







 本文作者通过爬取《华尔街日报》的历史数据,探讨传闻证据在论文中的关键作用。他们利用Python的Selenium库获取Cookies以避免被识别为爬虫,并解析网页获取文章列表。文章年份分布显示从1997年至2021年,共爬取了1220941篇文章。文章主题分布集中在商业、市场、美国等板块。作者还展示了如何爬取和翻译文章内容,为后续的研究提供了便利。
本文作者通过爬取《华尔街日报》的历史数据,探讨传闻证据在论文中的关键作用。他们利用Python的Selenium库获取Cookies以避免被识别为爬虫,并解析网页获取文章列表。文章年份分布显示从1997年至2021年,共爬取了1220941篇文章。文章主题分布集中在商业、市场、美国等板块。作者还展示了如何爬取和翻译文章内容,为后续的研究提供了便利。
最近搭了个人网站,版面更好看些,地址在 https://mengjiexu.com/
从读论文和写论文的体验来看,传闻证据 (anecdotes) 对论文能不能给人可靠的第一印象有决定性作用。传闻证据到位了,就不会有人追着问一些澄清性问题 (clarification questions),后面论证研究题目的重要性时也会顺利很多 (why care)。此外,很多时候传闻证据对作者本人更好地了解研究背景 (institutional background) 并提出合情合理的研究设计也有很大的帮助作用1。
据我所知,华尔街日报 (Wall Street Journal) 给很多顶刊论文提供了灵感。比如 Zhu (2019 RFS) 与 用停车场数据预测零售公司业绩的报道非常相关 (2014.11.20 WSJ), 一篇关于对冲基金经理与大数据的报道 (2013.12.18 WSJ) 则提出了 Katona et al. (2018 WP, MS R&R) 和 Mukherjee et al. (2021 JFE) 的主要论点。
所以我最近写论文的时候爬了华尔街日报的所有历史数据,源网址是 WSJ Archives,事实证明这个工作在我最近的论文展示中起到了相当正面的作用2。
获取 Cookies
按照惯例,还是先获取 Cookies。首先登陆,登陆后等待大概20秒左右会跳出一个小框,要求接受 cookies,需要点击 YES, I AGREE, 经过这步操作的 Cookies 才能顺利获取文章列表或文章内容,否则会被网站识别为爬虫。
另外, Cookies 有失效时间 (expiry time),最好每次爬之前都更新下 Cookies。
from selenium import webdriver
import time
import json
option = webdriver.FirefoxOptions()
option.add_argument('-headless')
driver = webdriver.Firefox(executable_path='/Users/mengjiexu/Dropbox/Pythoncodes/Bleier/geckodriver')
# 填入 WSJ 账户信息
email = 'username'
pw = 'password'
def login(email, pw):
driver.get(
"https://sso.accounts.dowjones.com/login?")
# 为了不透露个人信息,需要读者自己粘贴登陆界面的 url
time.sleep(5)
driver.find_element_by_xpath("//div/input[@name = 'username']").send_keys(email)
driver.find_element_by_xpath("//div/input[@name = 'password']").send_keys(pw)
driver.find_element_by_xpath("//div/button[@type = 'submit']").click()
# 登陆
login(email, pw)
time.sleep(20)
# 切换到跳出的小框
driver.switch_to_frame("sp_message_iframe_490357")
# 点击接受收集 Cookies
driver.find_element_by_xpath("//button[@title='YES, I AGREE']").click()
time.sleep(5)
# 将 Cookies 写入文件
orcookies = driver.get_cookies()
print(orcookies)
cookies = {
}
for item in orcookies:
cookies[item['name']] = item['value']
with open("wsjcookies.txt", "w") as f:
f.write(json.dumps(cookies))
获取文章列表
网页分析
WSJ 每日文章列表 url 的命名方式十分简单,由以下两部分组成:
- https://www.wsj.com/news/archive/
- 年/月/日
所以在指定时间范围内遍历每一天即可得到每一天的文章列表。不过我爬的时候顺手爬了所有的日期列表,所以代码中直接遍历了日期列表。
WSJ Daylist: 链接: https://pan.baidu.com/s/1kPYlot5lmYtQwWlHxA6OpQ 密码: 0b44
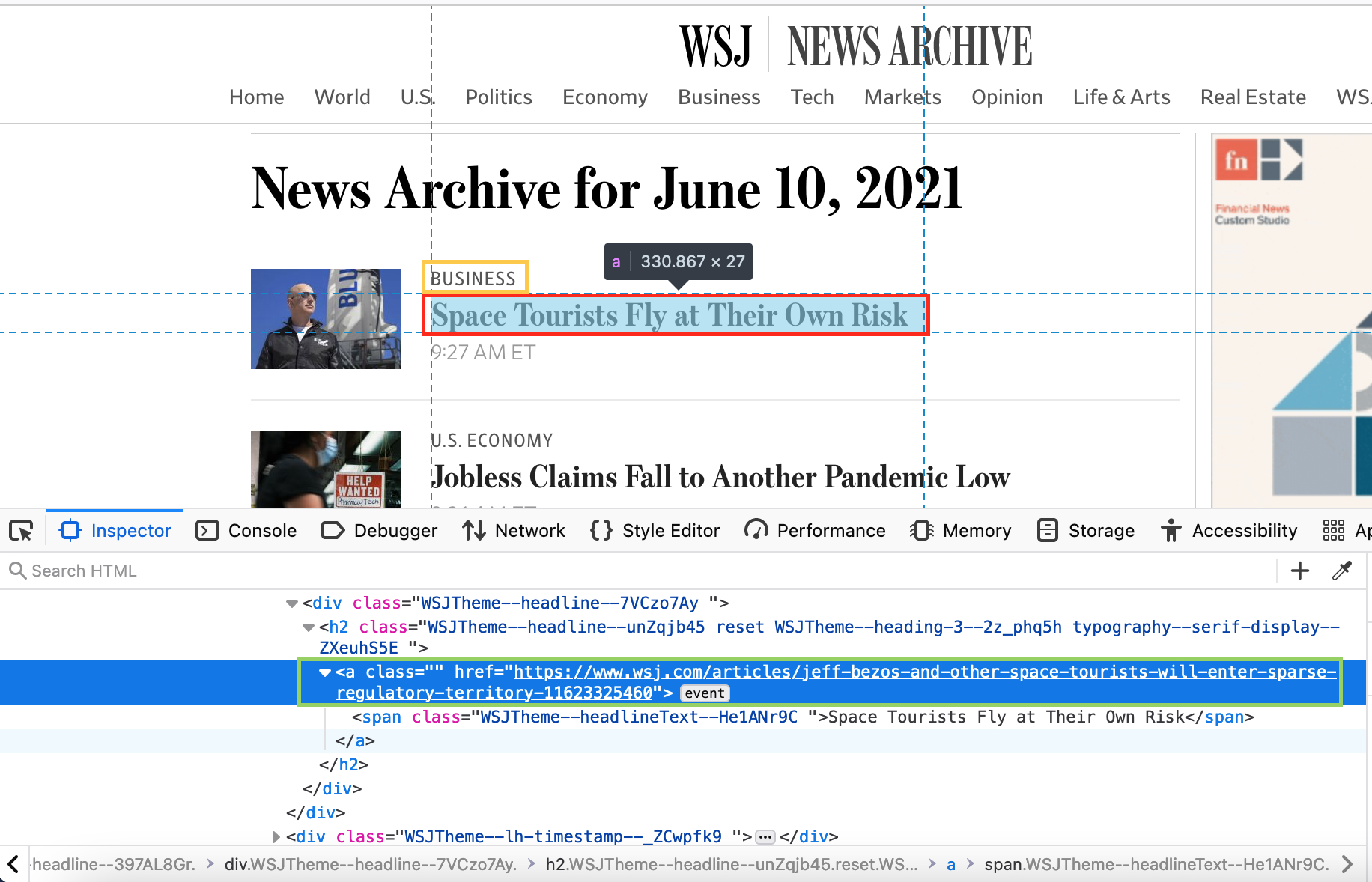
以 2021 年 6 月 10 日的文章列表为例 (如下图),对于每一篇文章,主要关注四个变量:
- 文章所属板块 - 黄色框
- 文章标题 - 红色框
- 文章链接 - 绿色框
- 文章日期 - 前定
很多日期的文章列表都不止一页,所以需要:
- 判断翻页条件:详见代码中
pagenation(page)函数 - 如果满足翻页条件,进行翻页:
newdaylink = daylink + "?page=%s"%pagenum
代码
import time
from lxml import etree
import csv
import re
from tqdm import tqdm
import requests
import json
import pandas as pd
import csv
import unicodedata
from string import punctuation
f = open('wsjdaylist.txt', 'r')
headers = {
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1088
1088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









