







BEVFusion
一、文献总结
1. 文献基本信息
| 题目 | BEVFusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation |
|---|---|
| 发表会议 | IEEE International Conference on Robotics and Automation (ICRA) |
| 作者 | Zhijian Liu;Haotian Tang;Alexander Amini;Xinyu Yang;Huizi Mao;Daniela L. Rus;Song Han |
| 作者单位 | Massachusetts Institute of Technology (MIT) |
| arxiv时间 | v1: 2022年5月26日;v3:2024年9月1日 |
| 论文链接 | https://arxiv.org/abs/2205.13542 |
| 代码链接 | https://github.com/mit-han-lab/bevfusion |
2. 文献内容
多传感器融合(multi-sensor fusion)对于精确可靠的自动驾驶系统至关重要。近期的方法基于点级融合:将相机特征添加到激光雷达点云中。然而,相机到激光雷达的投影会丢失相机特征的语义密度,这阻碍了这类方法的有效性,尤其在面向语义的任务(如3D场景分割)中。在本文中,我们提出了BEVFusion,这是一种高效且通用的多任务多传感器融合框架。 它在共享的鸟瞰图(BEV)表示空间中统一了多模态特征,很好地保留了几何和语义信息。为实现这一点,我们通过优化的BEV池化技术,找出并解决了视图转换中的关键效率瓶颈,将延迟降低了40多倍。BEVFusion本质上与任务无关,几乎无需对架构进行更改,就能无缝支持不同的3D感知任务。它在nuScenes基准测试中创造了新的最优成绩,在3D目标检测上平均精度均值(mAP)和nuScenes检测得分(NDS)提高了1.3%,在BEV地图分割上平均交并比(mIoU)提高了13.6%,同时计算成本降低了1.9倍。
2.1 研究背景
3D目标检测是自动驾驶汽车感知的一项重要任务,根据传感器的不同,目前主要有3种检测方法:
LiDAR-Based 3D Perception(基于激光雷达的方法) 主要有两种策略
- 一种是单阶段(single stage)的方法来提取点云特征(包括展平的方法(flattened)和无锚点的方法(anchor-free))
- 另一种是两阶段(two-stage)的方法(通过RCNN提取单阶段目标检测器)
**Camera-based 3D perception(基于相机的方法)**包括两种策略:
- 基于深度估计的(depth-based): 如LSS,改进LSS的BEVDepth
- 基于Transformer的:如BEVFormer
**Multi-sensor fusion(基于多传感器融合的方法)**包括两种层面的融合:
通常多传感器融合需要解决不同模态、不同视角特征的融合问题。因此,为解决视角差异问题,必须找到一种统一的表示方式来适用于多任务多模态特征融合。 第一种思路是将激光雷达点云投影到相机上,但这种投影会导致几何畸变。(相机空间)

另一种思路是通过2D图像的语义标签,CNN特征或伪点云来增强激光雷达点云,从而预测3D检测框。尽管这在大规模检测表现较好,但是在语义划分任务中不太行,因为相机-激光雷达会存在语义损失。对于稀疏的激光雷达来说,更明显。(点云空间)

在BEVfusion之前,基于点云特征的融合方案一直是首选,但BEVFusion通过重新思考“激光雷达特征空间是否是进行传感器融合的最佳空间?”,为多传感器融合提供了全新视角。该文章展示了一种此前被忽视的替代点云空间的融合范式,其简洁的思路也适合工业界的运用。作者希望这项工作能成为未来传感器融合研究简单而有力的标杆,激励研究人员重新思考通用多任务多传感器融合的设计和范式。
2.2 模型框架
BEVFusion挑战了之前基于激光雷达空间或在相机空间进行多传感器融合的研究视角,提出可以在BEV空间进行雷达和相机的特征融合:
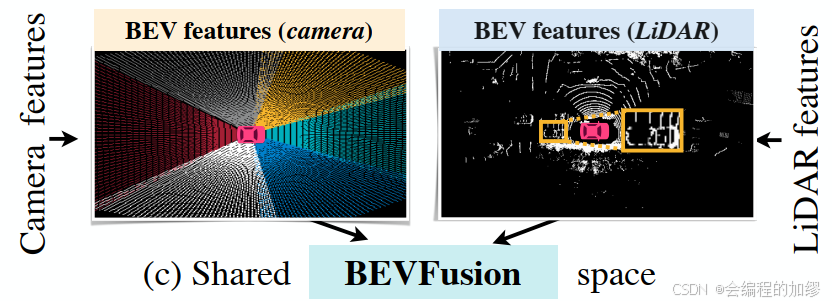
该方法的主要实现流程如下:
- 分别通过不同模态的Encoder来提取不同模态传感器数据特征
- 将不同模态的特征转换为BEV特征,并投影到BEV空间中
- 在BEV空间中实现特征融合
- 通过不同的任务头来进行不同的3D任务(目标检测和语义划分)
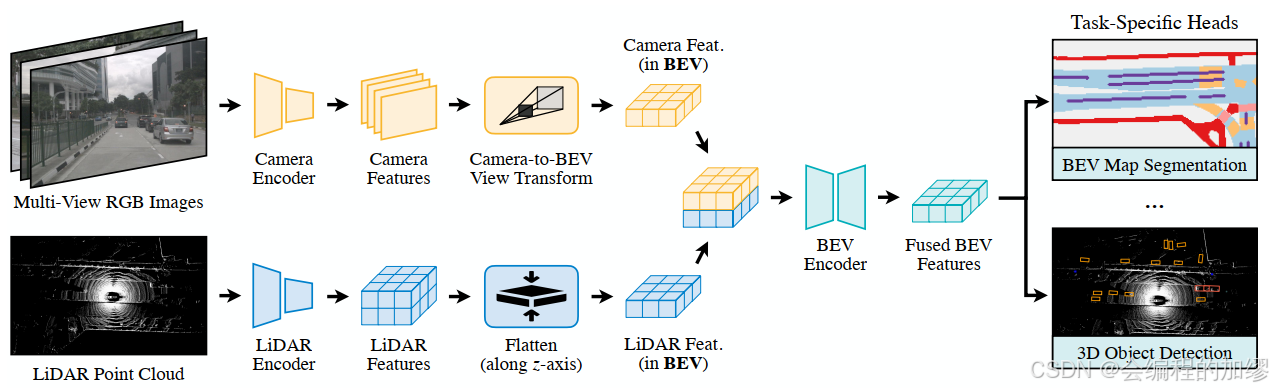
2.3 细节与要点
1、统一表征(Unified representation)
不同传感器的视角和模态不同,例如对于相机特征而言,每个相机都有不一致的视角(如nuScenes数据集),这些区别导致特征融合较为困难。因此,找到一个共享的表征是十分重要的,该表征需具备两个优点 (1) 所有传感器特征能被轻松转换,并且没有信息损失; (2) 适合不同类型的任务。
作者选择在鸟瞰图空间统一不同传感器的表征,通过将LiDAR特征从高度维度展平,保留其几何特征(gemetric);将Camera特征像素射线映射到3D空间,保留其语义特征(semantic)
2、图像特征到BEV特征的高效转换(Efficient camera-to-BEV transformer)
作者发现由于相机没有深度信息,所以将相机特征转换为BEV特征较为困难。因此,作者采用了LLS的思路,预测每一个像素点的深度信息。通过这种方式,生成了相机的点云数据,大小为(N x H x W x D),N为图片数量,(H x W)为图像大小,D为图像深度信息。
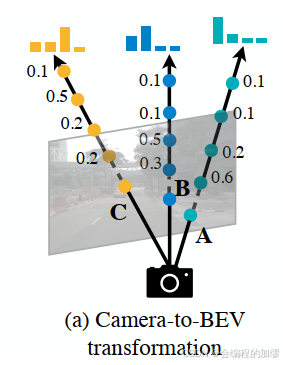
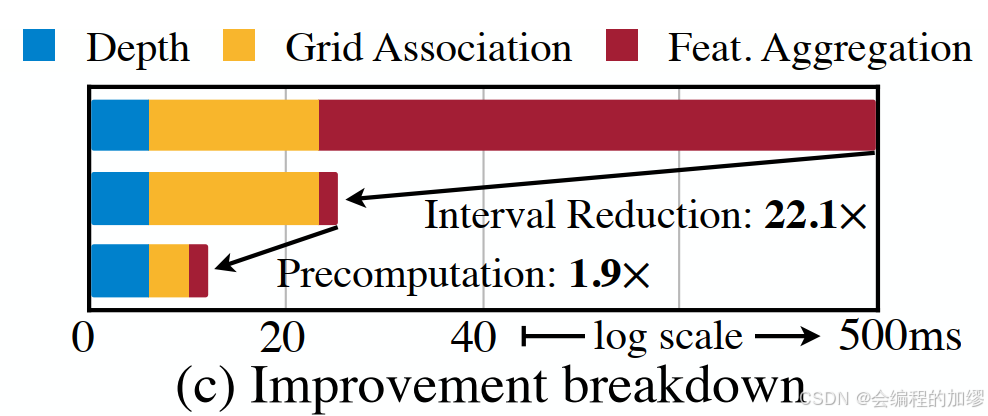
然而,通过简单的实验,作者发现相机的BEV pooling效率很低,原因在于相机产生的点云数量很大,是激光雷达的100多倍。为了解决该问题,作者采用了预计算(precomputation)和间歇减少(interval reduction)两种方法。
- 预计算(precomputation)
BEV池化的第一步是将相机特征点云的每一个点与BEV网格相关联。与激光雷达点云数据不同,相机特征点云是固定的。因此,作者预先计算了每个点的3D坐标和BEV网格序号,同时根据网格序号来对所有点进行分类,记录每个点的等级。在推理期间,只需要匹配所有特征点的预计算等级即可。这一步将网格关联的延迟由17ms缩减到4ms。
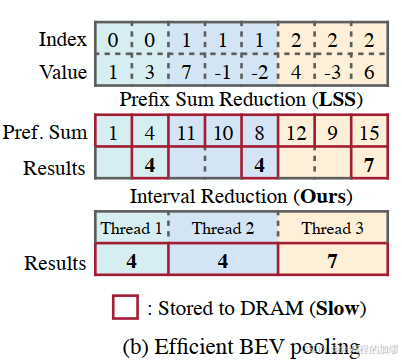
- 间歇减少(Interval reduction)
在网格关联之后,所有在同一个BEV网格中的点在tensor中的表征是连续的。所以,BEV池化的下一步工作是通过均匀函数(e.g. mean, max, sum)来聚合每一个BEV网格中的特征。之前的方法先通过累加计算值,再来确定每一个index的结果,作者通过找到GPU设置的阈值,来直接计算每个indenx的和,从而减少了计算量,将特征聚合的延迟从500ms减少到2ms.
3、全连接卷积融合
由于LiDAR BEV和camera BEV特征仍有部分没有对齐,所以作者采用了基于全连接层的卷积的BEV编码器来消除局部不对齐。
4、多任务头
作者采用了已有的任务头来实现具体的任务,这个任务头使得BEVfusion可以应对不同任务。
2.4 实验结果
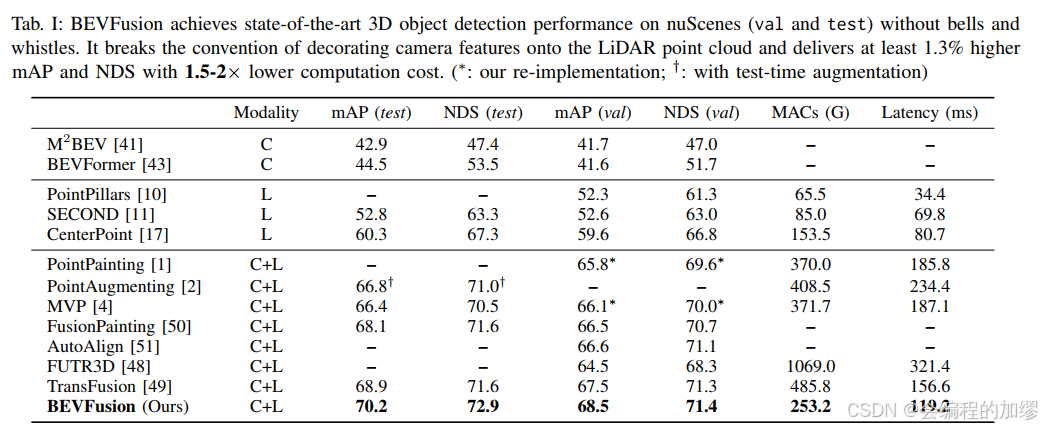
该文章在nuScenes和Waymo两个大型数据集上进行了测试,结果比较好。
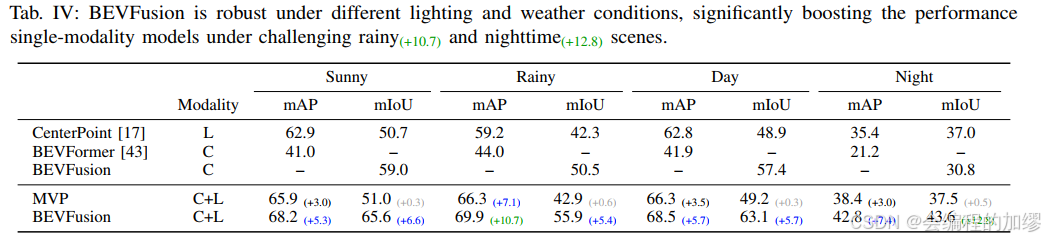
同时,在不同天气和亮度下进行了测试:
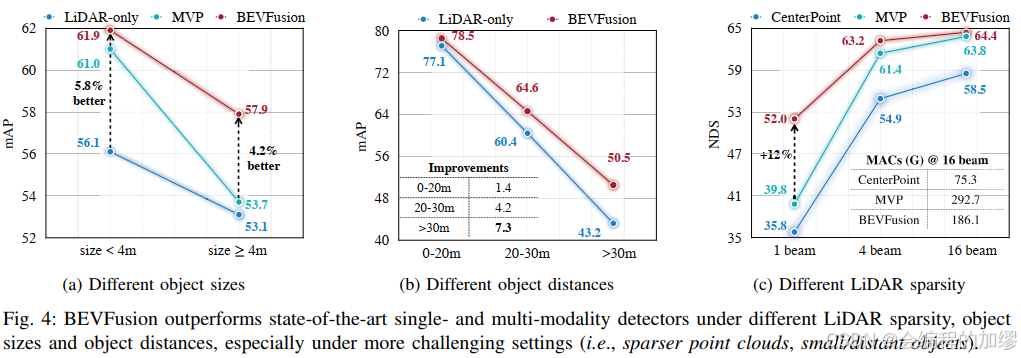
并且,针对不同的目标大小、距离等进行了测试:
3. 文献总结
(1) 本文核心研究问题
- 能不能打破传统在图像空间或者点云空间进行特征融合的思路,改变雷视融合的空间?
- 如何提升相机到BEV特征转换的速率?
(2)文章亮点
- 作者提出了将雷达和相机数据先进行BEV特征提取,随后再到BEV空间中进行融合,该融合方法不会造成点云几何信息或相机语义信息的损失
- 作者发现相机进行BEV特征转换时,转换的速度很慢,所以作者采用了预计算(precompute)和间接减少(Interval reduction)两种方法来提升特征池化速率
二、项目复现(最新2025年3月29日)
1. 环境配置
按照镜像文件拉取相应配置,再安装对应的软件包
FROM nvidia/cuda:11.3.1-devel-ubuntu20.04
RUN apt-get update && apt-get install wget -yq
RUN apt-get install build-essential g++ gcc -y
ENV DEBIAN_FRONTEND noninteractive
RUN apt-get install libgl1-mesa-glx libglib2.0-0 -y
RUN apt-get install openmpi-bin openmpi-common libopenmpi-dev libgtk2.0-dev git -y
# Install miniconda
ENV CONDA_DIR /opt/conda
RUN wget --quiet https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda.sh && \
/bin/bash ~/miniconda.sh -b -p /opt/conda
# Put conda in path so we can use conda activate
ENV PATH=$CONDA_DIR/bin:$PATH
RUN conda install python=3.8
RUN conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=11.3 -c pytorch
RUN pip install Pillow==8.4.0
RUN pip install tqdm
RUN pip install torchpack
RUN pip install mmcv==1.4.0 mmcv-full==1.4.0 mmdet==2.20.0
RUN pip install nuscenes-devkit
RUN pip install mpi4py==3.0.3
RUN pip install numba==0.48.0
上面的那些工具也要安装,不然nuscenes-kit用不了
apt-get install libgl1-mesa-glx libglib2.0-0 -y
配置完成之后,需要运行下面的命令,来加载mmdet3d模块
python setup.py develop
2. 数据准备
仅是为了学习,这里采用了nuScenes-mini数据集1
创建数据软连接:
ln -s /xxx/nuScenes-mini ./data/nuScenes
mmdet3d2中写了nuScenes用于3D检测任务的数据准备。
(1) 准备之前
将数据下载到data目录中,并且通过mmdetection3d目录上的工具进行转换

通过下面命令对数据进行转换
python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes
(2) 转换后的数据结构:
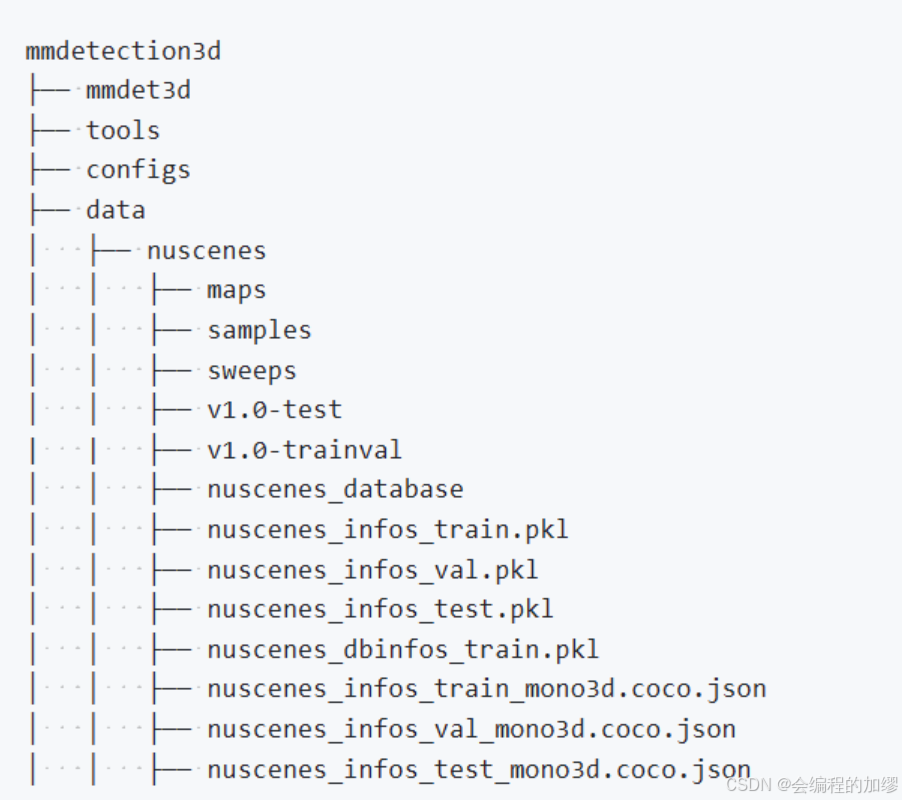
在这里,.pkl 文件通常用于涉及点云的方法,而 coco 风格的.json 文件更适合基于图像的方法,例如基于图像的 2D 和 3D 检测。接下来,我们将详细阐述这些信息文件中记录的细节。
(3)该部分可能遇到的报错
报错1:
ImportError: cannot import name 'feature_decorator_ext' from partially initialized module 'mmdet3d.ops.feature_decorator' (most likely due to a circular import) (/workspace/05fusion/bevfusion-main/mmdet3d/ops/feature_decorator/__init__.py)
💡解决:注释掉 mmdet3d/ops/init.py 中的 from .feature_decorator import feature_decorator
报错2:
File "/opt/conda/envs/bevfusion/lib/python3.8/site-packages/numpy/__init__.py", line 320, in __getattr__
raise AttributeError("module {!r} has no attribute "
AttributeError: module 'numpy' has no attribute 'long'
💡解决:1.24版本后的numpy中都弃用了np.long,可以将numpy版本降级,将为pip install numpy==1.23 -i https://pypi.tuna.tsinghua.edu.cn/simple
报错3:
assert osp.exists(self.table_root), 'Database version not found: {}'.format(self.table_root)
AssertionError: Database version not found: ./data/nuscenes/v1.0-trainval
可能是因为我用得mini版本?
改代码中使用得v1.0-trainval版本数据,而我使用得是v1.0-mini版本数据,故出现此错误
💡解决:指定使用v1.0-mini,根据源代码,有以下操作
python tools/create_data.py --version v1.0-mini nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes
报错4:
FileNotFoundError: NuScenesDataset: [Errno 2] No such file or directory: './data/nuscenes/nuscenes-mini_infos_train.pkl'
💡 解决办法:参考博客
mmdetection3d官方代码
/tools/data_converter/nuscenes_converter.py 84行
metadata = dict(version=version)
if test:
print('test sample: {}'.format(len(train_nusc_infos)))
data = dict(infos=train_nusc_infos, metadata=metadata)
info_path = osp.join(root_path,
'{}_infos_test.pkl'.format(info_prefix))
mmcv.dump(data, info_path)
else:
print('train sample: {}, val sample: {}'.format(
len(train_nusc_infos), len(val_nusc_infos)))
data = dict(infos=train_nusc_infos, metadata=metadata)
info_path = osp.join(root_path,
'{}_infos_train.pkl'.format(info_prefix))
mmcv.dump(data, info_path)
data['infos'] = val_nusc_infos
info_val_path = osp.join(root_path,
'{}_infos_val.pkl'.format(info_prefix))
mmcv.dump(data, info_val_path)
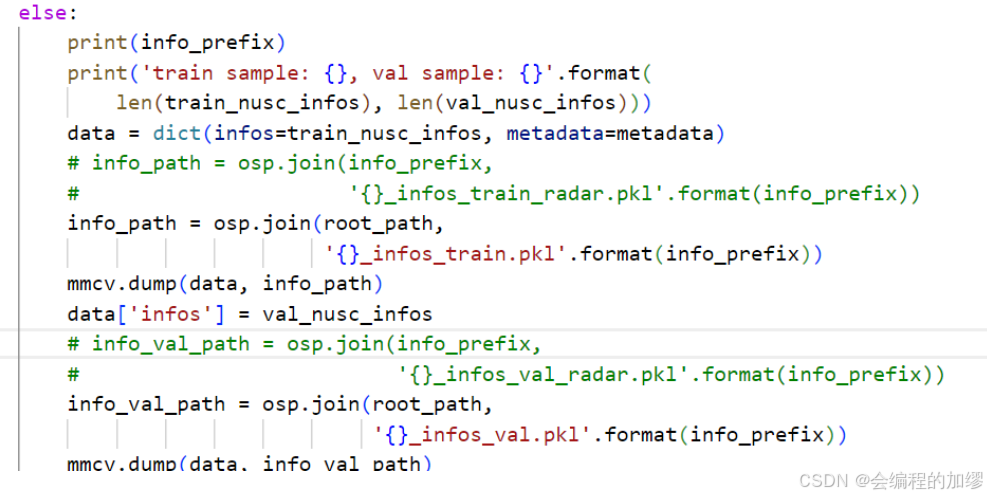
bevfusion中相应代码
metadata = dict(version=version)
if test:
print('test sample: {}'.format(len(train_nusc_infos)))
data = dict(infos=train_nusc_infos, metadata=metadata)
info_path = osp.join(root_path,
'{}_infos_test_radar.pkl'.format(info_prefix))
mmcv.dump(data, info_path)
else:
print(info_prefix)
print('train sample: {}, val sample: {}'.format(
len(train_nusc_infos), len(val_nusc_infos)))
data = dict(infos=train_nusc_infos, metadata=metadata)
info_path = osp.join(info_prefix,
'{}_infos_train_radar.pkl'.format(info_prefix))
mmcv.dump(data, info_path)
data['infos'] = val_nusc_infos
info_val_path = osp.join(info_prefix,
'{}_infos_val_radar.pkl'.format(info_prefix))
mmcv.dump(data, info_val_path)
修改后的代码:
我运行的目录下面是这样的:
3. 算法测试
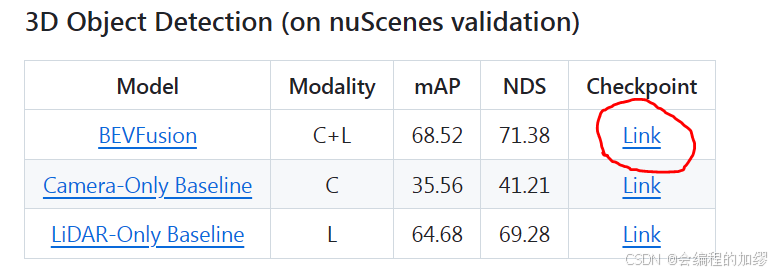
进行算法测试之前,需要将想要测试的权重文件下载到pretrained文件夹下,下载链接为bevfusion的github3。
测试运行代码:
torchpack dist-run -np [number of gpus] python tools/test.py [config file path] pretrained/[checkpoint name].pth --eval [evaluation type]
我测试的是camera+lidar 的目标检测任务
torchpack dist-run -np 2 python tools/test.py configs/nuscenes/det/transfusion/secfpn/camera+lidar/swint_v0p075/convfuser.yaml pretrained/bevfusion-det.pth --eval bbox
因此我下载的权重是:
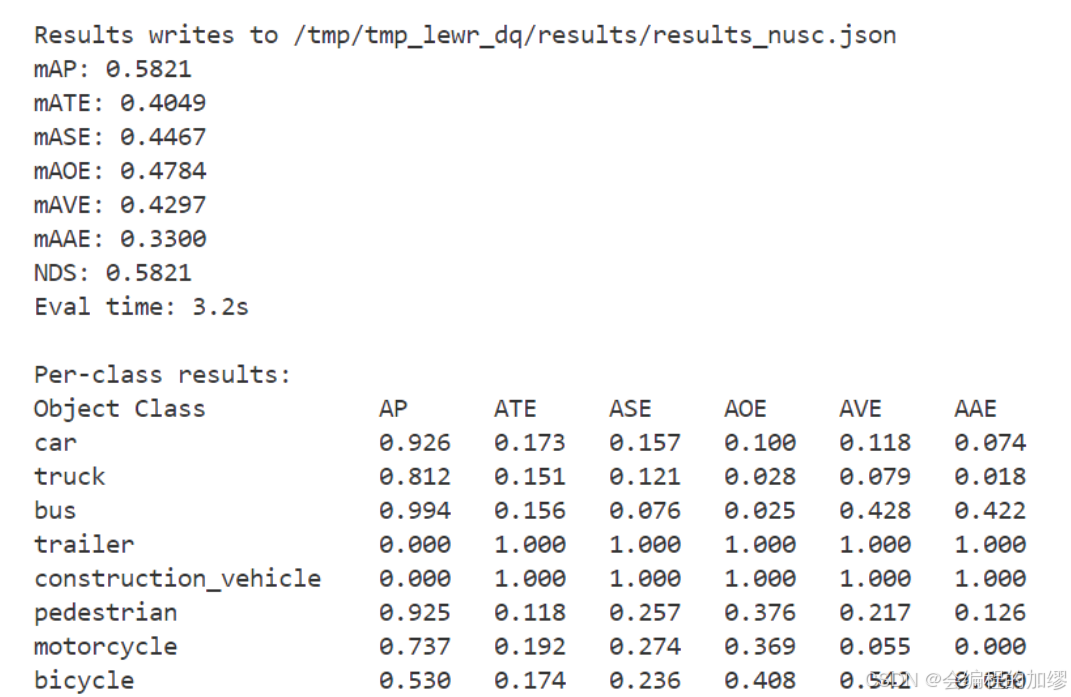
运行结果如下所示:
该部分可能遇到的报错及解决办法:
报错1:
ImportError: cannot import name 'feature_decorator_ext' from partially initialized module 'mmdet3d.ops.feature_decorator' (most likely due to a circular import) (/workspace/05fusion/bevfusion-main/mmdet3d/ops/feature_decorator/__init__.py)
💡解决:注释这一行代码
报错2:
File "/workspace/05fusion/bevfusion-main/mmdet3d/models/backbones/radar_encoder.py", line 18, in <module>
from flash_attn.flash_attention import FlashMHA
ModuleNotFoundError: No module named 'flash_attn
因为没有安装flash_attn,解决办法参考链接: https://github.com/mit-han-lab/bevfusion/issues/492
💡解决: 可以try以下安装低版本的包pip install flash-attn==0.2.0 -i https://mirrors.aliyun.com/pypi/simple/ 有用的
或者注释该模块
报错3:
RuntimeError: Given groups=1, weight of size [8, 1, 1, 1], expected input[6, 6, 256, 704] to have 1 channels, but got 6 channels instead
💡解决:修改bevfusion/mmdet3d/models/vtransforms/base.py文件第37、38行代码,修改为add_depth_features=False和height_expand=False此为官方github中issue的解决方案4
4. 其他学习链接
mmdetection3d 已经将bevfusion加入到他们的代码库中5,并且持续更新。目前可以看到bevfusion的官方github已经停止修改,所以建议各位小伙伴可以使用mmdetection3d中的代码进行学习和使用!
最近在学习这篇论文,提供了很好的多模态传感器融合思路,所以将笔记整理与大家分享!大家有啥问题欢迎与我讨论,一起学习!!!


















 8856
8856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











