






引言
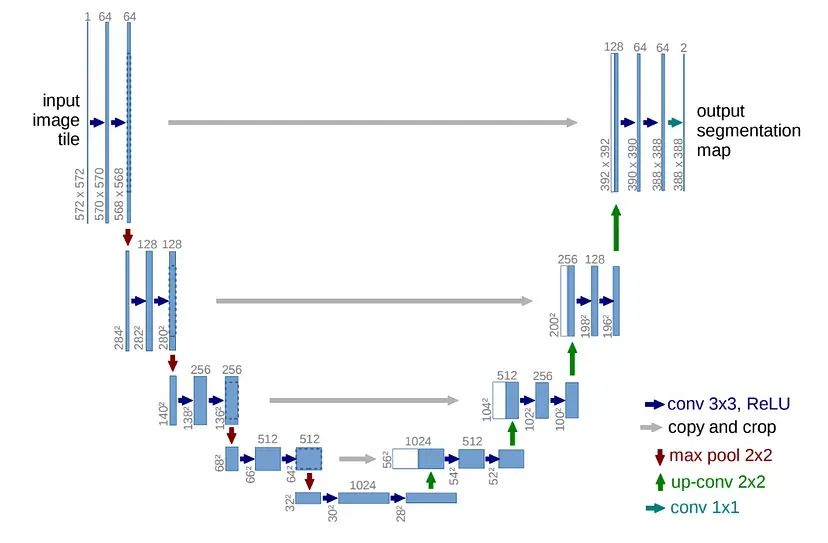
本文着重于在PyTorch框架中实现基于迁移学习的UNET架构的变体。UNET架构最初由Olaf Ronneberger等人于2015年在德国弗莱堡大学进行生物医学图像分割时开发,其名称来源于其独特的收缩和扩展路径,形成了层次结构的U形。这种架构及其变体在许多应用中被证明能够有效捕捉复杂的细节并保留空间信息。然而,在不断追求性能提升的过程中,探索各种技术仍然是至关重要的,其中之一就是整合迁移学习。
原始UNET架构
UNET架构围绕两个核心组件展开:编码器和解码器。编码器逐渐对输入图像进行下采样,捕获多个尺度的分层特征。这个过程允许模型学习输入图像中的各种模式和表示。在编码阶段之后,解码器接管并对编码的特征进行对称上采样。解码器的主要目标是从学到的特征中重建高分辨率分割地图,从而恢复空间细节。最终,解码器生成一个与初始输入图像具有相同尺寸的输出矩阵。到目前为止,这可能看起来像一个顺序的卷积“图像到图像”网络,然而,该架构的强大之处在于其利用跳过连接。
这些跳过连接在编码器和解码器中的相应层之间建立链接。通过这样做,解码器可以访问来自先前编码器阶段的高分辨率特征图,从而在上采样过程中保留细粒度的细节。编码器、解码器和跳过连接之间的这种互动使得UNET能够有效地表征图像中的对象,使其特别适用于图像分割等任务。
利用预训练模型
通过使用迁移学习方法,可以缩短UNET的训练时间,即整合已经在各种数据集上学习了如何提取复杂特征的预训练模型,增强模型的泛化能力。在UNET中,常见的做法是用预训练模型替换编码器,同时保留可训练的解码器。这是因为编码器学习适用于各种任务的分层特征,而解码器的作用更加具体。整合预训练模型将涉及选择和加载模型,识别用于特征提取的相关层,并将其与可训练的解码器无缝集成到UNET架构中。
在本教程中,我们将执行所有这些步骤,使用EfficientNet_B0预训练模型,并解决访问特定层输出以进行跳过连接的挑战——这是保留高分辨率细节的关键步骤。此外,我们将确保编码器和解码器之间的特征和尺寸大小匹配,并解决使用不同学习率训练编码器和解码器的问题。
数据集
本教程使用国防科学技术实验室(DSTL)的卫星图像数据集。原始数据集包含25个高分辨率图像(每个图像约为11兆像素,高度和宽度超过3350像素),为几个对象类别提供了分割掩码。为了适应我的方法,我将每个图像划分为224X224的元素,带有相同大小的相应掩码,从而得到5000多个非重叠的子图像,或者使用50%重叠约为18000个。这个子图像大小与EfficientNet_B0的最佳处理能力相一致。
生成的图像被分成非重叠的测试和训练组,并使用ImageNet数据集的均值和标准差进行归一化——这是用于EfficientNet_B0训练的相同数据集。请注意,原始数据的预处理和数据集准备的代码可在GitHub上找到(在文章末尾提供链接)。至于分割类别,我们将只关注类别5,该类别提供了树木、林地和其他类型植被的掩码——因为它在所有其他类别中具有最多的对象数。
模型定义
现在,让我们定义两个模型——原始UNET和基于EfficientNet_B0的版本。我们将尽可能保持它们之间的相似之处,以便能够进行更相关的比较。对于基于EfficientNet_B0的模型,我将使用其架构的前5层,其结构如下(注意第4列表示*输出*通道数):
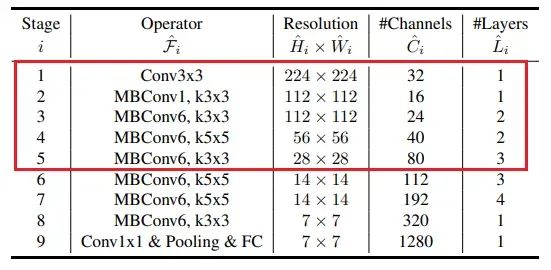
原始模型
根据EfficientNet中的层大小,以下是具有瓶颈层和相应特征大小的深度为5的UNet定义:
import torch
import torch.nn as nn
import torch.nn.functional as F
class EncoderBlock(nn.Module):
def __init__(self, in_c, out_c):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_c, out_c, kernel_size=3, padding=1),
nn.BatchNorm2d(out_c),
nn.ReLU(inplace=True),
nn.Conv2d(out_c, out_c, kernel_size=3, padding=1),
nn.BatchNorm2d(out_c),
nn.ReLU(inplace=True))
self.pool = nn.MaxPool2d((2, 2))
def forward(self, inputs):
x = self.conv(inputs)
p = self.pool(x)
return x, p
class DecoderBlock(nn.Module):
def __init__(self, in_channels, out_channels, upsample=1):
super().__init__()
if upsample:
self.upconv = nn.ConvTranspose2d(in_channels, in_channels, kernel_size=2, stride=2)
else:
self.upconv = nn.Identity()
self.layers = nn.Sequential(
nn.Conv2d(in_channels * 2, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True) )
def forward(self, x, skip_connection):
upsampled = self.upconv(x)
concatenated = torch.cat([skip_connection, upsampled], dim=1)
output = self.layers(concatenated)
return output
class DoubleConv(nn.Module):
def __init__(self, in_channels, mid_channels, out_channels):
super().__init__()
self.layers = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
)
def forward(self, inputs):
return self.layers(inputs)
class FinalLayer(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.layers = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1),
nn.Sigmoid()
)
def forward(self, inputs):
return self.layers(inputs)
class UNet(nn.Module):
def __init__(self, num_classes, input_features=3,
layer1_features=32, layer2_features=16, layer3_features=24,
layer4_features=40, layer5_features=80):
super(UNet, self).__init__()
self.num_classes = num_classes
# Layer feature sizes
self.input_features = input_features
self.layer1_features = layer1_features
self.layer2_features = layer2_features
self.layer3_features = layer3_features
self.layer4_features = layer4_features
self.layer5_features = layer5_features
# Encoder layers
self.encoder1 = EncoderBlock(self.input_features, self.layer1_features)
self.encoder2 = EncoderBlock(self.layer1_features, self.layer2_features)
self.encoder3 = EncoderBlock(self.layer2_features, self.layer3_features)
self.encoder4 = EncoderBlock(self.layer3_features, self.layer4_features)
self.encoder5 = EncoderBlock(self.layer4_features, self.layer5_features)
# Bottleneck Layer
self.bottleneck = DoubleConv(self.layer5_features, self.layer5_features, self.layer5_features,)
# Decoder layers
self.decoder1 = DecoderBlock(self.layer5_features, self.layer4_features)
self.decoder2 = DecoderBlock(self.layer4_features, self.layer3_features)
self.decoder3 = DecoderBlock(self.layer3_features, self.layer2_features)
self.decoder4 = DecoderBlock(self.layer2_features, self.layer1_features, upsample=0)
self.decoder5 = DecoderBlock(self.layer1_features, self.layer1_features)
# Final convolution
self.final_conv = FinalLayer(self.layer1_features, self.num_classes)
def forward(self, x):
# Encoder (contracting path)
output1, p1 = self.encoder1(x)
output2, _ = self.encoder2(p1)
output3, p3 = self.encoder3(output2)
output4, p4 = self.encoder4(p3)
output5, p5 = self.encoder5(p4)
# Bottleneck Layer
bn = self.bottleneck(p5)
up1 = self.decoder1(bn, output5)
up2 = self.decoder2(up1 , output4)
up3 = self.decoder3(up2 , output3)
up4 = self.decoder4(up3 , output2)
up5 = self.decoder5(up4 , output1)
# Final convolution to produce segmentation mask
res = self.final_conv(up5)
return res
# Instantiate the model
num_classes = 1 # Binary segmentation
model_orig = UNet(num_classes)让我们回顾一下这个定义及其特点。在高层次上,这个层次结构包括一个编码链、一个瓶颈层、一个解码链和一个最终分割层。现在,让我们更详细地看看每一个:
编码链 —— 一系列类似定义的块,它们的特征大小各不相同。正如原始论文所建议的,这些块每个都有2个卷积层,然后是激活函数和池化层——这些层有效地负责通过2的倍数每次减少输入特征图的空间尺寸(宽度和高度),从而增加后续层的感知野。编码器返回池化操作前后的张量——因为后者进入下一个编码器层,而前者具有更高的空间分辨率,用于跳过连接机制。值得注意的是,这里相对于原始架构引入了一个小的改进——在卷积层之后的BatchNorm组件,这有助于更快速、更稳定的收敛。
瓶颈层 —— 一个双卷积层,不使用或产生跳过连接,并在最大感受野层上操作。
解码链 —— 一系列类似定义的块,镜像编码链中的块。这些块执行以下一系列操作:
-
使用转置卷积操作对先前层的输出进行上采样,将空间大小放大2倍。
将结果张量与相应的编码器层的输出(在池化之前的层)连接起来。
通过2个卷积层运行结果,类似于在编码器中的方式。
来自编码器的跳过连接和上采样特征图的连接使得解码器能够恢复在编码过程中丢失的空间信息。
最终分割层 —— 一个单一的1x1卷积层,跟随在最后一个解码器层后面,将特征减少到1(或根据分割类别的数量)。
值得注意的是:
最后一层输出和来自编码器的跳过连接的连接有效地使特征的数量翻了一倍(假设我们设法确保这些层在特征大小上匹配)。为了保持一致性,每个解码器中的第一个卷积层将特征数量减少2倍,使其对称于匹配的编码器层。
由于努力实现与EfficientNet最大的相似性,第二个编码器层保留了空间维度(112x112用于输入和输出)。这个变化在解码器中通过一个'upsample'参数体现,在第4层中被禁用。
有了这一切,我们可以使用以下代码可视化生成的模型结构:
from torchview import draw_graph
model_graph = draw_graph(model, input_size=(1,3,224,224), expand_nested=True, depth=1)
model_graph.visual_graph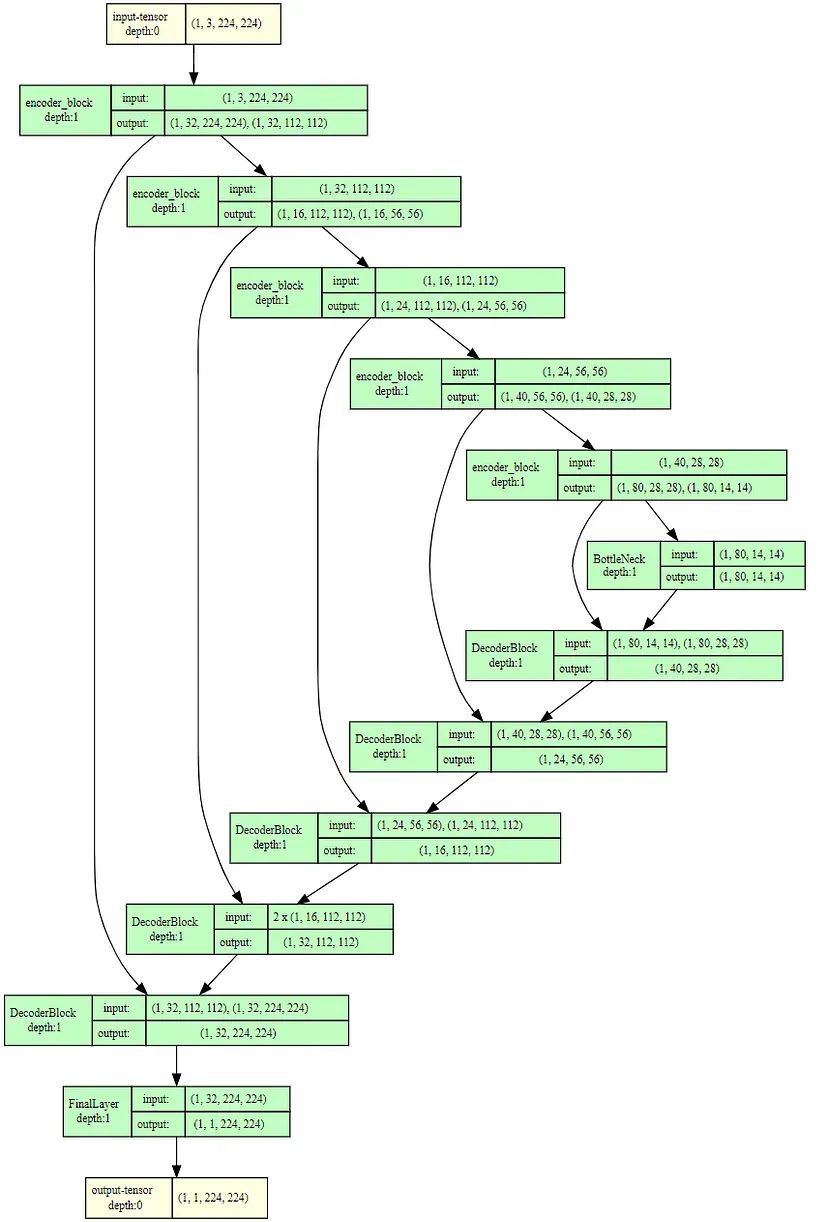
基于原始论文的UNET的结果架构
基于EfficientNet的模型
建立在迁移学习基础上的编码器的模型将使用上面定义的DoubleConv和FinalLayer类,但会需要不同的DecoderBlock。它的定义如下:
class DecoderBlock(nn.Module):
def __init__(self, in_channels, out_channels, upsample=1):
super().__init__()
if upsample:
self.upconv = nn.ConvTranspose2d(in_channels*2, in_channels*2, kernel_size=2, stride=2)
else:
self.upconv = nn.Identity()
self.layers = nn.Sequential(
nn.Conv2d(in_channels * 2, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x, skip_connection):
target_height = x.size(2)
target_width = x.size(3)
skip_interp = F.interpolate(
skip_connection, size=(target_height, target_width), mode='bilinear', align_corners=False)
concatenated = torch.cat([skip_interp, x], dim=1)
concatenated = self.upconv(concatenated)
output = self.layers(concatenated)
return output
class UNet(nn.Module):
def __init__(self, num_classes, pretrained=True,
input_features=3, layer1_features=32, layer2_features=16,
layer3_features=24, layer4_features=40, layer5_features=80):
super(UNet, self).__init__()
self.effnet = models.efficientnet_b0(pretrained=pretrained)
self.num_classes = num_classes
# # Layer feature sizes
self.input_features = self.input_features
self.layer1_features = self.layer1_features
self.layer2_features = self.layer2_features
self.layer3_features = self.layer3_features
self.layer4_features = self.layer4_features
self.layer5_features = self.layer5_features
# Encoder layers
self.encoder1 = nn.Sequential(*list(self.effnet.features.children())[0]) #out 32,112*112
self.encoder2 = nn.Sequential(*list(self.effnet.features.children())[1]) #out 16,112*112
self.encoder3 = nn.Sequential(*list(self.effnet.features.children())[2]) #out 24,56*56
self.encoder4 = nn.Sequential(*list(self.effnet.features.children())[3]) #out 40,28*28
self.encoder5 = nn.Sequential(*list(self.effnet.features.children())[4]) #out 40,28*28
del self.effnet
for param in self.encoder1.parameters():
param.requires_grad = False
for param in self.encoder2.parameters():
param.requires_grad = False
# Bottleneck Layer
self.bottleneck = DoubleConv(self.layer5_features, self.layer5_features, self.layer5_features)
# Decoder layers
self.decoder1 = DecoderBlock(self.layer5_features, self.layer4_features)
self.decoder2 = DecoderBlock(self.layer4_features, self.layer3_features)
self.decoder3 = DecoderBlock(self.layer3_features, self.layer2_features)
self.decoder4 = DecoderBlock(self.layer2_features, self.layer1_features, upsample=0)
self.decoder5 = DecoderBlock(self.layer1_features, self.layer1_features)
# Final layer
self.final_conv = FinalLayer(self.layer1_features, self.num_classes)
def forward(self, x):
# Encoder (contracting path)
output1 = self.encoder1(x)
output2 = self.encoder2(output1)
output3 = self.encoder3(output2)
output4 = self.encoder4(output3)
output5 = self.encoder5(output4)
# Bottleneck Layer
bn = self.bottleneck(output5)
up1 = self.decoder1(bn, output5)
up2 = self.decoder2(up1, output4)
up3 = self.decoder3(up2, output3)
up4 = self.decoder4(up3, output2)
up5 = self.decoder5(up4, output1)
# Final convolution to produce segmentation mask
res = self.final_conv(up5)
return res
num_classes = 1
pretrained = True让我们分解一下这个模型与经典UNET定义之间的主要区别。该模型使用EfficientNet的构建块作为编码器,通过'features'属性访问。与原始的UNET不同,EfficientNet没有池化层。因此,在这个模型中,跳过连接在进一步编码层和跳过连接之间共享相同的输出。为了解决跳过连接和下一个编码块之间分辨率差异的问题,将相同的输出传递给两者,但分辨率较低。
由于跳过连接的较小的空间大小,解码器进行了调整,这阻止了原始UNET解码器形状的保留。为了确保体系结构的相似性,使用插值将跳过连接的大小与连接之前的解码器输出对齐。这种插值方法调整张量的空间尺寸,以匹配所需的分辨率,保持了与原始UNET的输入输出形状的相似性。
当然,值得一提的是还有其他可能使体系结构匹配的方法,比如在插值而不是使用填充或在解码器中使用减小空间大小的跳过连接张量,这可能对体系结构和性能产生影响。与之前的模型类似,解码器的第4层不执行上采样,以保持空间尺寸为112x112 —— 与基于EfficientNet的编码器的第2层相匹配。最终的模型如下所示:
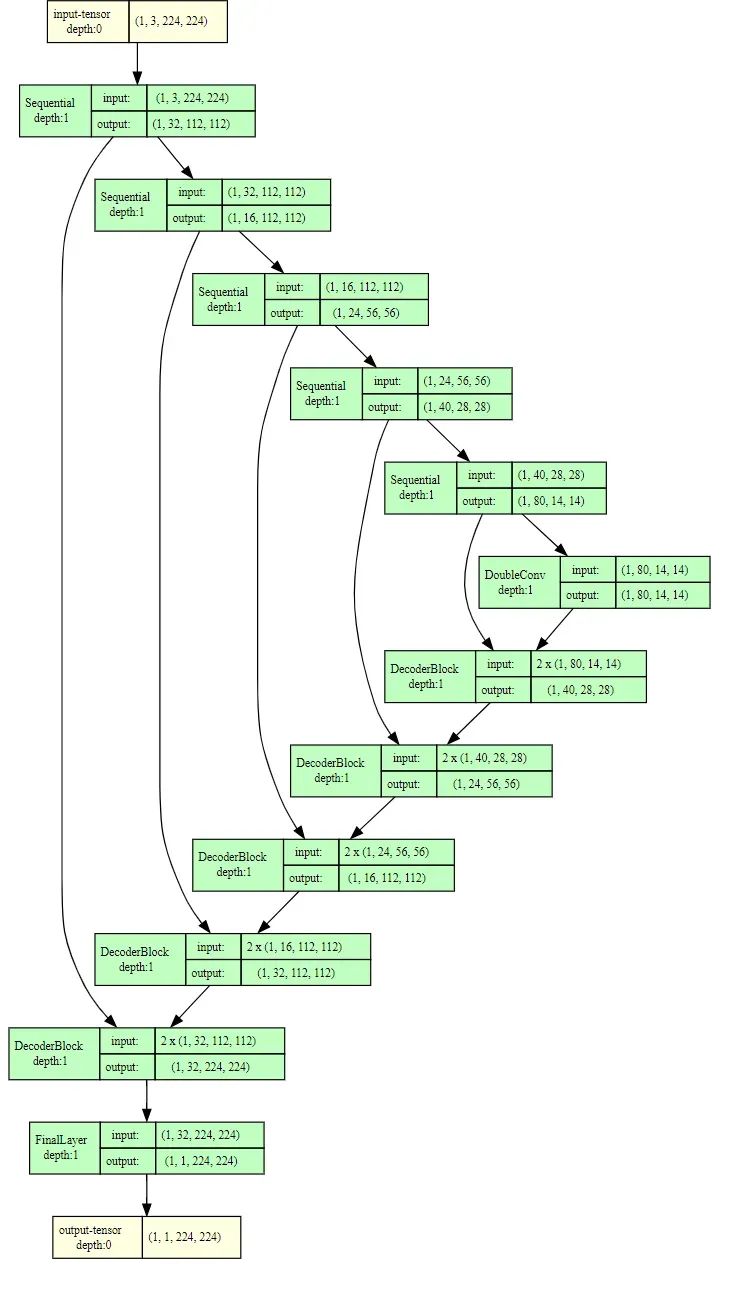
基于EfficientNet-B0的UNET的结果架构
训练循环
为了训练模型,我使用了以下规格:
学习率
在这个挑战中,我们的数据集相当小,多样性有限。由于这个原因,迁移学习方法可以显著提供帮助,引入了嵌入式知识和能力的网络,该网络在ImageNet数据集上进行了训练。考虑到这一点,在一些实验之后,我选择了解码器和瓶颈层的5e-4的学习率,而编码器的第3、4和5层的学习率为1.5e-4。在训练过程中,编码器的第1和第2层保持冻结状态。至于原始的UNET模型,我选择了所有层都统一的5e-4的学习率。
调度器
使用衰减因子为0.85的指数学习率调度器,允许在整个epoch中逐渐减小学习率,使其大约为初始学习率的1/4。这些值显示了良好的收敛性,并被采用用于训练。
训练epoch
考虑到约15000张训练图像和1200张测试图像,总共选择了10个epoch,考虑到时间约束和数据集大小。
优化器
ADAM优化器是这类任务中常用且有效的选择。
损失函数
训练过程中涉及二元交叉熵(BCE)损失和Dice损失的组合。BCE损失表示预测像素类别的负对数似然,衡量了预测和地面实况像素级分类之间的不相似性,目标是最小化这种差异。另一方面,Dice损失计算为两倍的预测和地面实况掩码的交集除以它们的和,评估分割掩码的重叠程度,强调了模型捕获对象边界和细节的能力。虽然BCE损失侧重于类别概率估计,但仅使用它可能会产生‘丑陋’、呈像素状且不连续的分割掩码,例如下图所示:
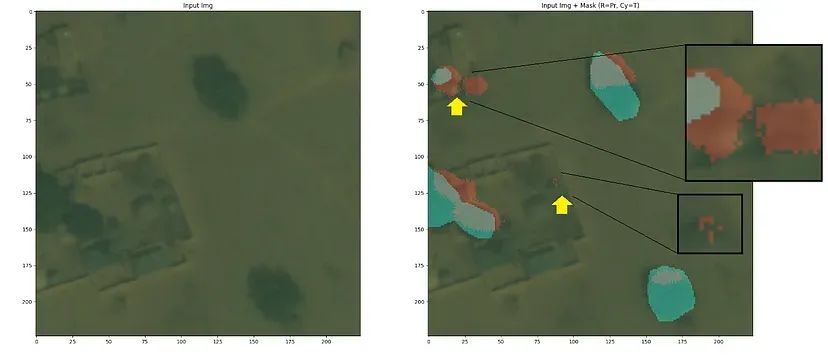 BCE损失函数产生的分割掩码工件的示例。左 — 原始图像,右 — 重叠分割掩码的图像;红色 — 预测,青色 — 实际(人工标记)
BCE损失函数产生的分割掩码工件的示例。左 — 原始图像,右 — 重叠分割掩码的图像;红色 — 预测,青色 — 实际(人工标记)
我使用了75%/25%的组合,更有利于BCE —— 这些值在超参数微调中表现良好。BCE函数在torch库中是可用的,Dice损失需要定义:
import torch.optim as optim
class DiceLoss(nn.Module):
def __init__(self, smooth=1):
super(DiceLoss, self).__init__()
self.smooth = smooth
def forward(self, inputs, targets):
smooth = 1.0 # Smoothing factor to prevent division by zero
intersection = torch.sum(inputs * targets)
union = torch.sum(inputs) + torch.sum(targets)
dice = (2.0 * intersection + self.smooth) / (union + self.smooth)
return 1.0 - dice
class CombinedLoss(nn.Module):
def __init__(self, gamma=0.85, weight_dice=0.25):
super(CombinedLoss, self).__init__()
self.criterion_BCE = nn.BCELoss()
self.criterion_Dice = DiceLoss()
self.gamma = gamma
self.weight_dice = weight_dice
self.dice_step = dice_step
def get_optimizer_and_scheduler(self, model_parameters):
optimizer = optim.Adam(model_parameters)
scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=self.gamma)
return optimizer, scheduler
def forward(self, outputs, targets, epoch):
loss_BCE = self.criterion_BCE(outputs, targets)
loss_Dice = self.criterion_Dice(outputs, targets)
loss_comb = loss_Dice * self.weight_dice + \
loss_BCE * (1 - self.weight_dice)
return loss_comb在这里,我将比较三个模型的训练结果:
# Define loss function and optimizer
criterion_BCE = nn.BCELoss()
criterion_Dice = DiceLoss()
# define and init epoch params
num_epochs = 10
lr_e = 0.0005 # Learning rate for encoder
lr_d = 0.0005 # Learning rate for decoder
# Set learning rates for different model parts
model_parameters = [
{'params': model_orig.encoder1.parameters(), 'lr': lr_e},
{'params': model_orig.encoder2.parameters(), 'lr': lr_e},
{'params': model_orig.encoder3.parameters(), 'lr': lr_e},
{'params': model_orig.encoder4.parameters(), 'lr': lr_e},
{'params': model_orig.encoder5.parameters(), 'lr': lr_e},
{'params': model_orig.bottleneck.parameters(), 'lr': lr_d},
{'params': model_orig.decoder1.parameters(), 'lr': lr_d},
{'params': model_orig.decoder2.parameters(), 'lr': lr_d},
{'params': model_orig.decoder3.parameters(), 'lr': lr_d},
{'params': model_orig.decoder4.parameters(), 'lr': lr_d},
{'params': model_orig.decoder5.parameters(), 'lr': lr_d},
{'params': model_orig.final_conv.parameters(), 'lr': lr_d},
]
# Instantiate CombinedLoss
combined_loss = CombinedLoss()
# Get optimizer and scheduler based on model parameters
optimizer, scheduler = combined_loss.get_optimizer_and_scheduler(model_parameters)
# Define function to train one epoch
def train_one_epoch(model, dataloader, optimizer, combined_loss, epoch):
model.train()
total_loss = 0
num_batches = 0
# Iterate through training batches
for batch in dataloader:
inputs, targets = batch['image'], batch['mask']
outputs = model(inputs)
loss_comb = combined_loss(outputs, targets, epoch)
optimizer.zero_grad()
loss_comb.backward()
optimizer.step()
total_loss += loss_comb.item()
num_batches += 1
epoch_loss = total_loss / num_batches
return epoch_loss
def calc_validation_loss_one_epoch(model, dataloader, combined_loss):
model.eval()
num_batches_test = 0
# Iterate through validation batches
with torch.no_grad():
for batch in dataloader:
num_batches_test += 1
inputs_test, targets_test = batch['image'], batch['mask']
outputs_test = model(inputs_test)
loss_test = combined_loss(outputs_test, targets_test)
total_loss_test += loss_test.item()
epoch_loss_test = total_loss_test / num_batches_test
return epoch_loss_test
# Initialize lists to store results
train_loss_hist = []
val_loss_hist = []
# Iterate through epochs for training
for epoch in range(num_epochs):
# Train one epoch
epoch_loss = train_one_epoch(model_orig, dataloader_train, optimizer, combined_loss, epoch)
# Calculate validation loss for the epoch
epoch_loss_test = calc_validation_loss_one_epoch(model_orig, dataloader_test, combined_loss)
model_orig.train()
# Other updates and storage as needed
scheduler.step()
train_loss_hist.append(epoch_loss)
val_loss_hist.append(epoch_loss_test)结果
原始UNET、基于预训练EfficientNet的UNET和非预训练EfficientNet的UNET。最后一个将作为仅度量模型体系结构优势相对于预训练编码器中存储的知识的参考。比较将基于10个epochs上的BCE-Dice组合损失在训练和验证数据集上。
可视化
这里是一些样本图像,以说明所有3个模型在以下224x224子图上的性能:
 所有3个模型在样本图像上的分割性能。第一行 —— 基于预训练EfficientNet的模型,第二行 —— 基于非预训练EfficientNet的模型,第三行 —— 原始UNET模型。左列 —— 图像上的真实(青色)和预测(红色)分割掩码,右列 —— 分割掩码在空白黑色背景上。
所有3个模型在样本图像上的分割性能。第一行 —— 基于预训练EfficientNet的模型,第二行 —— 基于非预训练EfficientNet的模型,第三行 —— 原始UNET模型。左列 —— 图像上的真实(青色)和预测(红色)分割掩码,右列 —— 分割掩码在空白黑色背景上。
 在验证数据集上的BCE-Dice组合损失方面,模型的性能(上图)以及训练验证数据集(下图)
在验证数据集上的BCE-Dice组合损失方面,模型的性能(上图)以及训练验证数据集(下图)
性能分析
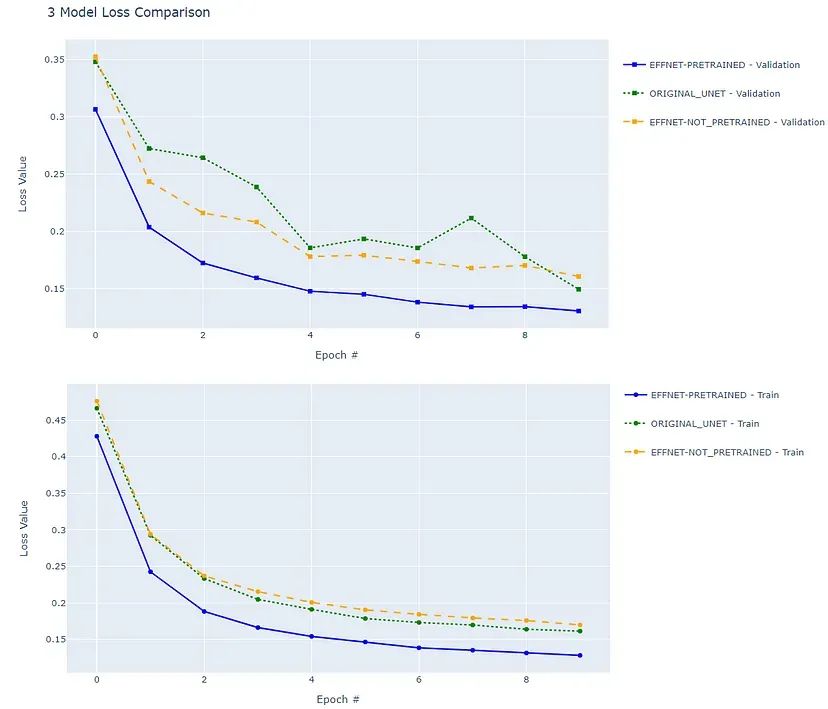
在训练与未见过的(验证)图像之间的数据使用模型的性能差距。
收敛速度:
预训练的EfficientNet-based UNet在初始损失较低的情况下启动,并在每个epoch中始终显示出色的验证损失值。这表明相对于原始UNET和非预训练的EfficientNet-based UNet模型,它能够迅速适应并学习有意义的表示,利用预训练权重中编码的知识。
稳定性:
预训练的EfficientNet-based UNet在整个训练过程中表现出一致而稳定的训练和验证损失下降。这种一致性表明其学习稳定,模型行为可靠,有助于其在生成准确分割方面的稳健性和可靠性。
原始UNET和非预训练的EfficientNet-based UNet模型显示出训练损失下降的趋势,表明学习有效。然而,它们的验证损失在逐渐下降的同时出现波动,暗示着在泛化到未见过的数据方面可能存在挑战。这些模型可能受益于正则化等技术和更复杂的学习率管理,以提高它们对新数据的适应能力。尽管值得注意的是,更平稳的收敛也可能归因于EfficientNet-based模型中编码器的较小学习率。
泛化和过拟合:
预训练的EfficientNet-based UNet在训练和验证损失之间实现了一致且接近的值,表明如预期的那样,在ImageNet上训练的编码器中具有强大的泛化能力。非预训练模型仅从我们有限的数据集中学习,该数据集较小,自然的泛化效果差,因此在训练和验证数据集之间有较大且不一致的性能差距。
10个epochs后的模型性能:
经过10个epochs,预训练的EfficientNet-based UNet模型在验证损失上明显低于其他模型,表明在未见数据上分割任务的性能更卓越。
总结
从上面我们可以得出,在评估的模型中,基于预训练EfficientNet的UNet在各个方面都表现出色。它具有更快的收敛速度,训练和验证损失均稳步下降,仅在几个epochs后验证损失值就显著较低。这表明了其可靠性和强大的学习能力。相反,尽管原始UNET和非预训练的EfficientNet-based UNet模型显示出类似的结果,验证损失呈波动但逐渐减少的趋势,收敛速度较慢且泛化到未见数据的能力较差,暗示可能存在过拟合问题。
结论和思考
正如我们所看到的,将迁移学习应用于UNET架构,特别是利用预训练模型如EfficientNet_B0,对图像分割任务显示出了令人信服的优势。更快的收敛速度,训练和验证损失的稳定减少,以及对未见数据显著卓越的性能突显了其增强的稳健性。这种技术不仅加速了训练过程,还增强了模型的泛化能力,使其能够处理各种输入,同时具有一个相对较小且相对均匀的训练数据集。
然而,采用像EfficientNet这样的预训练模型需要仔细考虑内存和可训练参数。本文中使用的EfficientNet的编码器比原始UNET编码器的参数数量多,导致内存消耗较大,可能存在潜在的约束,尤其是在计算能力有限的资源受限环境中。具体来说,我使用的原始UNET架构由441137个参数组成,所有这些参数都是可训练的,而迁移学习方法产生了一个包含728949个参数的模型,其中726573个参数用于训练 —— 大约增加了60%的模型大小 —— 这是一个确实需要考虑的大小增加。当然,可以选择更精简的架构来构建编码器,以缓解这个问题。
总的来说,迁移学习通过利用先前的知识进行高效学习,为基于UNET的图像分割提供了一种强大的策略。然而,数据集大小、模型复杂性和计算约束必须仔细审查,以满足其要求,有助于有效发挥其潜力。这种方法在增强模型性能和提高收敛速度方面具有巨大的潜力,但在各种实际场景中实现最佳结果需要细致入微的方法。
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除

















 2946
2946

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









