







TensorRT介绍
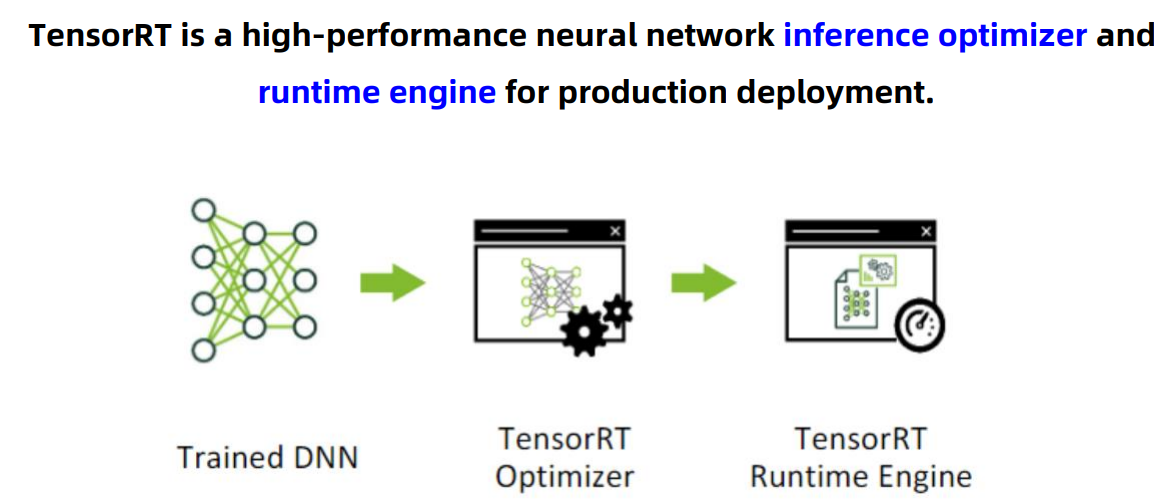
TensorRT是一种高性能的神经网络推理优化器和运行时推理引擎,应用于项目落地部署。首先需要有训练好的模型,然后经过TensorRT优化器的优化处理,利用TensorRT Runtime Engine进行落地部署。
- TensorRT是用于优化训练后的深度学习模型,以实现高性能推理的
SDK - TensorRT包含用于训练后的深度学习模型的深度学习
推理优化器,以及用于执行的runtme - 优点: TensorRT能够以更
高的吞吐量和更低的延迟运行深度学习模型,用TensorRT可以加速模型的推理
应用场景
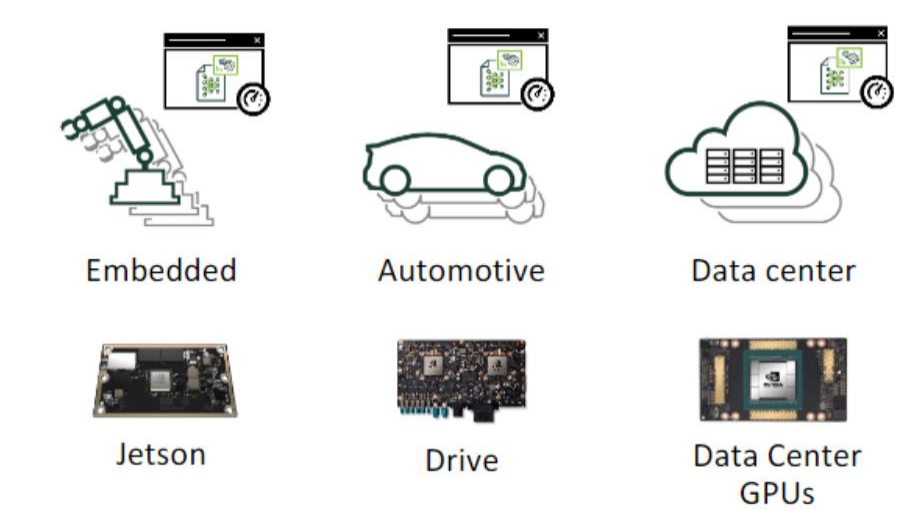
TensorRT可以用在很多场景,包括嵌入式、自动驾驶、数据中心,也就是在端测、边缘层、云端都可以考虑使用TensorRT,只要有GPU都可以利用TensorRT进行推理加速。
TensorRT深度学习开发流程

首先训练神经网络获得训练好的模型,然后利用TensorRT进行优化,可以指定Batch size和Precision,优化后获得tensorrt的推理引擎,并且序列化为一个plain文件保存到磁盘,最后在推理的时候进行反序列化使用。
- 比如训练好后我们得到深度学习的模型文件,比如
onnx,tensorflow,caffe,wts等训练好的文件。 - 为了使用
TensorRT我们需要Network Definition,然后利用构建器builder来优化参数,构建一个推理引擎,通过序列化保存到磁盘,然后从硬盘反序列化到内存进行推理使用。在runtime使用时,基于输入的tensors就可以得到输出的tensor结果。
TensorRT中相关的功能进行介绍说明
Builder:TensorRT的模型优化器,构建器将网络定义作为输入,执行与设备无关和针对特定设备的优化,并创建引擎。Network defination:TensorRT中模型的表示,网络定义是张量和运算符的图Engine: 表示TensorRT构建器优化好的模型Plan: 序列化格式的优化推理引擎。典型的应用程序将构建一次引擎,然后将其序列化为计划文件以供以后使用。要初始化推理引擎,应用程序将首先从plan文件中反序列化模型。Runtime: TensorRT的组件,可以在TensorRT引擎上执行推理。

TensorRT 模型的转换和部署
TensorRT生态系统分为两个部分:
- 1.用户可以遵循各种路径将其模型
转换为优化的TensorRT引擎,可以通过onnx,c++ api,python api转换为TensorRT优化引擎。 -
- 部署优化的TensorRT引擎时,各种runtime用户可以使用TensorRT到不同的目标平台

- 部署优化的TensorRT引擎时,各种runtime用户可以使用TensorRT到不同的目标平台
转换
转换TensorRT引擎主要有三个选择:
- using TF-TRT,使用tensorflow集成的tensorrt工具转换
- 自动
ONNX转换,从.onnx文件转换 - 手动使用TensorRT c++ 或者python的API来构建神经网络
为了获得最佳性能和可定制性,还可以使用TensorRT网络定义API手动构建TensorRT引擎。 这涉及仅使用TensorRT操作按目标平台构建与原模型相同(或近似相同,有的时候TensorRT算子不支持就需要改造网络)的网络。创建TensorRT网络后,可从框架中导出模型的权重,然后将其加载到TensorRT网络中。
用户可以使用C++和Python API的IPluginV2Ext类来实现自定义层,从而扩展TensorRT的功能。自定义层(通常称为插件)由应用程序实现和实例化。
部署
使用TensorRT部署模型有以下三种选择:
• 可以通过Tensorflow进行部署
• using the standalone TensorRT runtime API
• using NVIDIA Triton Inference Server
其中第二种,TensorRT的runtimeAPI允许最低的开销和最细粒度的控制,但是TensorRT本身不支持的运算符必须通过自己创建插件(plugin)
TensorRT通常异步使用,因此,当输入数据到达时,程序将调用一个enqueue函数。TensorRT将会从这个队列中异步的处理数据。
TensorRT 运行方式
为了优化推理模型,TensorRT会采用你的网络定义,执行包括平台特定的优化,并生成推理引擎。 此过程称为build阶段。 build阶段可能会花费大量时间,尤其是在嵌入式平台上运行时。 因此,典型的应用程序将只构建一次引擎,然后将其序列化为plan文件以供以后使用。
构建阶段对图执行以下优化
• 消除不使用其输出的层
• 消除等同于无操作的操作
• 卷积、偏置和ReLU操作的融合
• 使用完全相似的参数和相同的源张量(例如,GoogleNet v5的初始模块中的1x1卷积)进行的操作聚合(aggregation)
• 通过将层输出定向到正确的最终目的地来合并拼接层。
必要时,builder还可以修改权重的精度。 当生成8位整数精度的网络时,它使用称为calibration(校准)的过程来确定中间激活的动态范围,从而确定用于量化的适当缩放因子。此外,build阶段还会在dummy数据上运行各层,以从其kernel目录中选择最快的文件,并在适当的情况下执行权重预格式化和内存优化。
使用TensorRT的必要步骤:
• 根据模型创建TensorRT的网络定义
• 调用TensorRT构建器以从网络创建优化的runtime引擎
• 序列化和反序列化引擎,以便可以在runtime快速重新创建它
• 向引擎提供数据以执行推理


















 2909
2909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











