






人们可以很容易地在道路上找到车道线,即使在各种各样的条件下也是如此。除非大雪覆盖地面、暴雨、道路非常脏或年久失修。虽然你们中的一些人可能已经想挑战其他司机是否真的成功地保持在线内,但即使没有任何驾驶经验,你也知道那些黄线和白线是什么。
另一方面,计算机却发现这并不容易。阴影、眩光、道路颜色的微小变化、线路的轻微障碍……人类通常仍然可以处理的所有事情,但计算机可能很难处理。以至于在 Udacity 的自动驾驶汽车纳米学位的第 1 学期,他们将五个项目中的两个集中在这个问题上。第一个是一个很好的介绍,用于向学生介绍一些基本的计算机视觉技术,例如 Canny 边缘检测。
 Canny 边缘检测
Canny 边缘检测
第二学期的第四个项目中,我们进行了更深入的研究。这一次,我们使用了一个叫做透视变换的概念,它拉伸了图像中的某些点(在这种情况下,车道线的“角点”,从车道在汽车下方的图像底部延伸到线在远处汇聚的地平线)到目的地点,在道路的情况下,它看起来就像一只鸟在头顶飞过。
 图像的透视变换
图像的透视变换
在透视变换之前,梯度(当你穿过图像时像素值的变化,就像黑暗的道路变成亮线的地方)和颜色阈值可以用来返回一个二值图像,它只在值大于你的值时被设定为给定的阈值。透视变换后,可以在该线上运行一个滑动窗口来计算车道线曲线的多项式拟合线。
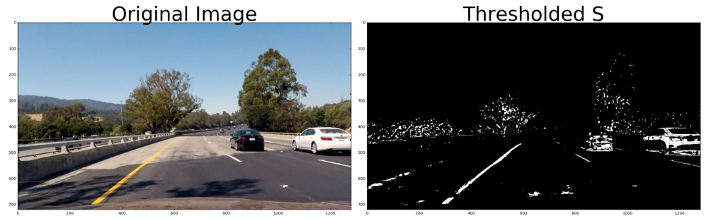 具有二元激活的“S”通道或饱和度
具有二元激活的“S”通道或饱和度
 更大阈值(左),以及由此产生的透视变换
更大阈值(左),以及由此产生的透视变换
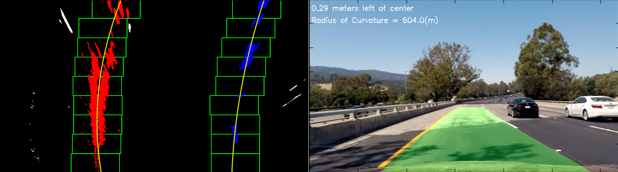 滑动窗口和效果图结果
滑动窗口和效果图结果
这似乎可以正常工作,但有一些很大的限制。首先,透视变换对于相机(在变换之前也需要单独不失真)、相机的安装,甚至汽车所处道路的倾斜度来说都是相当特定的。其次,各种渐变和颜色阈值仅在一小部分条件下有效——我一开始提到的计算机在识别车道线时遇到的所有问题在这里变得非常明显。最后,这种技术很慢——我用来将预测车道检测生成回视频的技术只能以大约每秒 4.5 帧 (fps) 的速度运行,而来自汽车的视频可能会以大约 30 fps 或更高的速度运行。

当车道检测出错时
SDCND 第 1 学期的另外两个项目专注于深度学习,在这些案例中用于交通标志分类和行为克隆(让虚拟汽车根据输入的图像以特定角度转向,在训练时复制您的行为)。五个项目中的最后一个项目也有可能采用深度学习,尽管主要方法使用了不同的机器学习技术。
数据
我的第一个决定,也许是最重要的(不幸的是,也许也是最耗时的)是决定创建我自己的数据集。尽管有很多数据集用于训练潜在的自动驾驶汽车(几乎每天都在增加),但它们大多没有标记汽车自己的车道。此外,我认为创建一个充分精选的数据集来训练深度神经网络将是一个有趣且有益的挑战。
收集数据很容易。我住在加利福尼亚州圣何塞,我可以开车去很多地方。从我之前的深度学习项目中,我知道大型数据集的重要性,但也许更重要的是,拥有一个平衡的数据集是多么重要。我在高速公路、小路上开车,沿着非常弯曲的道路上山腰,在晚上、在雨中(幸运的是,当我去收集这些数据时,加州的干旱完全逆转了)。虽然听起来可能不是很多,但我最终得到了将近 12 分钟的驾驶时间,这转化为超过 21,000 个单独的图像帧,全部来自我的智能手机。
在找到提取图像帧的好方法后,我几乎立即注意到了一个问题。虽然我在较亮的条件下开得较慢的视频主要由高质量图像组成,但夜间高速公路驾驶和雨中驾驶有大量模糊图像(我将夜间高速公路驾驶问题归咎于圣何塞高速公路的颠簸就像我手机在黑暗中的问题一样)。我必须单独检查每张图像,否则我的神经网络可能永远无法学习任何东西。我突然减少到 14,000 张图像,仍然有意留下一些稍微模糊的图像,以希望在未来进行更强大的检测。

为了实际标记我的数据集,我计划仍然使用我以前的基于计算机视觉的技术。这意味着通过我的旧算法处理图像,而不是输出顶部绘制预测车道的原始图像,而是输出六个多项式系数,或者为每条车道线输出三个值(即方程 ax² +bx+c中的 a、b 和 c)。当然,如果我只是单纯地使用我的旧算法进行标记,我只会训练我的神经网络来解决与旧模型相同的问题,并且我希望它更健壮。我决定以一种颜色(我选择了红色)手动重新绘制真实的车道线,这样我就可以使用红色通道阈值来更好地检测车道线。我原本以为我要处理 14,000 张图像,但很快意识到这会花费太长时间(除非我像 comma.ai 一样幸运/人脉广泛并且可以众包我的标签)。相反,考虑到时间对数据的影响(如果我以低速在彼此几帧内输入图像,模型可能会“窥视”它自己的验证集,因为变化不大),我决定只对十分之一的图像执行此过程,从而创建一组早期的 1,400 张训练图像。

此时,我创建了一个程序,可以在道路图像上使用我的旧的基于 CV 的模型,检测车道多项式,并重新绘制,类似于我在之前的项目中所做的。这保存了每张生成的图像,因此我可以检查哪些标签不够。我注意到了一个紧迫的问题——尽管我已经为旧模型提供了相当多的弯曲道路,但它几乎无法正确检测到所有这些道路上的线路。我输入的 1,400 张图片中有将近 450 张无法使用,其中大部分是曲线。
然而,我意识到这是由于原始方法本身的性质——滑动窗口的工作方式。如果车道线离开图像的一侧,原始滑动窗口将继续垂直向上图像,导致算法认为该线也应该朝那个方向绘制。这是通过检查窗口框是否接触到图像的一侧来解决的——如果是的话,并且窗口已经在图像上向上移动了一点(以防止模型在窗口靠近时在开始时完全失败),然后滑动窗口将停止。
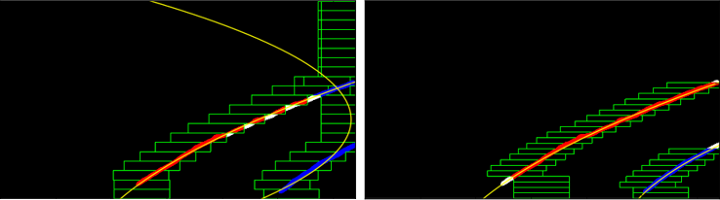 弯曲道路上的原始滑动窗口,与在边缘切割窗口搜索(也有更多窗口)
弯曲道路上的原始滑动窗口,与在边缘切割窗口搜索(也有更多窗口)
这种方法非常有效!我将失败率减半,从原来的 ~450 张失败图像减少到 ~225 张。他们仍然有很多极端曲线在这里失败,所以我想检查标签的实际分布情况。我通过使用直方图实际检查六个系数中的每一个的分布来做到这一点。我又一次失望了。数据仍然过于偏向直线。我甚至只添加了我拍摄的弯曲道路视频中的其他图像。当我查看图像时,问题仍然很明显——即使在非常弯曲的道路上,大部分车道仍然相当笔直。
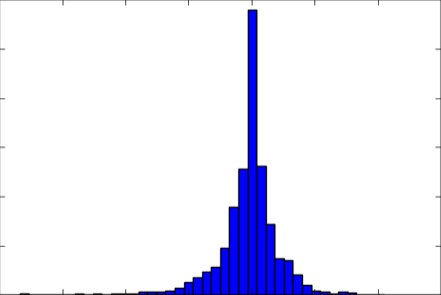
车道线系数之一的原始分布——过于集中于直线
我的独立交通标志分类项目中的一个重大差异制造者一直在通过为任何交通标志类别添加原始图像集的小旋转来创建“假”数据,而数据中的表示很少。再次使用这种方法,对于某个分布范围之外的任何系数标签(我迭代了大约外部 400、100 和 30 张图像,这意味着最远的外部实际上经历了 3倍的过程),图像被轻微旋转,同时保持同一个标签。
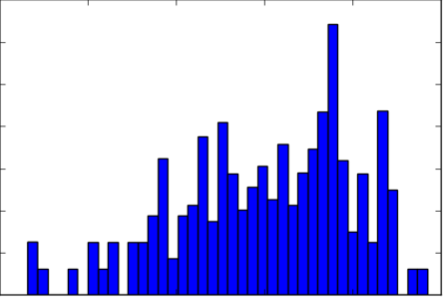
为曲线数据添加图像旋转后,单线系数的数据分布更均匀
在这个过程之后,每个系数的数据终于分布得更均匀了。我还使用了一些其他快速预处理项目来处理图像和标签。训练图像从原来的 720 x 1280 重新调整大小(我最终尝试了缩小 4 倍、8 倍和 16 倍的不同版本)并归一化(这有助于模型的最终收敛)。我还使用 sklearn 中的 StandardScaler 对标签进行了标准化(如果您这样做,请确保保存缩放器,以便您可以在模型结束时将其反转!)。这种标签规范化可能会有点欺骗你,因为训练中的损失会自动降低,但我发现绘制回图像时的最终结果也更加令人印象深刻。
下一节我们将继续创建和训练模型。
· END ·
HAPPY LIFE
















 338
338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









