









1. DataFrame属性
import pandas as pd
nba = pd.read_csv('nba.csv', parse_dates=['Birthday'])
nba
nba.dtypes

nba.index
RangeIndex(start=0, stop=450, step=1)
start-索引下限,stop-索引上限,step-步长
nba.columns
Index([‘Name’, ‘Team’, ‘Position’, ‘Birthday’, ‘Salary’], dtype=‘object’)
# DateFrame 维数 返回整型
nba.ndim
2
# DateFrame 维数 返回元组
nba.shape
(450, 5)
nba.size
2250,size属性包含了缺失值(NaN)
nba.count()
2250,count方法不计算缺失值(NaN)
#size和count()的区别
import numpy as np
data = {
'a':[1, 2],
'b':[3, np.nan]
}
test = pd.DataFrame(data)
test.size
test.count()

test.size = 4

2. DataFrame方法
head – 获取前面n条数据
tail – 获取尾部n条数据
默认参数都为5
nba.head(3)
nba.tail(4)
sample – 随机抽取数据,默认为1条
nba.sample(6)
nunique – 计算唯一值
数据表示NBA中有30支队伍,有9种位置和269种薪资。
nba.nunique()

nba.max()
每个column的最大值,nba.min()用法相同

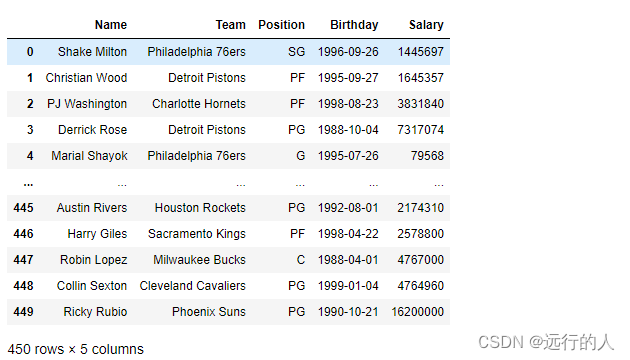
# 找出年龄最大的5条数据
nba.nlargest(5, columns='Birthday')
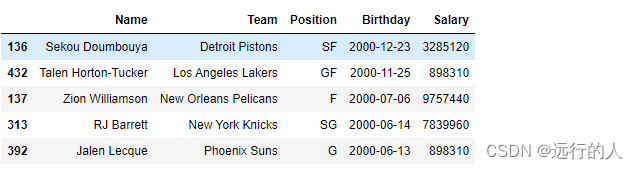
# 找出3条工资最低的数据
nba.nsmallest(3, columns='Salary')
nlargest、nsmallest方法只能在数字或者日期列上调用,否则报错。
nba.sum()

非数字栏字符串连接起来,没有意义,一般加上numeric_only=True,只计算数字。
nba.sum(numeric_only=True)
















 157
157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









