







简介
动物在车辆碰撞中被撞死,这种现象被称为路边死亡,是一个重要的全球问题,导致野生动物死亡率高。仅在美国,每天有超过100万种脊椎动物在车辆碰撞中丧生。全球范围内,这一数字每天超过550万,年总数超过20亿。最近的一项研究已经确定了易受危害的动物种群,例如豹(面临由路边死亡引发的绝种风险增加了83%)、巴西狼(增加了34%的绝种风险)、巴西猫(增加了0至75%的绝种风险)和南非鬣狗(增加了0至75%的绝种风险)。
野生动物车辆碰撞不仅威胁动物的安全,还可能伤害车辆乘客并造成损坏。为了解决这个问题,道路管理机构应该采取行动,例如设置公路围栏、野生动物穿越通道、逃生通道、夜间使用远光灯,以及在公路旁边使用动物传感器,以确保野生动物和人类的安全。
问题陈述
该项目旨在通过深度学习算法创建一个高效的计算机视觉模型。该模型将部署为检测系统的一部分,用于识别城市环境和高速公路上的野生动物。它将利用实时视觉来提醒人们可能与野生动物发生碰撞,增强安全措施。
数据描述
数据集1:https://www.kaggle.com/datasets/biancaferreira/african-wildlife 包括来自以前的实习生队伍的图像,这些图像来自Kaggle,这是一个开源数据存储库。该数据集包括四种不同动物物种的图像。此外,对于数据集1中的每个图像文件,都提供了以YOLO格式进行注释的文本文件。
数据集2:https://www.kaggle.com/datasets/brsdincer/danger-of-extinction-animal-image-set 由Hamoye提供,托管在Kaggle上,包含了11种不同的动物物种的图像。值得注意的是,该数据集缺乏附带的包含注释的文本文件,而且其中相当一部分图像的分辨率较低。
数据集3:https://www.kaggle.com/datasets/antoreepjana/animals-detection-images-dataset/ 来自Kaggle,包括80种独特的动物物种的图像。该数据集包括Pascal格式的带有注释的文本文件,并提供高分辨率的图像供分析使用。
数据预处理
我们通过从数据集2中仅选择高分辨率图像来提高图像质量,因为许多图像的分辨率较低,约为250像素。
对于标注,我们使用了Make Sense工具来为数据集2中选定的高分辨率图像进行标注。这对于有效训练模型是必要的。此外,我们还将数据集3中图像的标注从Pascal格式转换为YOLO格式,但仅适用于两个数据集中都存在的类别。
为了确保数据质量,我们删除了不适当的数据。具体而言,我们将豹类从数据集中排除,因为该类中的大多数图像包含其他类别。此外,我们从数据集3中加入了虎类。
数据探索性分析
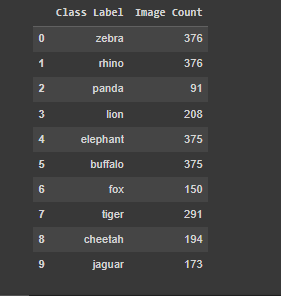
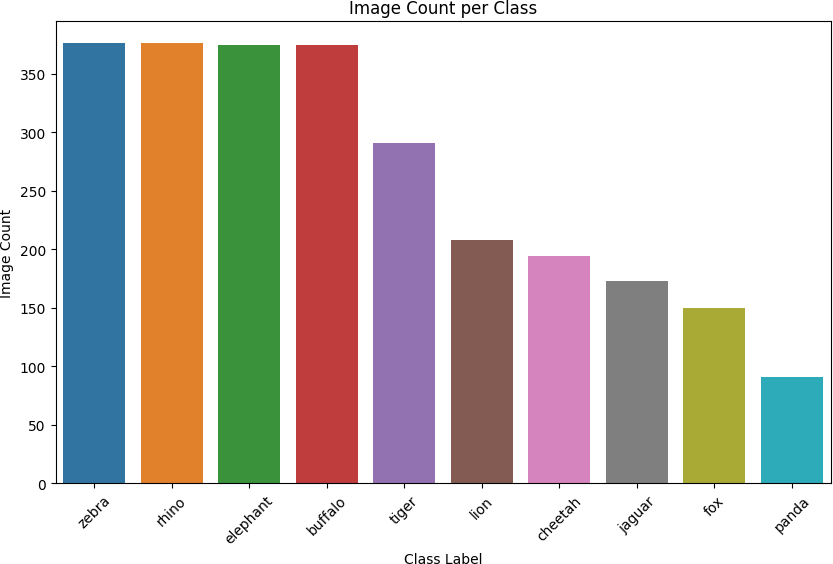
该数据集包括10种不同的动物物种的图像,分别是斑马、犀牛、熊猫、狮子、大象、水牛、狐狸、老虎、猎豹和美洲豹。总共包括2,609张图像,每张图像都附带一个包含图像中物体注释的相应文本文件。
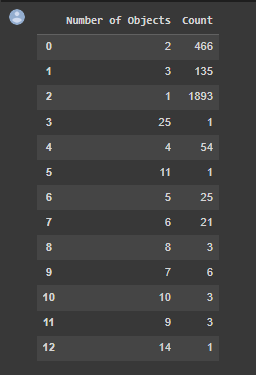
该数据集的平衡性很好,每种动物物种都得到了充分的代表。大多数图像仅包含一个或两个物体,尽管有些图像包含更多的物体。在物体检测算法中,一个重要因素是纵横比,标准差方面的中度可变性,从0.56到3.34。
每个图像中的物体数量 图像尺寸的统计数据

每个类别的图像数量
建模
我们采用You Only Look Once(YOLO)深度学习算法,具体是YOLOv8,构建了一个动物检测模型。YOLOv8提供了提高速度和准确性的增强型性能,同时为目标检测、实例分割和图像分类任务提供了统一的框架。YOLO模型通过单个网络在单次评估中有效地预测边界框和类别概率,实现了实时预测。
对于数据集管理,我们将数据集分为训练集、验证集和测试集,分割比例为0.7、0.15和0.15。使用Ultralytics包通过命令行界面实现了YOLOv8的模型。使用了预训练权重,指定任务为“检测”,模式为“训练”,模型为“yolov8n”。模型经过50个周期的训练,以达到所期望的性能。

评估
物体检测算法的性能通过均值平均精度(mAP)、F1-score和混淆矩阵等指标进行评估。
训练数据集上的模型性能
下面的PR曲线显示了在0.5阈值下的所有类别的均值平均精度(AP)为0.95。因此,它表明模型在物体检测任务中表现良好。

每个训练周期包括两个阶段:训练阶段和验证阶段。
YOLOv8 目标检测模型在不同阈值下都获得了高精度、召回率、F1-score和mAP的优秀表现。
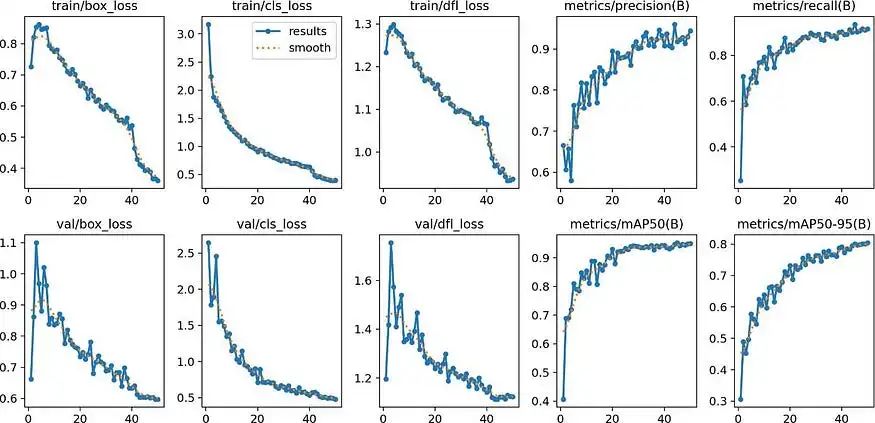
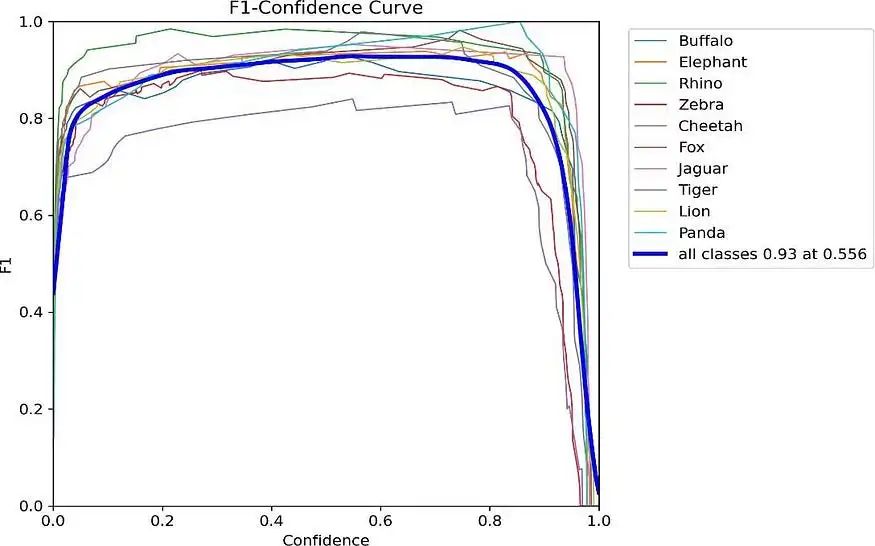
在下面的FI-Confidence曲线中,训练F1-score是在0.556的置信度阈值下为0.93,召回率为0.915,精确率为0.944,表明在准确识别和分类训练数据集中的物体方面表现均衡。
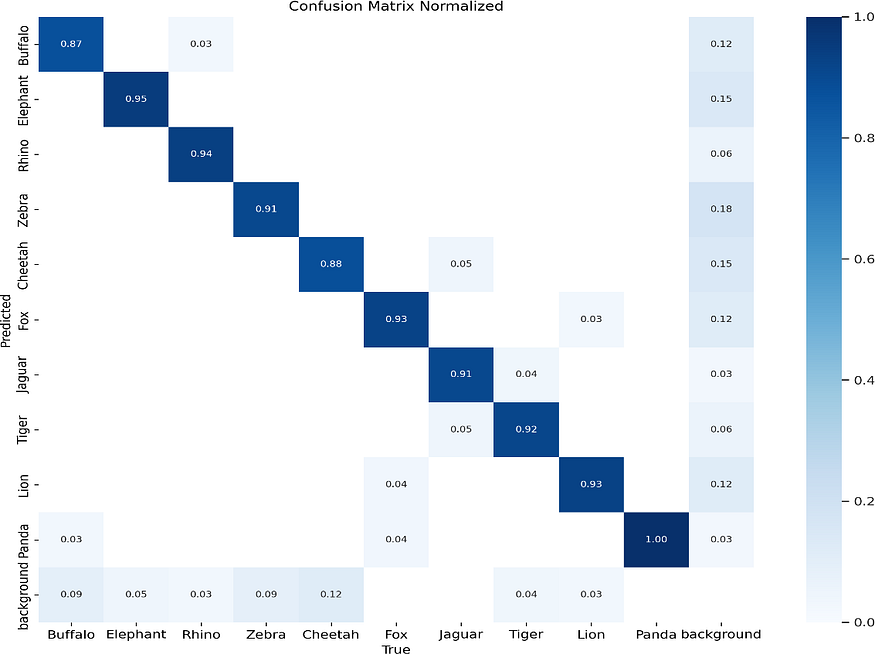
混淆矩阵
训练集
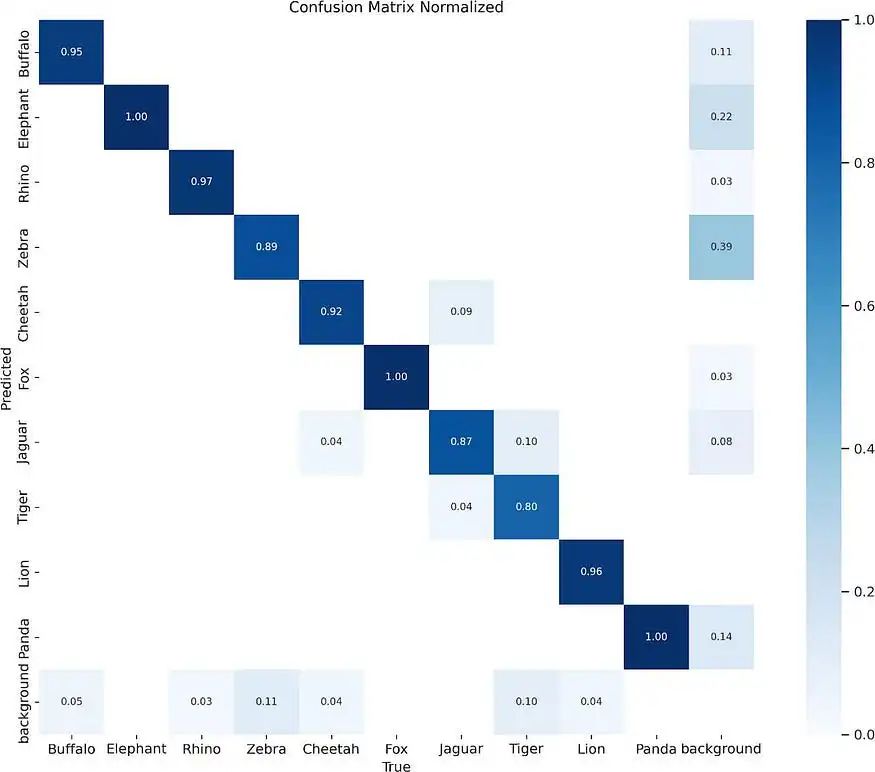
测试集
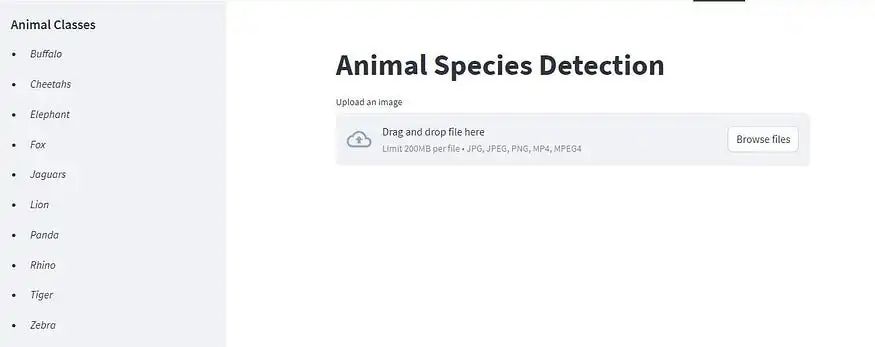
模型部署
该模型使用Streamlit在Hugging Face上部署。Streamlit是一个开源的应用程序框架。
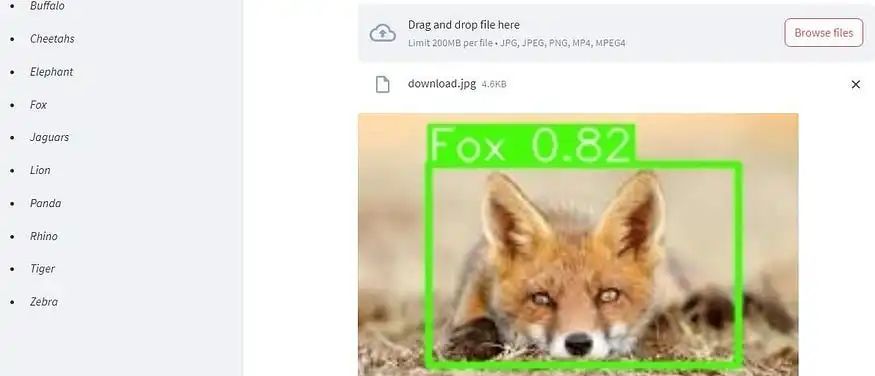
结论和建议
道路是人们和物资的重要基础设施,但当它们与自然相交时,可能会对野生动物造成伤害。我们的模型分析实时的公路图像,触发车辆中的传感器和警报,以警告司机检测到的物体。为了提高模型的准确性,我们扩展了训练数据集,涵盖了更广泛物种的范围。此外,这个模型在教育和农业方面也有应用。
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除















 2550
2550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









