






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达导读
本文主要介绍如何使用 YOLOv4 目标检测模型和 Darknet 框架来创建一个路面坑洞检测系统。
背景介绍
高速行驶时,道路上的坑洼会变得非常危险。当汽车或车辆的驾驶员无法从远处看到坑洼并及时刹车或将汽车快速驶离时,情况更是如此。后面的动作对其他司机也同样危险。但是,如果我们使用深度学习和目标检测来检测前方远处的坑洼呢?这样的系统一定会对我们有所帮助。这正是我们将在本文中所做的。我们将使用YOLOv4 目标检测模型和 Darknet 框架来创建一个路面坑洞检测系统。

Darknet与YOLOv4简介
Darknet 项目是一个开源对象检测框架,以为 YOLO 模型提供训练和推理支持而闻名。该库是用 C 编写的。
Darknet项目由Joseph Redmon于 2014年启动,并发布了第一个 YOLO 论文。YOLOv3 发布后不久,它被Alexey Bochkovskiy 接管,他现在维护着原始存储库的一个活跃分支。他还增加了对YOLO v4模型的支持。
YOLOv4、YOLOv4-Tiny 和 YOLOv4-CSP 是存储库中一些众所周知且广泛使用的对象检测模型。除了这些,Alexey 还在代码库中添加了一些非常好的特性:
-
-
该代码现在支持对具有 Tensor 核心的 GPU 进行混合精度训练。它可以在支持它的 GPU 上将训练速度提高约 3 倍。
在训练期间还添加了马赛克增强,这极大地提高了模型的准确性,因为它学会了在更困难的图像中检测对象(有关详细信息,请参阅第3.3节。YOLOv4 论文的其他改进)。
该代码现在还支持多分辨率训练。这会在训练模型时每 10 个批次将图像的分辨率更改为基本分辨率的 +-50%。这有助于模型学习检测更小和更大图像中的对象。但与单分辨率训练相比,它也需要大量的 GPU 内存来训练相同的批量大小。这样做的原因是,当分辨率更改为基本分辨率的 +50% 时,每隔几批,就会需要更多的 GPU 内存。
-
坑洞数据集
本文中,我们将结合两个开源数据集来获得一组规模适中且变化多样的图像,用于训练 YOLOv4 模型。
我们从Roboflow(https://public.roboflow.com/object-detection/pothole/1)获得其中一个数据集。该数据集总共包含 665 张图像,并且已经分为 465 张训练图像、133 张验证图像和 67 张测试图像。
我们使用的另一个数据集在这篇ResearchGate 文章(https://www.researchgate.net/publication/282807920_Dataset_of_images_used_for_pothole_detection)中提到。尽管作者提供了指向大型数据集的链接,但我们出于我们的目的使用了其中的一个子集。
我们以随机方式组合这两个数据集,并创建一个训练、验证和测试集。数据集只包含一个类,即 Pothole。
您无需担心数据集处理的这一阶段,因为您将直接访问最终数据集。
以下是最终数据集中的一些带标注的图像:

我们将只对数据集进行一个小的预处理,我们将在代码部分讨论其细节。
我们将在此处使用的数据集具有以下拆分:1265 个训练图像、401 个验证图像和 118 个验证图像。
训练YOLOv4模型
从这里开始,我们将讨论这篇文章的编码细节。这包括为图像路径生成文本文件的预处理步骤、配置文件的准备、数据文件的创建、训练和对测试集的评估。
有两种方法可以在这里进行。我们可以继续应该在本地系统的终端和 IDE 上执行的步骤,或者应该在 Jupyter 笔记本(可能是本地、Colab 或任何其他基于云的 Jupyter 环境)中执行的步骤。Jupyter notebook 以及所有实现细节已经可供下载。在这里,我们按照在 IDE 中开发代码和在终端中执行命令的步骤进行操作。这样,我们将获得两者的经验。如果您使用的是 Windows 操作系统,建议您使用提供的 Jupyter notebook 并在 Colab 上运行它。以下本地执行步骤是在 Ubuntu 系统上执行的。尽管请注意,如果您在本地系统上继续进行,一些实验将需要超过 10 GB 的 GPU 内存。
【1】下载数据集
要下载数据集,只需在您选择的目录中的终端中执行以下命令。
wget https://learnopencv.s3.us-west-2.amazonaws.com/pothole-dataset.zip并使用以下命令提取数据集。
unzip pothole-dataset.zip在数据集目录中,您应该找到以下目录结构:
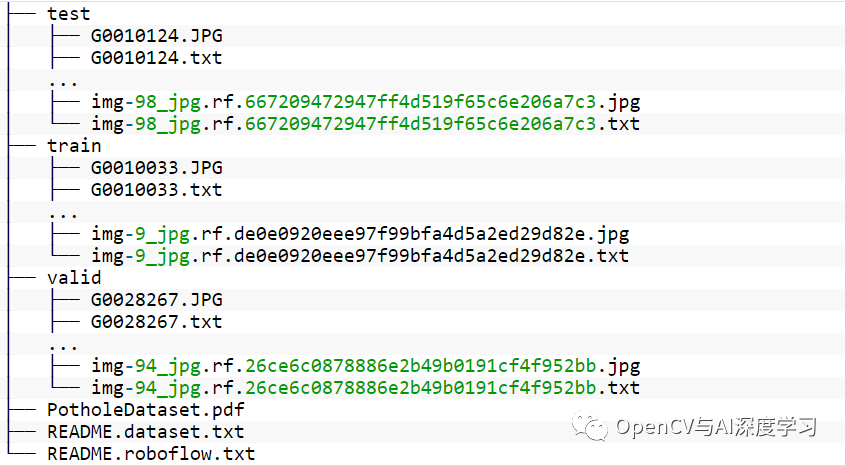
train、valid 和 test 目录包含图像以及包含标签的文本文件。对于 YOLOv4,边界框坐标需要是相对于图像大小的 [x_center, y_center, width, height] 格式。除此之外,每种情况下的标签都是 0,因为我们只有一个类。下一个块显示了一个这样的文本文件的示例。

文本文件中的每一行代表数据集中的一个对象。第一个数字是 0,代表类别。其余四个浮点数表示上述格式的坐标。
【2】克隆和构建Darknet
克隆并构建Darknet(https://github.com/AlexeyAB/darknet)。在终端中执行以下命令。
git clone https://github.com/AlexeyAB/darknet.git使用以下命令进入暗网目录:
cd darknet请注意,所有剩余的命令都将从Darknet目录执行。因此,所有路径都将相对于该目录,并且数据集目录应该是相对于Darknet目录的一个文件夹。
现在,我们需要构建Darknet。我们在此处遵循的构建过程期望 GPU 与安装的 CUDA 和 cuDNN 一起在系统中可用。打开 Makefile 并在前 7 行中进行以下更改:

现在,保存文件并在终端中运行 make
make在构建 Darknet 时,如果遇到以下错误:
opencv.hpp: No such file or directory然后您需要使用以下命令安装 OpenCV,然后再次运行 make。
apt install libopencv-dev现在准备在我们的本地系统上使用支持 CUDA (GPU) 的 Darknet。
【3】为图像路径准备文本文件
对于 Darknet YOLOv4 训练和测试,我们需要将所有图像路径保存在文本文件中。然后这些文本文件将用于映射到图像路径。
注意:文本文件中的路径应该是相对于暗网目录的。
让我们看一下代码,这将使事情变得更清晰。prepare_darknet_image_txt_paths.py 包含用于生成 train.txt、valid.txt 和 test.txt 文件的代码:
import os
DATA_ROOT_TRAIN = os.path.join(
'..', 'dataset', 'train'
)
DATA_ROOT_VALID = os.path.join(
'..', 'dataset', 'valid'
)
DATA_ROOT_TEST = os.path.join(
'..', 'dataset', 'test'
)
train_image_files_names = os.listdir(os.path.join(DATA_ROOT_TRAIN))
with open('train.txt', 'w') as f:
for file_name in train_image_files_names:
if not '.txt' in file_name:
write_name = os.path.join(DATA_ROOT_TRAIN, file_name)
f.writelines(write_name+'\n')
valid_data_files__names = os.listdir(os.path.join(DATA_ROOT_VALID))
with open('valid.txt', 'w') as f:
for file_name in valid_data_files__names:
if not '.txt' in file_name:
write_name = os.path.join(DATA_ROOT_VALID, file_name)
f.writelines(write_name+'\n')
test_data_files__names = os.listdir(os.path.join(DATA_ROOT_TEST))
with open('test.txt', 'w') as f:
for file_name in test_data_files__names:
if not '.txt' in file_name:
write_name = os.path.join(DATA_ROOT_TEST, file_name)
f.writelines(write_name+'\n')我们只需遍历包含图像文件的 train、valid 和 test 目录并创建文本文件。文本文件将在暗网目录中创建。
以下是 train.txt 文件中的几行:
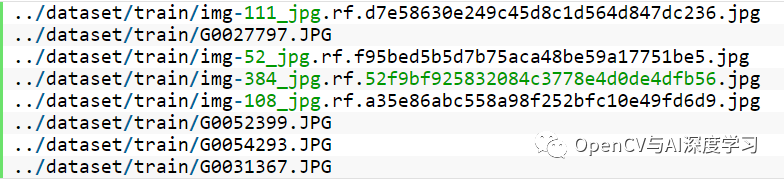
这里有两点需要注意:
-
-
-
文件的顺序已经随机化。
并且图像路径是相对于当前目录的。
-
-
我们都准备好数据集准备部分并构建Darknet。现在,让我们进入核心实验部分,即使用不同参数训练 YOLOv4 模型。
【4】训练具有固定分辨率的 YOLOv4-Tiny 模型
我们将从训练 YOLOv4-Tiny 模型开始。我们将为此创建配置和数据文件。对于配置,我们将更改要训练的批次大小和批次数,但将其他设置保留为默认值。
设置模型配置和数据文件
在 darknet 文件夹的 cfg 目录中,创建 yolov4-tiny-custom.cfg 文件的副本。将其命名为 yolov4-tiny-pothole.cfg。从这里开始,我们讨论的所有配置设置都基于 Colab 上可用的 16GB Tesla P100 GPU。您可以根据自己的可用性调整配置,但我们在这里讨论的实验和结果是基于上述硬件的设置。
在新的配置文件中,将批次从 64 更改为 32,将 max_batches 设置为8000,步骤为6400、7200。基本上,我们将训练模型进行 8000 步,批量大小为 32。学习率将计划在 6400 和 7200 步降低。接下来是过滤器和类的数量。在微型模型配置文件中,我们可以找到两个 [yolo] 层。将这些层中的类从 80 更改为 1,因为我们只有一个类。在每个 [yolo] 层之前,都会有包含过滤器参数的 [convolutional] 层。将过滤器的数量更改为(num_classes+5)*3给出的值,即18在我们的例子中。而对于微型 YOLOv4 模型,我们需要在 [yolo] 层之前的两个 [convolutional] 层中进行更改。
然后我们需要在 build/darknet/x64/data 中创建一个 pothole.names 文件。这将包含每个新行中的类名。由于我们只有一个班级,因此只需在第一行输入单词 pothole。
接下来,我们需要创建一个 .data 文件。我们为每个实验创建一个单独的文件。在 build/darknet/x64/data 中创建一个 pothole_yolov4_tiny.data。该文件将包含有关类、数据集路径和存储训练模型的位置的信息。在该文件中输入以下信息:
classes = 1
train = train.txt
valid = valid.txt
names = build/darknet/x64/data/pothole.names
backup = backup_yolov4_tiny我们指定类的数量、训练和验证文本文件路径、类名称的路径和备份文件夹路径。这是保存训练模型的文件夹。虽然我们可以为所有实验使用同一个文件夹,但我们将为每个实验创建一个新文件夹。
在我们继续之前,请确保在将保存训练模型的暗网目录中创建 backup_yolov4_tiny 文件夹。否则,训练过程将抛出错误,因为目录不是自动创建的。
这样就完成了我们在开始训练之前需要完成的所有步骤。对于进一步的实验,这将变得更容易,因为我们已经为第一个实验准备了所有配置。
为了训练模型,我们将使用已经可用的预训练微型模型。通过在终端上执行以下命令来下载它:
wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-tiny.conv.29然后在darknet目录内的终端中执行以下命令:
./darknet detector train build/darknet/x64/data/pothole_yolov4_tiny.data cfg/yolov4-tiny-pothole.cfg yolov4-tiny.conv.2 训练将需要一些时间,具体取决于所使用的硬件。训练结束时,您应该得到类似于以下内容的输出:
Saving weights to backup_yolov4_tiny/yolov4-tiny-pothole_8000.weights
Saving weights to backup_yolov4_tiny/yolov4-tiny-pothole_last.weights
Saving weights to backup_yolov4_tiny/yolov4-tiny-pothole_final.weights
If you want to train from the beginning, then use flag in the end of training command: -clear下图显示了整个训练过程中的损失图:
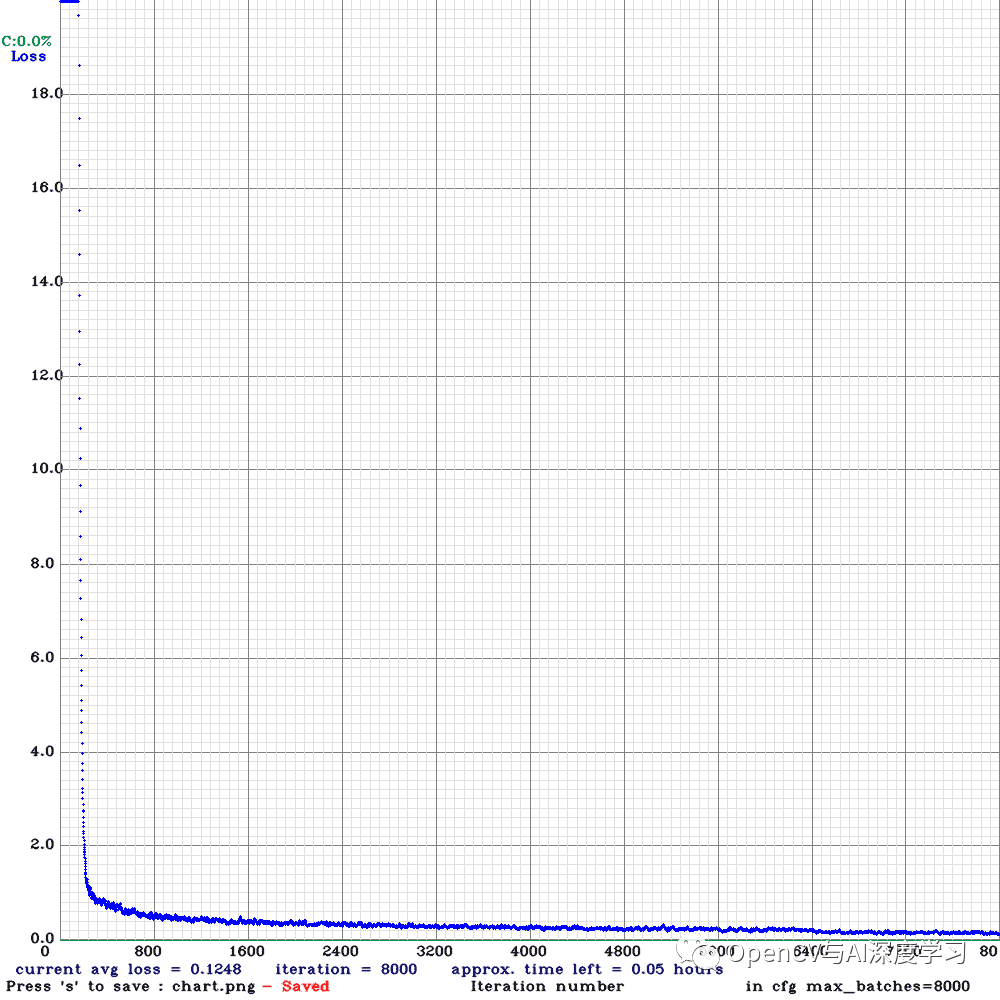
在训练结束时,具有 416×416 固定分辨率的 YOLOv4-Tiny 的损失约为 0.12。对于目标检测训练,这看起来足够低。但我们将从mAP(平均平均精度)中真正了解它的准确性。
我们将需要另一个 .data 文件来提供测试图像文件的路径。使用以下内容在 build/darknet/x64/data 目录中创建 pothole_test.data。
classes = 1
train = train.txt
valid = test.txt
names = build/darknet/x64/data/pothole.names
backup = backup_test/这里唯一改变的是有效文本文件的路径和备份文件夹名称。我们也可以使用相同的数据文件进行进一步的 mAP 测试。
由于我们现在在磁盘上有训练好的模型,我们可以执行以下命令来计算 0.5 IoU 的 mAP。
./darknet detector map build/darknet/x64/data/pothole_test.data cfg/yolov4-tiny-pothole.cfg backup_yolov4_tiny/yolov4-tiny-pothole_final.weights我们在这里得到的输出是:
IoU threshold = 50 %, used Area-Under-Curve for each unique Recall
mean average precision (mAP@0.50) = 0.400207, or 40.02 %我们得到 40.02% 的 mAP。考虑到我们在 416×416 分辨率的图像上训练了一个小型模型,这并不是很糟糕。
【5】使用多分辨率图像训练 YOLOv4-Tiny 模型
在文章的开头,我们讨论了 Darknet 支持多分辨率训练。在这种情况下,图像的分辨率从我们提供的基本分辨率每 10 批在 +50% 和 -50% 之间随机更改。
这有什么帮助?
在多分辨率训练期间,模型将同时看到更大和更小的图像。这将有助于它在更困难的场景中学习和检测对象。从理论上讲,如果我们保持所有其他训练参数相同,我们可以说这应该为我们提供更高的 mAP。
为坑洞检测的 YOLOv4-Tiny 多分辨率训练设置模型配置和数据文件
我们需要为多分辨率训练设置配置和数据文件。让我们先处理配置文件。
在 cfg 目录中创建一个 yolov4-tiny-multi-res-pothole.cfg。现在,几乎在每个模型配置文件的末尾,Darknet 都提供了一个随机参数。在 tiny 模型配置文件中,默认为 0,表示在训练过程中不会使用随机分辨率(或多分辨率)。我们需要确保在配置文件中设置了 random=1。所有其他配置和参数将与之前的训练相同,即固定分辨率 YOLOv4-Tiny 模型训练。
现在,在 build/darknet/x64/data 目录中创建一个pothole_yolov4_tiny_multi_res.data 文件,内容如下:
classes = 1
train = train.txt
valid = valid.txt
names = build/darknet/x64/data/pothole.names
backup = backup_yolov4_tiny_multi_res我们只需更改备份目录名称,并确保在darknet 目录中创建backup_yolov4_tiny_multi_res 文件夹。
要开始训练,我们只需要从暗网目录执行以下命令:
./darknet detector train build/darknet/x64/data/pothole_yolov4_tiny_multi_res.data cfg/yolov4-tiny-multi-res-pothole.cfg yolov4-tiny.conv.29请注意,与之前的实验相比,这将花费更多时间来训练,因为该模型还将在某些批次中训练更大的图像。
以下是训练结束后的损失图:
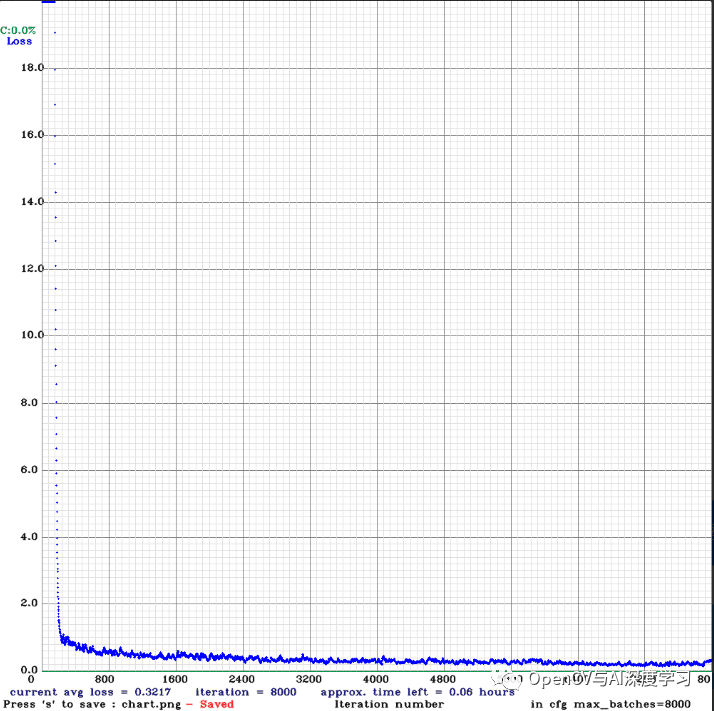
到训练结束时,损失为 0.32,与单分辨率训练相比更高。现在,这是意料之中的,因为每当在较小的图像上进行训练时,训练数据就会变得困难。但与此同时,该模型必须看到多种多样的场景,这意味着它可能学得更好。让我们看看mAP。
./darknet detector map build/darknet/x64/data/pothole_test.data cfg/yolov4-tiny-multi-res-pothole.cfg backup_yolov4_tiny_multi_res/yolov4-tiny-multi-res-pothole_final.weights这次我们得到以下输出:
IoU threshold = 50 %, used Area-Under-Curve for each unique Recall
mean average precision (mAP@0.50) = 0.415005, or 41.50 %因此,在这种情况下,我们的 mAP 略高,这也是我们的预期。
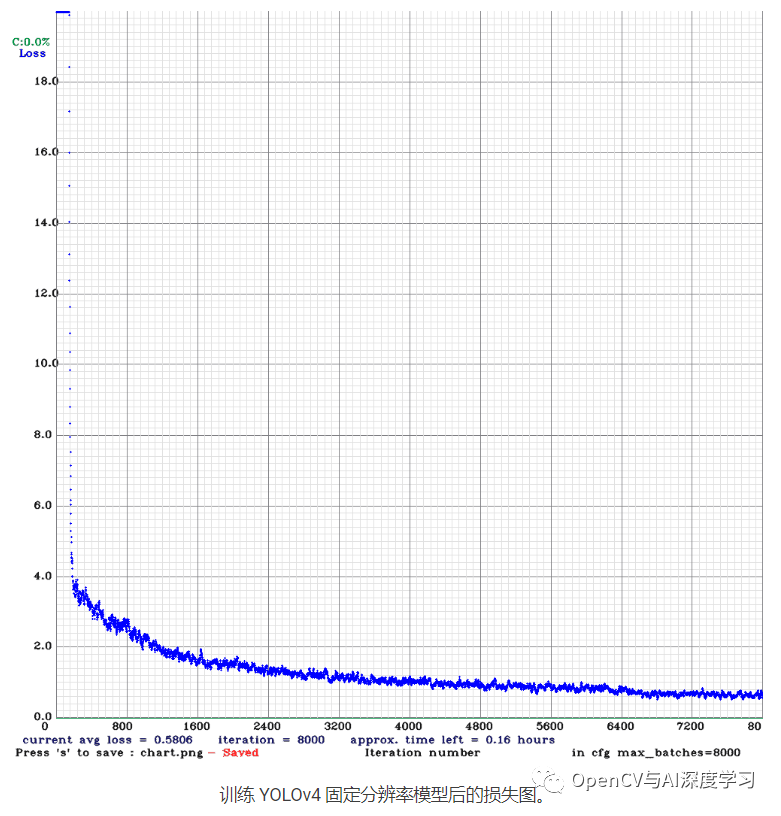
【6】使用多分辨率图像和固定分辨率图像训练 YOLOv4模型

【7】所有模型的 mAP 对比
下图显示了我们上面执行的所有运行在 0.50 IoU 阈值时的 mAP 比较。
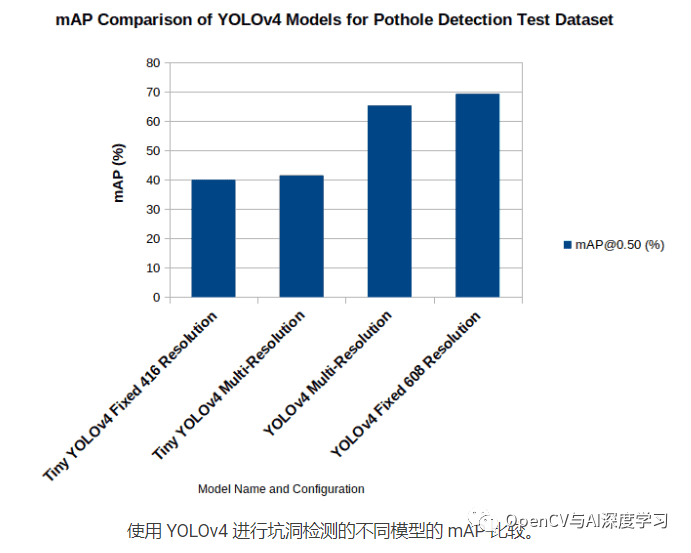
我们可以清楚地看到,对于较大的模型,固定分辨率(608×608 图像)模型提供了更好的 mAP。这很奇怪,因为多分辨率分辨率模型已经在各种规模的图像上进行了训练,并且有望提供更好的结果。但是有可能不同的规模会使数据集更难学习,因此可能需要更多的批次才能获得类似的 mAP。我们已经训练了 8000 个批次的所有模型,批次大小为 32。这大约是该数据集的 200 个 epoch。最有可能的是,为更多数量的 epoch 训练多分辨率模型应该会产生更好的结果。
到目前为止,由于多分辨率模型已经看到了更多不同的图像,我们可以预期它在检测坑洞时在现实生活中的表现与固定分辨率模型一样好。
现实场景推理
对现实生活中的坑洞检测场景进行推理
让我们使用所有 4 个经过训练的模型进行推理。在继续推理部分之前,如果您还打算对自己的视频进行推理,请确保在暗网目录中包含所有包含训练模型的文件夹(备份目录)。
我们将使用 Python (darknet_video.py) 脚本来运行推理,该脚本已稍作修改以显示视频帧上的 FPS。修改后的脚本是可下载代码的一部分。
让我们从使用具有固定分辨率的 YOLOv4 Tiny 模型进行推理开始。
python darknet_video.py --data_file build/darknet/x64/data/pothole_yolov4_tiny.data --config_file cfg/yolov4-tiny-pothole.cfg --weights backup_yolov4_tiny/yolov4-tiny-pothole_final.weights --input inference_data/video_6.mp4 --out_filename tiny_singleres_vid6.avi --dont_show对于推理脚本,我们需要提供以下参数:
-
--data_file:它与训练期间使用的数据文件相同,包含类名文件的路径和类数。
--config_file:模型配置文件的路径。
--weights:这个标志接受模型权重的路径。
--input:我们要在其上运行推理的输入视频文件。
--out_filename:生成的视频文件名。

固定 608×608 分辨率图像训练的 YOLOv4 模型测试:

结果真的很有趣。如果你还记得的话,固定分辨率模型在测试数据集上给出了超过 69% 的最高 mAP。但在这里,与多分辨率模型相比,它检测到的坑洞更少。当坑洞很小或距离较远时,它通常会失败。这主要是因为多分辨率模型在训练期间学习了较小和较大坑洞的特征。这也提醒我们,我们在特定数据集上获得的指标可能并不总是直接代表我们在现实生活用例中获得的结果。
总结
在这篇文章中,我们介绍了很多关于 YOLOv4 模型和 Darknet 框架的内容。我们首先在支持 CUDA 的 Ubuntu 系统上设置 Darknet。然后我们在 Pothole 检测数据集上训练了多个具有不同配置的 YOLOv4 模型。训练后,运行推理给了我们一个很好的想法,即有时尝试用深度学习解决现实世界的问题可能比看起来更困难。我们从不同模型中得到的不同结果非常清楚。
为了获得更好的结果,我们可能需要尝试更强大、更好的模型,甚至在训练集中添加更多的真实图像,大家有兴趣可以自己尝试。
参考链接:
https://learnopencv.com/pothole-detection-using-yolov4-and-darknet/
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~














 693
693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









