






2014年的一天,我舒舒服服地躺在沙发上,看着我和加拿大朋友租的豪华滑雪别墅的篝火营地,突然,一个东西出现在我的视野里:
“着火了!着火了!着火了!” 我大喊。
几秒钟之内,我和我的朋友们就聚集在厨房里,看着我们的炸薯条着火了,在木屋里蔓延开来。 完全是恐慌。 我们必须找到一种方法来避免火势蔓延到整个房子。 我试图泼出一杯水,但没有什么可以阻止。 火越来越大了……
突然有人灵机一动:使用灭火器。 我的朋友花了很长时间才剪断绳子并准备好工作,但他很快就扑灭了火。 “嘘嘘嘘”。 这一天,火势没有蔓延,我们都可以度过一个愉快的滑雪周末,这一切都归功于良好的即时反应。

在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器
无论你是想扑灭火灾,还是被要求制造一辆自动驾驶汽车,你首先想到的往往是首要的、最重要的事情。 在开发算法时,首先错误的思考可能会让你走上错误的方向。
人们在打造自动驾驶汽车时首先想到的就是实现车道检测。 这是 Tesla 和 mobileye 所说的“强制性”任务,也是 Sebastian Thrun(自动驾驶汽车教父)在接受采访时所说的首要任务。
然而,如果这是一个很好的第一反应,那么许多工程师的初衷可能并不是最好的。 事实上,我注意到大多数帖子都在解释传统的 OpenCV 算法,这些算法由不再使用的非常旧的函数组成。 这就是为什么我想写这篇关于深度学习的文章,深度学习是当今公司所使用的。 事实上,公司主要使用 3 种方法来执行车道检测:
- 基于图像分割的方法
- 基于锚点的方法
- 基于参数的方法
注:当我谈论“车道检测”时,我实际上会谈论“车道线检测”的想法。 在研究和常识中,这两者是同化的,尽管应该有不同。
下面我们就来看看如何检测车道线吧!
1、基于图像分割的车道线检测
检测车道线的第一种也是最流行的方法是使用图像分割。 这实际上是我作为一名自动驾驶汽车工程师研究了好几个月的事情,因为它很重要,而且因为算法名称 LaneNet 被认为是实现这一目标的最佳方法。
我们有三件事需要理解:
- 如何将车道线检测视为分割问题
- 可以使用哪些架构?
- 如何从分割掩模进行曲线拟合?
1.1 如何将车道检测视为分割问题
如果你习惯于图像分割,您就会知道我的意思:我们的输入和输出都是图像。 事实上,输出图像是一个带有车道标记的分割掩模,如下图底部所示:

上:输入图像 | 中:预测| 下:标签
正如你所看到的,我们的输入是一组图像,但输出标签是相同的图像,带有重叠的分段线。 在这里,每种颜色代表一条线。 这意味着我们不仅仅进行图像分割,还进行实例分割。 多亏了这一点,我们可以区分左右线,还可以区分实线和虚线,曲线和直线,等等......
1.2 可以使用哪些架构?
大多数用于执行图像分割的模型都是编码器-解码器架构,并且根据数据集和标签,你可能拥有或多或少的类别。 你的任务是进行逐像素实例分类(对每个像素进行分类)。
该类别中最流行的架构(甚至可能在车道线检测中)是 LaneNet。 因此,我将深入研究 LaneNet,然后探索其他一些模型。
1.3 LaneNet 深入探究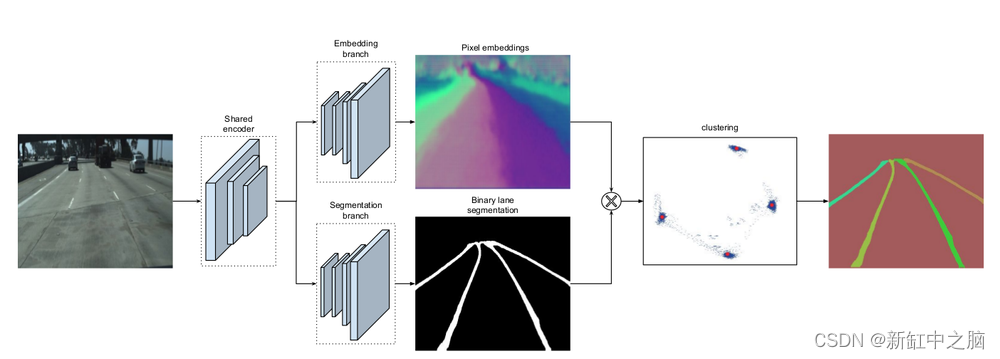
输入是图像,然后经过 E-Net 编码器(预训练的图像分割编码器),然后是两个模型头:
- 底部模型头是一组绘制二进制分割掩模的上采样层。 这个掩码是二进制的,并且简单地回答“这个像素是否属于一条线?”的问题。
- 顶部模型头是一组进行像素嵌入的上采样层。 这个术语很吓人,它实际上是在进行实例分割,其中涉及为每个像素分配唯一的嵌入(一组特征值),以便属于同一车道线的像素具有相似的嵌入,而属于不同车道线的像素具有不同的嵌入。
例如,这是这些“嵌入”的更好的可视化:

然后,我们将这两者结合起来,并使用后聚类(如 DBSCAN)将具有相似嵌入(特征)的行组合在一起。 这就是 LaneNet,其中一个分支对“线与非线”进行分类,另一个分支对“线 A、线 B、线 C 等...”进行分类,然后我们对来自同一线的像素进行聚类。
1.4 其他算法
LaneNet 是这一类别的先驱,但其他架构的效果甚至更好,例如 SCNN、RESA 或 CurveLane-NAS。
- SCNN(空间卷积神经网络)通过采用空间 CNN 层来增强车道检测,使其能够考虑像素之间的水平连接,从而提高线路连续性。
- RESA(REcurrent Spatial Attention)利用空间注意模块和循环反馈机制,通过关注顺序处理阶段的相关空间特征来确保稳健的车道预测。
- CurveLane-NAS 使用神经架构搜索 (NAS) 自动识别最佳网络架构,确保模型针对曲线车道检测的特定任务进行良好调整。
它们内部都使用不同的机制,但输出始终是分段掩码。
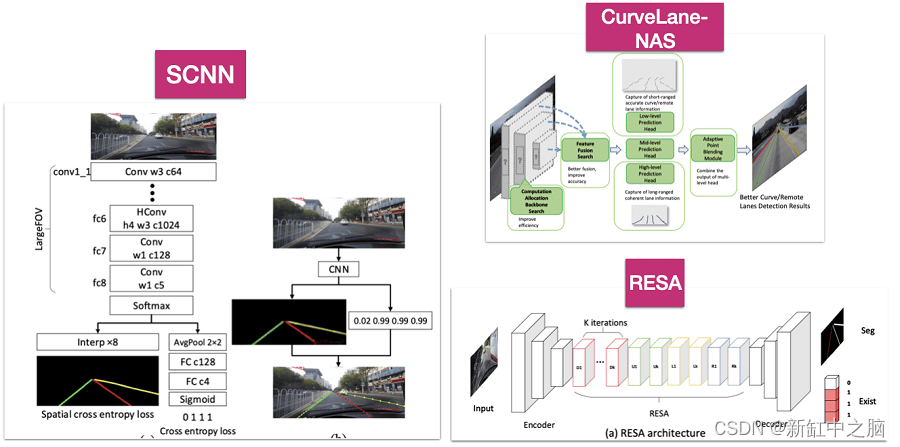
其他3种模型
接下来的问题是将分段掩码转换为可用的东西:
1.5 曲线拟合
想象一下,你正在处理衣物:你认真地花费 15 分钟将白色与彩色衣物分开,并额外花费 5 分钟确保不包含任何精致物品。 你小心翼翼地将所有东西放入洗衣机并开始工作......却在途中发现你忘记真正启动洗涤循环!
这就是当你查找分割图但不进行曲线拟合时会发生的情况。 曲线拟合是将 2D 或 3D 曲线拟合到来自相同检测车道的点的过程。
有 3 种方法可以做到这一点:
- 直接曲线拟合:这意味着直接在图像空间内拟合曲线,并且涉及找到适合 2D 平面中检测到的车道点的大多数 x 和 y 坐标的多项式。 虽然简单,但这种方法解决了对现实世界准确性(重新投影到 3D 空间时)和有效管理消失点(何时停止拟合?)的担忧。
- 鸟瞰图拟合:大多数论文都使用鸟瞰图拟合。 BEV 通常采用单应性,利用预定的源点和目标点来促进转换。 转换后,一条曲线(通常是多项式)就会拟合到车道点,从而提供更直接、通常更精确的表示。
- 神经网络拟合:在 LaneNet 等一些算法中,神经网络(称为“H-Net”)用于直接预测多项式系数或确定变换参数。 因此,神经网络进行拟合或 BEV 变换。
上述介绍的就是是基于图像分割的车道线检测方法:
- 优点:它们易于设计且像素级精确。 它们还依赖于图像分割,因此我们可以使用迁移学习,并且它们还可以检测无限车道,而无需手动编写。
- 缺点:它们很慢(只有几个 FPS),并且以相同的方式处理每个像素,因此它们无法理解同一行的像素之间的关系。
- 仅速度问题就会给自动驾驶和 ADAS(高级驾驶员辅助系统)带来问题,因为我们可能无法进行实时车道检测……
那么让我们看看第二种方法:
2、基于锚点的车道检测
第二种技术是基于锚点的,这是你想要对某些值进行回归而不是分割的地方。 这里最流行的算法是 Line-CNN、LaneAtt、SGNet 和 CondLaneNet。
在这里,我们需要明白两件事:
- 什么是锚点?
- 锚点车道检测模型的工作原理
2.1 什么是锚点?
在任何情况下(锚或其他),如果你不预测掩码,你将直接预测数字。 但什么数字呢? 请注意“锚点”这个词的使用……以前在哪里见过这个词? 是的! 在物体检测中! 在对象检测中,有时可以使用预定义边界框的锚点(行人通常是垂直的、很小的等等......)。
如果你需要复习一下,我在这里有一篇关于锚框的精彩文章。
在基于锚点的对象检测中,你的模型首先将锚框放置在各处。 例如,如果检测行人,大多数这些框将是垂直框,并且你可以像先前一样使用该知识。 然后,你可以预测检测到的边界框和锚框之间的“移位”或调整。
同样,我们可以假设一条线应该是什么样子......它可以是直线,也可以是曲线,可以是虚线,也可以是实线......你猜怎么着? 我们可以使用此信息作为“锚”。
直观上,关键思想如下:
- 锚生成 - 锚是预定义的线,在图像上生成。 在车道检测中,这些可能是代表可能的车道位置和形状的直线或曲线。 它们还可以以不同的比例和纵横比创建,以检测各种大小和方向的车道。 通常,我们然后使用诸如并交交集(IoU)之类的技术将锚点与地面实况线/框进行匹配。
- 锚“移位”/偏差:模型预测对锚的调整,调整其位置、形状和大小以与图像中的实际车道紧密对齐。 在某些情况下,我们可能还想预测每个锚的类别概率(例如,实线与虚线车道)。
- 非极大值抑制和预测:NMS 通过仅保留多个锚点重叠区域中概率最高的锚点并抑制其他锚点来消除冗余预测。NMS 后剩余的锚点代表模型对车道位置和形状的最终预测。
所以,这就是对象检测中发生的情况,我们可以对线条进行建模,只是我们使用不同的锚。 大多数模型或多或少都试图遵循这一点,让我们看看 LaneATT,它是这一类别中最先进的。
2.2 深入研究 LaneATT 模型
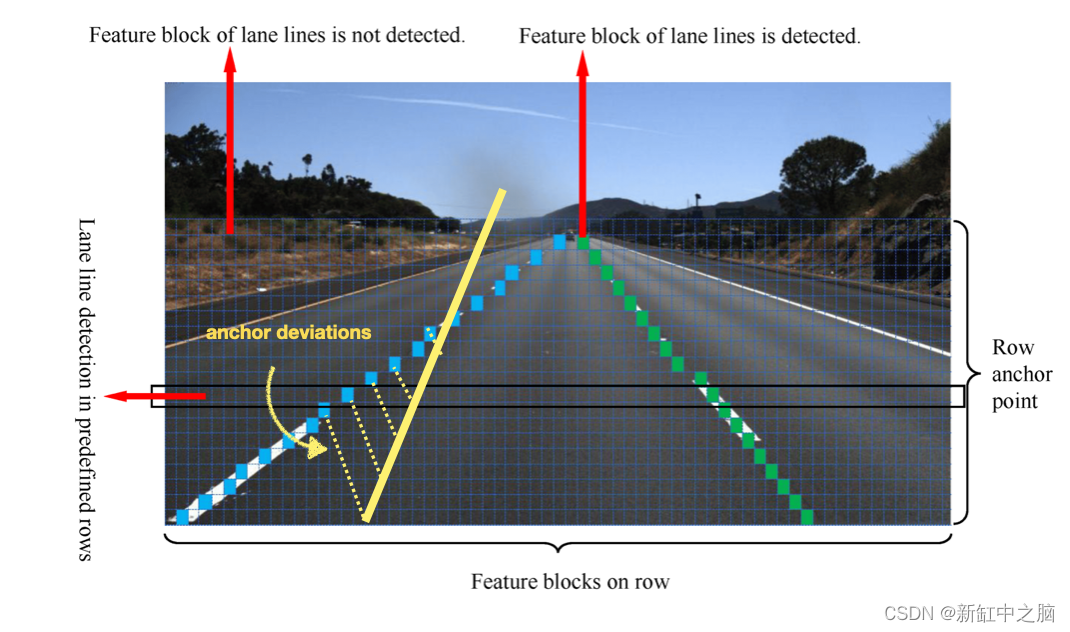
看看下图,它或多或少实现了我们所描述的内容:
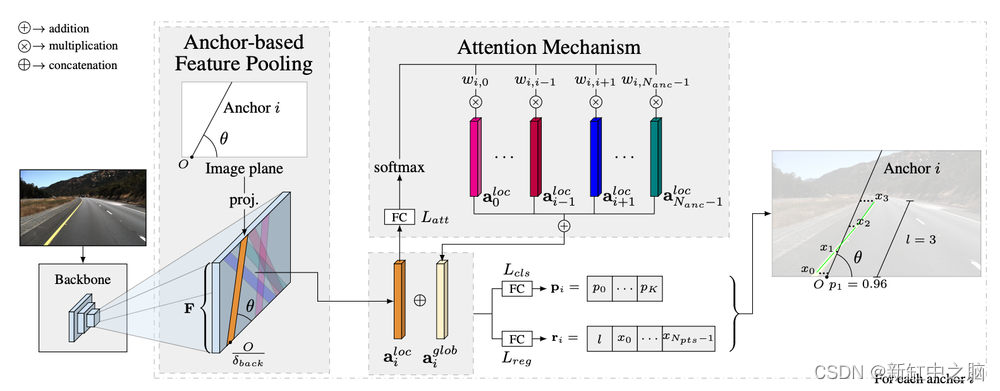
这可能并不明显,所以请尝试注意这里发生的情况:
- 特征提取:我们将图像传送到骨干 CNN。 (这里没什么需要注意的,这是第0步,以保持与前面部分的一致性)
- 锚生成:这里,我们使用注意力机制来生成锚。 我们不是在各处都有锚,而是在特征图之上使用注意力来给出可能存在线条的位置。 注意力将集中在平面和线性区域,然后我们将锚放在这里。 它将避免天空中和没有线条的区域出现线条。
锚点“移位”/偏差:对于每个锚点,我们尝试预测偏差值以获得实际的车道线。 这是一个经典的回归。 我们还进行分类步骤,预测线条的类型(虚线与实线等......) - 非极大值抑制:我们对所有重叠的检测到的车道线进行抑制,只得到几条。
所以,如果我们再看一下这张图,它看起来像这样:
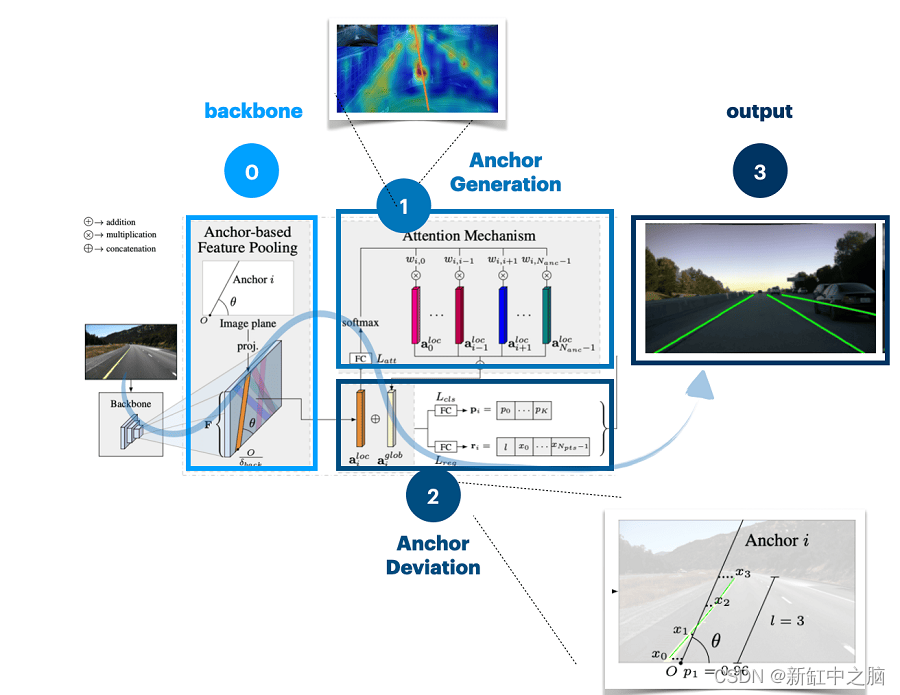
修改后的 LaneATT。 在第一步中,注意力被用来告诉我们在哪里放置锚。 在步骤 2 中,我们回归线方程并预测与锚的差异,在步骤 3 中,我们显示输出。
这就是我们如何使用锚的示例。 在对象检测中,我假设在车道线检测中,锚基于你正在使用的数据集,并对所有线条及其类别进行聚类(如果大多数车道线向右倾斜,我们将使用它作为锚点 , ETC...)。
2.3 其他算法
其他技术可能会有所不同,例如,使用行分类、条件预测、多尺度预测或其他基于注意力的模型,...
 最先进的模型(例如 LaneATT)使用注意力机制,其中一些模型使用 RNN 不仅可以预测一条线上的一个点,还可以预测一系列点。 所以我们的第二种方法就到此结束:我们想要回归锚偏差。
最先进的模型(例如 LaneATT)使用注意力机制,其中一些模型使用 RNN 不仅可以预测一条线上的一个点,还可以预测一系列点。 所以我们的第二种方法就到此结束:我们想要回归锚偏差。
这就是为什么我还想提一下 CondLaneNet,它是 LaneNet 的扩展,具有对上下文(道路、车道线等)的理解。 它使用多种机制来实现这一点,例如自注意力、RNN 和条件卷积。
你可以点击此视频查看模型在新环境中的表现。
最后:
3、基于参数的车道检测
在最后的技术中,我们将尝试回归多项式系数而不是偏差数。 毕竟,车道线只不过是一条直线或一条曲线,对吧? 因此,我们可以通过方程来定义车道线,而不是尝试通过一组点来定义车道线。
让我们看看最简单但最强大的技术:PolyLaneNet 算法:
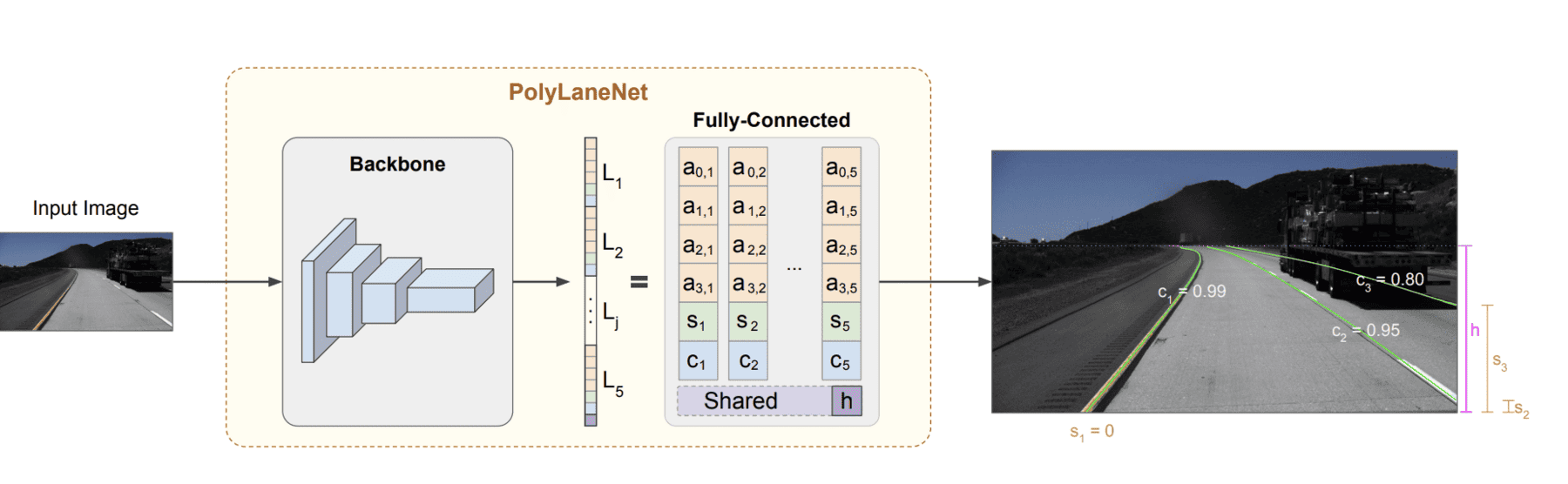
PolyLaneNet算法
我们不是使用锚或分割掩模,而是将直线同化为方程(就像我们对曲线拟合所做的那样),并尝试对系数进行回归。 这更快、更简单,但可能难以概括。 它还提出了两个问题:
- 我们拟合哪个多项式?
- 最后我们应该使用多少个神经元?
3.1 我们拟合哪个多项式?
如果你熟悉多项式,那么现在我们有其中的几个,例如:
- 一阶:ax+b,直线方程
- 二阶:ax² + bx + c,简单曲线方程
- 三阶:ax³ + bx² + cx + d,更复杂的曲线方程
哪一款适合自动驾驶? 大多数算法使用三阶多项式回归。 PolyLaneNet 就是这种情况,LSTR 也是如此,LSTR 是一种基于 Transformer 的端到端模型,也可以回归多项式系数。
3.2 最终使用多少个神经元?
这将取决于算法。 如果我们拟合三阶,则每行有 4 个参数需要猜测(a、b、c、d)。 我在 PolyLaneNet 中看到的是使用固定数量的线,假设是 4 条,如果少于 4 条,那么这是 16 个输出神经元。 如果线路较少,一些神经元输出将被忽略。
4、传统的 OpenCV 车道检测方法怎么样?
当我第一次开始使用计算机视觉和车道线检测时,是在 Udacity 自动驾驶汽车纳米学位,它有自己的车道线检测项目。 事实上,它有两种,一种是直线,另一种是曲线。
这两个项目都包括传统的计算机视觉技术如canny边缘检测、霍夫变换、感兴趣区域、转换成灰度图像、运行滑动窗口、选取高强度值以及将传统算法应用于原始图像的所有内容。 你可以在网上找到许多 Python 中的 opencv 方法,但我更愿意告诉你......
我尝试在自动驾驶航天飞机上使用它,但完全失败了。 它不仅不够强大,无法处理我的场景和线路(在法国),而且速度也非常慢。 几个 FPS 最大值,在视频帧上花费了很长时间,这是因为使用了传统技术。
点击这个视频查看我的项目。
因此尝试了其他混合传统学习和深度学习的方法。 其中之一涉及找到可行驶区域,然后将轮廓视为线。 可驾驶区域检测运行速度极快(1070 上为 100 FPS)并且非常可靠,但也存在泛化问题,尤其是当我拍摄轮廓时。
例子:
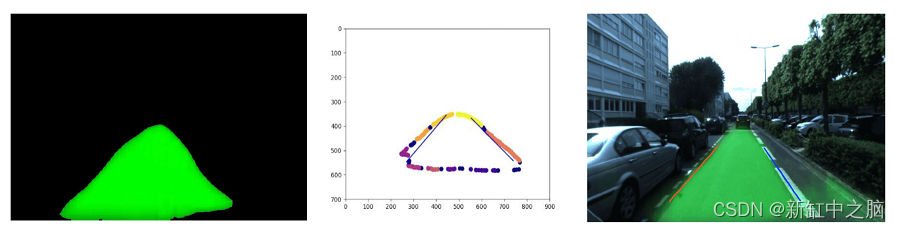
通过轮廓提取进行曲线拟合在某些情况下可能有效,但它不可推广
除非你有充分的理由使用传统方法(除了缺乏知识),否则我建议你使用深度学习。 你有 3 种方法可供选择,所以现在让我们看一些示例,并进行总结...
5、示例#1:Nvidia 的 LaneNet
Nvidia 制作了大量视频来展示他们在 Perception 中的工作。 其中一个视频是关于他们称之为 LaneNet 的算法的。 它可能是我们的 LaneNet,也可能是自定义的,但这是解释视频和结果:

6、示例#2:特斯拉的车道语言
特斯拉在车道线检测方面也很擅长。 为此,他们构建了 HydraNet 的扩展,专门用于车道检测。 这意味着它们有一个模型头来检测物体、交通标志等……还有一个头部是另一个专门用于车道线的神经网络。
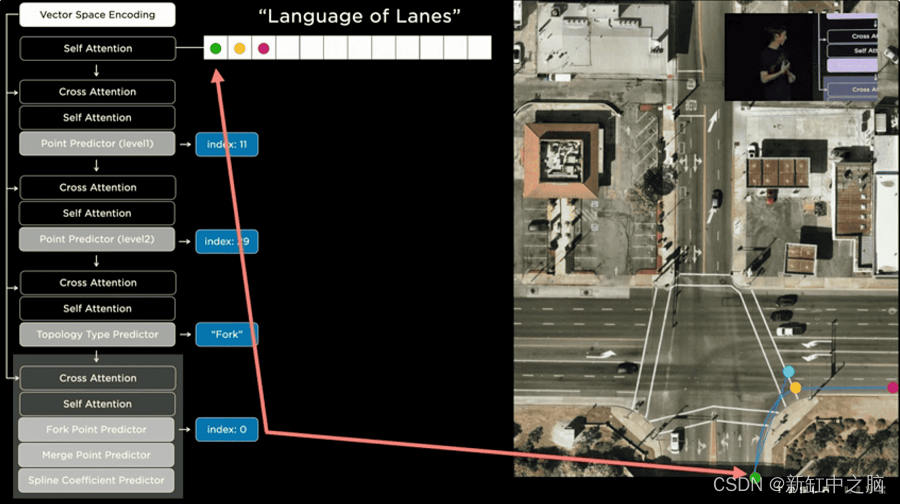 此扩展正在创建一种“车道语言”,它依赖于标注、嵌入和学习线路的连续性。 然而,当被问及系统的复杂性时,它似乎比我们的其他模型大得多:
此扩展正在创建一种“车道语言”,它依赖于标注、嵌入和学习线路的连续性。 然而,当被问及系统的复杂性时,它似乎比我们的其他模型大得多:
ASHOK ELLUSWAMY(自动驾驶负责人):“我们这样做不仅仅是为了创建一个复杂的模型。我们尝试了简单的方法,例如分割道路沿线的车道,但它无法清楚地看到道路并说出 2.5 车道的情况。 ”
当听他们的演讲时,我的直觉是他们的模型是#3类别,直接回归线的系数,但首先经历这个语言的事情。 随着端到端的到来,这可能会消失并简单地成为车道线学习网络,帮助模型预测输出,而不是预测车道方程。
7、摘要和后续步骤
我们曾经实现了许多传统的车道检测技术,现在主要使用3种:基于分段、基于锚点、基于参数。
- 基于分割的方法将问题视为分割问题; 尝试将像素值映射到类别,每个类别是特定的车道或背景。 LaneNet 或 SCNN 等算法在该领域很流行。
- 基于锚点的方法使用锚点模拟对象检测; 但对于线条来说。 我们的目标是定义锚,然后计算检测到的线与这些锚的偏差。 LaneATT 模型是最先进的,并使用基于注意力的锚生成。
- 基于参数的方法直接回归直线多项式方程。 我们通常实现具有固定行数的三阶多项式(复曲线)。 像 PolyLaneNet 这样的模型是这一类别中表现最好的。
- 每家公司都在尝试自己的方法,比如特斯拉或英伟达。 其中最流行的算法(并且在 ROS 上可用)可能是 LaneNet。
如果你在某处看到火灾,灭火器可能是你的本能反应。 如果你必须建造一个机器人,或者自动驾驶汽车,这个灭火器将是车道检测。 现在可以访问这 3 个类别,但其他类别可能会存在或将来出现,比如逐行线检测的情况,它在前几年很受欢迎,但我没有在这篇文章中提及。
另一方面,mobileye 等公司最近宣布,他们不再将车道线检测用于自动驾驶。 该系统现在不再受道路上的白线或黄线引导,而是根据之前收集的数据精确地遵循其他车辆在该道路上行驶的路线。这意味着这又是一种使用车队的新驾驶方法。
8、下一步的计划
首先,你可以尝试浏览每个类别中的 1 篇或 2 篇论文,这可能会让你对这些方法的工作原理有一个很好的直觉。
- 对于图像分割论文,尝试了解他们使用的类别是什么? 他们是如何进行分类的?
- 对于基于锚的论文,尝试去实现其中一篇论文,并查看锚点是什么以及它们如何定义它们。
- 对于基于参数的论文,尝试看看模型如何概括并使用简单的直线。
其次,车道检测目前正在向 3D 发展,因为拟合 2D 曲线只是我们将其投影到 3D 之前的中间步骤。

















 775
775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









