







 超级会员免费看
超级会员免费看
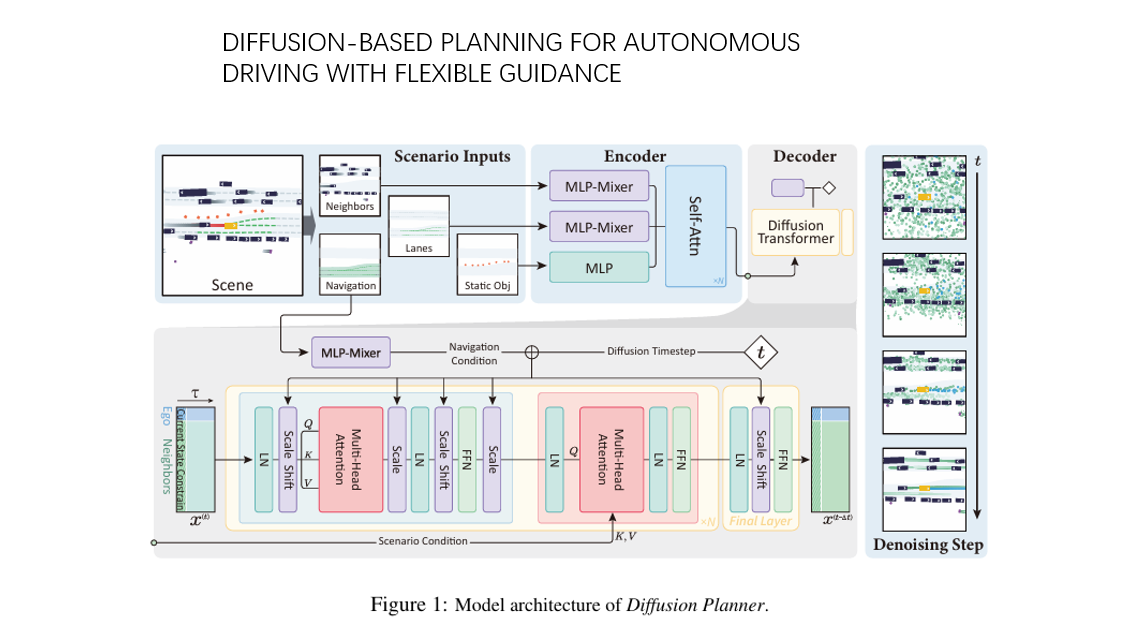
在复杂开放世界中实现类人驾驶行为是自动驾驶领域的一项关键挑战。基于学习的现代规划方法(如模仿学习)常因适应性有限、难以学习人类规划中常见的复杂
多模态行为,而在平衡多目标与安全保障方面存在不足,更遑论其高度依赖基于预定义规则的降级策略。我们提出一种基于Transformer架构的扩散规划模型,用于实现闭环规划,该模型能有效建模多模态驾驶行为,并在无需基于规则修正的情况下确保轨迹质量。该架构支持预测与规划任务在统一框架下的联合建模,从而实现车辆间的协同行为。此外,通过学习轨迹评分函数的梯度并采用灵活的分类器引导机制,扩散规划器能有效实现安全且自适应的规划行为。在大规模真实世界自动驾驶规划基准nuPlan及我们新收集的200小时配送车辆驾驶数据集上的评估表明,扩散规划器在多种驾驶风格中均展现出卓越的闭环性能与稳健的迁移能力。项目官网:https://zhengyinan-air.github.io/Diffusion-Planner/。
- papers: DIFFUSION-BASED PLANNING FOR

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 57
57

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











