的原始大小H×W的占用预测,通过卷积解码器将场景级特征Ft上采样为Ftdec∈RC×H×W,其中C是信道维度。对于agent-level特征,我们通过另一个MLP将粗掩模特征Mt更新为占用特征U t∈R Na×C。作者发现,从掩模特征Mt而不是原始代理特征Gt生成UT会获得更加优越的性能。时间步长t的最终实例级占用率为:
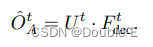
Planning:
没有高清(HD)地图或预定义路线的规划通常需要高级命令来指示前进方向。作者将原始导航信号(即向左、向右和保持前进)转换为三个可学习的嵌入,称为command embeddings。由于MotionFormer的自我车辆查询已经表达了其多模式意图,作者为其配备了命令嵌入,以形成“plan query”。作者使用了BEC feature的plan query,使其了解周围环境,然后将其解码为未来的路径点τ^ 。为了进一步避免碰撞,在推理中仅通过基于牛顿方法优化τ^:
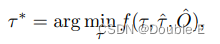
其中,τ^ 是原始规划预测,τ*表示优化规划,该优化规划是从multiple-shooting轨迹中选择的,以最小化成本函数f(·)。O^是从OccFormer的实例占用预测合并而来的经典二进制占用图。成本函数f(·)的计算公式为:
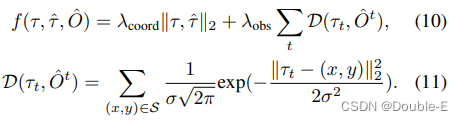
这里λcoord、λobs和σ是超参数,t表示未来视野的时间步长。l2成本将轨迹拉向原始预测的轨迹,而碰撞项D将其推离已占用的网格。
Shared matching: 由于UniAD涉及实例建模,因此在感知和预测任务中需要将预测与地面实况集配对。与DETR类似,在跟踪和在线映射阶段采用了二分匹配算法。至于跟踪,来自检测查询的候选者与新生的地面实况对象配对,来自跟踪查询的预测继承了来自先前帧的分配。跟踪模块中的匹配结果在运动和occupancy节点中重复使用,以在端到端框架中对从历史轨迹到未来运动的代理进行一致建模。
结果
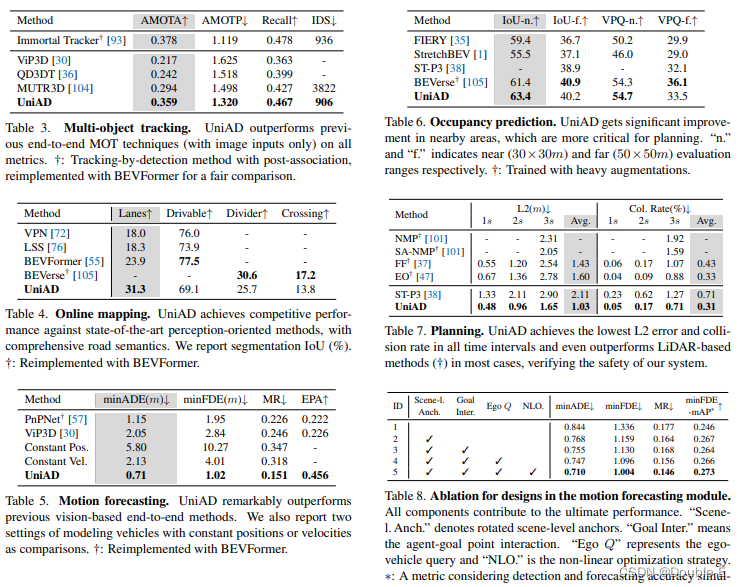
各个任务上的指标都超越了之前的方法
可视化:

初读这个论文,后面的再补充。。。














 1088
1088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









