







 超级会员免费看
超级会员免费看
 本文详细介绍了BevFusion模型的结构,包括相机和点云的Bev特征提取,编码器、fuser、decoder和header四个部分。相机分支通过vtransformer模块融合深度和图像特征,点云分支则通过体素化和backbone提取Bev特征。在fuser部分,两者特征被融合,经过decoder进一步提取特征,最后在header部分进行解码,生成检测和分割输出。文章深入探讨了vtransformer的DepthLSSTransformer、视锥转换和bev pool的实现细节,以及点云和图像特征的融合过程。
本文详细介绍了BevFusion模型的结构,包括相机和点云的Bev特征提取,编码器、fuser、decoder和header四个部分。相机分支通过vtransformer模块融合深度和图像特征,点云分支则通过体素化和backbone提取Bev特征。在fuser部分,两者特征被融合,经过decoder进一步提取特征,最后在header部分进行解码,生成检测和分割输出。文章深入探讨了vtransformer的DepthLSSTransformer、视锥转换和bev pool的实现细节,以及点云和图像特征的融合过程。
文章目录
1. Bevfusion 结构介绍
1.1 结构概览
论文中给出了
Bevfusion的架构图,它的输入是多视角的相机和点云图,经过两个特定的head,分别用于做检测任务和分割任务。
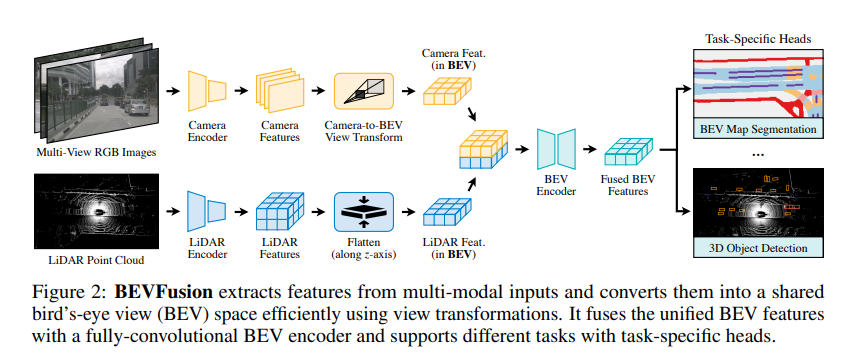
Bevfusion因为有两个模态的输入:多视角相机和点云,所以对应两个分支:相机分支和点云分支。
相机分支:输入6个视角的图片后,提取特征,然后经VT(View Transformer)转换之后得到相机的Bev特征。激光雷达分支:输入点云数据,经过Encoder编码得到体素化Lidar特征,然后沿z方向展平,得到Lidar Bev特征

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 3164
3164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











