







一、树
对于大量的输入数据,链表的线性访问时间太长,不宜使用。本节介绍一种简单的数据结构,其大部分操作的运行时间平均为O(logN)。
我们涉及的这种数据结构叫作二叉查找树。二叉查找树是在很多应用程序中都有使用的两个库集合类set和map的实现基础。在计算机科学中树(tree)是非常有用的抽象概念。
1.1 预备知识
树(tree)可以用几种方式定义。定义树的一种自然的方式是递归的方法。一棵树是一些结点的集合。这个集合可以是空集;若不是空集,则树由称作根(root)的结点r以及零个或多个非空的(子)树组成,这些子树中每一棵的根都被来自根r的一条有向的边(edge)所连接。
每一棵子树的根叫做根r的儿子(child),而r是每一棵子树的根的父亲(parent)。下图显示了用递归定义的典型的树。
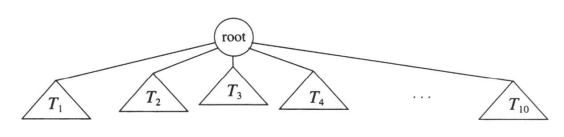
从递归定义中可以发现,一棵树是N个结点和N-1条边的集合,其中的一个结点叫做根。存在N-1条边的结论是由下面的事实得出的:每条边都将某个结点连接到它的父亲,而除去根结点外每一个结点都有一个父亲(见下图)。
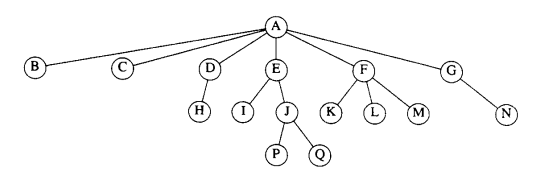
在上图的树中,结点A是根。结点F有一个父亲A并且儿子K、L和M。每一个结点可以有任意多个儿子,也可能没有儿子。没有儿子的结点称为叶(leaf)结点。上图中的叶结点(树叶)是B、C、H、I、P、Q、K、L、M和N。具有相同父亲的结点为兄弟(siblings)结点;因此,K,L和M都是兄弟。用类似的方法可以定义祖父(grandparent)和孙子(grandchild)关系。
从结点到
的路径(path)定义为结点
的一个序列,使得对于
,结点
是
的父亲。路径的长(length)为路径上的边的条数,即k-1。从每一个结点到它自己有一条长为0的路径。注意,在一棵树中从根到每个结点恰好存在一条路径。
对任意结点,
的深度(depth)为从根到
的唯一路径的长。因此,根的深度为0。
的高(height)是从
到一片树叶的最长路径的长。因此所有的树叶的高都是0.一棵树的高等于它的根的高。对于上图中的树,E的深度为1而高为2;F的深度为1而高也是1;该树的高为3。一个树的深度等于它的最深的树叶的深度;该深度总是等于这棵树的高。
如果存在从到
的一条路径,那么
是
的一位祖先(ancestor)而
是
的一个后裔(descendant)。如果
,那么
是
的一位真祖先(proper ancestor)而
是
的一个真后裔(proper descendant)。
1.1.1 树的实现
实现树的一种方法是在每一个结点除数据外还要有一些链,来指向该结点的每一个儿子。然而,由于每个结点的儿子数可能变化很大并且事先不知道,因此在数据结构中建立到各儿子结点的直接链接是不可行的,因为这样会产生太多浪费的空间。实际上解法很简单,将每个结点的所有儿子都放在树结点的链表中。下段代码是非常典型的声明。
struct TreeNode
{
Object element;
TreeNode *firstChild;
TreeNode *nextSibling;
}上段代码显示了一棵树是如何用这种实现方法表示出来的。图中向下的箭头是指向firstChild的链。从左到右的箭头是指向aingnextSibling的链。因为空链太多,所以没有把它们画出。
在下图所示的树中,结点E有一个链指向兄弟(F),另一链指向儿子(I),而有的结点两种链都没有。

1.1.2 树的遍历及应用
树有很多应用。流行的用法之一是用于包括UNIX和DOS在内的许多常用操作系统中的目录结构。下图是UNIX文件系统中的一个典型的目录。

这个目录的根是/usr(名字后面的星号指出/usr本身就是一个目录)。/usr有三个儿子:mark、alex和bill,它们自己也都是目录。因此,/usr包含三个目录并且没有常规的文件。文件名/usr/mark/book/ch1.r先后三次通过最左边的儿子结点而得到。第一个“/”后的每个“/”都表示一条边;结果为一全路径(pathname)。这个分级文件系统非常流行,因为它使得用户能够逻辑地组织数据。不仅如此,在不同目录下的两个文件还可以享有相同的名字,因为它们必然有从根开始的不同的路径从而具有不同的路径名。在UNIX文件系统中的目录就是含有它的所有儿子的一个文件,因此,这些目录几乎是完全按照上述的类型声明构造的。事实上,按照UNIX的某些版本,如果将打印文件的标准命令应用到目录上,那么目录中的文件名能够在(与其他非ASCII信息一起的)输出中看到。
设我们想要列出目录中所有文件的名字。输出格式是:深度为的文件将被
次跳格(tab)缩进后打印其名。该算法在以下伪代码中给出:
void FileSystem::listAll(int depth = 0) const
{
printName( depth ); //Print the name of the object
if( isDirectory() )
for each file c in this directory (for each child)
c.listAll( depth + 1 );
}为了显示根时不进行缩进,递归函数listAll需要从深度0开始。这里的深度是一个内部簿记变量,而不是主调例程能够期望知道的那种参数。因此,需要给depth提供默认值0。
算法的逻辑简单易懂。文件对象的名字以适当个数的跳格打印出来。如果是一个目录,那么我们递归地一个一个地处理它所有的儿子。这些儿子处在同一个深度上,因此需要缩进一个附加的空间。整个输出如下:
/usr
mark
book
ch1.r
ch2.r
ch3.r
course
cop3530
fall05
sy1.r
spr06
sy1.r
sum06
sy1.r
junk
alex
junk
bill
work
course
cop3212
fall05
grades
prog1.r
prog2.r
fall06
prog2.r
prog1.r
grades
这种遍历的策略称为前序遍历(preorder traversal)。在前序遍历中,对结点的处理工作是在它的诸儿子结点被处理之前进行的。当该程序运行时,显然第1行对每个结点恰好执行一次,因为每个名字只输出一次。由于第1行对每个结点最多执行一次,因此第2行也必然对每个结点执行一次。不仅如此,对于每个结点的每一个儿子结点第4行最多只能被执行一次。不过,儿子的个数恰好比结点的个数少1。之后,第4行每执行一次,for循环就迭代一次,每当循环结束时再加上一次。因此,每个结点总的工作量是常数。如果有N个文件名需要输出,则运行时间就是O(N)。
另一种遍历树的常用方法是后序遍历(postorder traversal)。在后序遍历中,在一个结点的工作是在它的诸儿子结点被计算后进行的。例如,下图表示的是与前面相同的目录结构,其中圆括号内的数代表每个文件占用的磁盘块的个数。
由于目录本身也是文件,因此它们也有大小。设我们想要计算被该树所有文件占用的磁盘块的总数。最常见的做法是找出含于子目录/usr/mark(30),/usr/alex(9)和/usr/bill(32)的块的个数。于是,磁盘块的总数就是子目录中的块的总数(71)加上/usr使用的一个块,共72个块。以下的伪代码方法size实现了这种遍历策略。

int FileSystem::size ( ) const
{
int totalSize = sizeOfThisFile( );
if( isDirectory( ) )
for each file c in this directory (for each child)
totalSize += c.size( )
return totalSize;
}如果当前对象不是一个目录,那么size只返回它所占用的块数。否则,被该目录占用的块数将被加到其所有子结点(递归地)找到的块数中去。为了区别后序遍历策略和前序遍历策略,下段代码显示了每个目录或文件的大小是如何由该算法产生的。
ch1.r
ch2.r
ch3.r
book
sy1.r
fall05
sy1.r
spr06
sy1.r
sum06
cop3530
course
junk
mark
junk
alex
work
grades
prog1.r
prog2.r
fall05
prog2.r
prog1.r
grades
fall06
cop3212
course
bill
/usr1.2 标准库中的set和map
在第3章中讨论了STL中的容器vector和list,这两者对于查找来说是不够用的。相应地,STL提供了两个附加的容器set和map,这两个容器保证了基本操作(如插入、删除和查找)的对数时间开销。
1.2.1 set
set是一个排序后的容器,该容器不允许重复。许多用于访问vector和list中的项的例程也适用于set。特别的,iterator和const_iterator类型是嵌套于set的,该类型允许遍历set。vector和list的几个方法在set中有完全相同的名字,包括begin、end、size和empty。
set特有的操作是高效的插入、删除和执行基本查找。
插入例程被恰当地命名为insert。然而,因为set不允许重复,所以,对insert来说,有可能会出现插入失败的情况。因此,我们希望返回类型是一个可以指示这种情况的布尔变量。然而,insert返回的是一个比bool类型复杂的多的类型。这是因为insert也返回一个iterator来给出当insert返回时x的位置。这个iterator或者指向新插入的项,或者指向导致insert失败的已有项。这个iterator是很有用的,因为,如果知道项的位置的话,就可以快捷地删除该项。可以直接获得包含该项的结点,从而避免了查找操作。
STL定义了一个名为pair的类模板,该类模板比struct多两个用来访问pair的两项的成员first和second。下面是两个不同的insert例程:
pair<iterator,bool>insert( const Object & x);
pair<iterator,bool>insert( iterator hint, const Object & x);单参数insert的执行如上所示。双参数insert允许对x将要插入的位置的线索说明。如果线索很精确,那么,插入就很快,通常为O(1)。如果不精确的话,就需要用常规的插入算法来完成,此时的执行与单参数insert相同。例如,下面的代码中使用双参数insert就比使用单参数insert要快得多:
set<int>s;
for ( int i=0; i<1000000; i++)
s.insert(s.end(),i);有几个版本的erase:
int erase( const Object & x);
iterator erase( iterator itr);
iterator erase( iteratorstart, iteartor end);第一个单参数erase删除x(如果找到的话),然后返回删除的元素的个数。很明显,这个返回值不是0就是1.第二个单参数erase的执行与在vector和list中完全一样。删除由iterator指定的位置的对象,返回的iterator指向在调用erase之前紧跟在itr的下一个位置的元素,然后使itr失效,因为此时的itr已经没用了。双参数erase的执行与在vector或list中相同。删除从start开始、到end终止的所有的项(不包括end)。
对于查找,set提供一个优于返回变量的contains例程的find例程,该例程返回一个iterator用以指向项的位置(如果查找失败就指向末端标识符)。这在不占用运行时间的前提下,提供了相当可观的更多的信息。find的形式如下:
iterator find( const Object & x ) const;默认情况下,排序操作使用less<Object>函数对象实现,而该函数对象是通过对Object调用operator来实现的。另一种可替代的排序方案可以通过具有函数对象类型的set模板来举例说明。例如,可以生成一个存储string对象的set,通过使用CaseInsensitiveCompare函数对象来忽略字符的大小写。在下面的代码中,set s的大小为1。
set<string,CaseInsensitiveCompare> s;
s.insert( "hello" );s.insert("HeLLo");
cout<< "The size is: " << s.size() <<endl;1.2.2 map
map用来存储排序后的由键和值组成的项的集合。键必须唯一,但是多个键可以对应同一个值。因此,值不需要唯一。在map中的键保持逻辑排序后的顺序。
map的执行类似于用pair例示的set。其中的比较函数仅仅涉及键。因此,map支持begin、end、size和enmty,但是基本的迭代器是一个键一值对。换句话说,对iterator itr,*itr是pair<KeyType,ValueType>类型的。map也支持insert、find和erase。对于insert,必须提供pair<KeyType,ValueType>对象。虽然find仅需要一个键,返回的iterator还是指向一个pair。通常使用这些操作都是不值得的,因为这会导致昂贵的语法累赘。
幸运的是,map有一个重要的额外操作可以获得简单的语法。如下所示是对map的数组索引操作符重载:
ValueType & operator[] ( const KeyType & key );operator[]的语法如下。如果在map中存在key,就返回指向相应的值的引用。如果在map中不存在key,就在map中插入一个默认的值,然后返回指向这个插入的默认值的引用。这个默认值通过应用零参数构造函数获得,如果是基本类型的话就是0。这些语法不允许修改函数版本的operator[],因此operator[]不能用于常量的map。例如,如果在例程中map是通过常量引用来传递的,那么operator[]就不可用。
下图的代码段例举了两个访问map的项的技术。首先观察第3行,左边调用operator[],因此插入“Pat”和一个值为0的double到map。同时返回指向这个double的引用。然后赋值将map中的double改为75000。第4行输出75000。遗憾的是,第5行插入“Jan”和工资“0.0”到map中,并打印出来。这或许能、或许不能得到正确的结果,这取决于应用程序。如果区分在map中的和不在map中的项很重要的话,或者,不插入到map中(因为不可修改),那么可以使用7~12行所示的一个替代的方法。那里有一个对find的调用。如果键没有找到,iterator就是末端标志符并且可以进行测试。如果键没有找到,我们可以访问在这个对中由iterator引用的第二项,该项为与键对应的值。如果itr是iterator、而不是const_iterator的话,就可以进行赋值itr->second。
map<string,double>salaries;
salaries[ "Pat" ] = 75000.00;
cout << salsries[ "Pat" ] << endl;
cout << salsries[ "Jan" ] << endl;
map<string,double>::const_iterator itr;
itr = salaries.find( "Chris" );
if( itr == salaries.end( ) )
cout << "Not an employee of this company!" << endl;
else
cout << itr->second << endl;1.2.3 搜索二叉树
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
- 若左子树不为空,则左子树上所有结点的值都小于根结点的值
- 若右子树不为空,则右子树上所有结点的值都大于根结点的值
- 其左右子树也分别为二叉搜索树

二叉搜索树的查找

二叉搜索树的插入
I>树为空,则直接插入

II> 树不空,按二叉搜索树性质查找插入位置,再插入新节点

二叉搜索树的删除
首先查找元素是否在二叉搜索树中,如果不在,则返回;存在的话,删除节点分以下四种情况:
1> 要删除的节点无孩子节点
2> 要删除的节点只有左孩子节点
3> 要删除的节点只有右孩子节点
4> 要删除的节点有左、右孩子节点
实际情况1可以与2或者3合并起来,因此真正的删除过程如下:
2> 删除该结点且使被删除节点的双亲结点指向被删除节点的左孩子结点
3> 删除该结点且使被删除节点的双亲结点指向被删除结点的右孩子结点
4> 在它的右子树中寻找中序下的第一个结点(关键码最小),用它的值填补到被删除节点中,再来处理该节点的删除问题















 1806
1806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









