






点击下方卡片,关注“小白玩转Python”公众号
在快速发展的计算机视觉领域,物体分割在从图像中提取有意义信息方面发挥着重要作用。在各种分割算法中,YOLOv9 已经成为一个强大而灵活的解决方案,提供了高效的分割能力和出色的准确性。
在这个全面的指南中,我们将深入探讨如何在自定义数据集上训练 YOLOv9 进行物体分割,并对测试数据进行推断。通过本教程,您将深入了解 YOLOv9 的分割机制,并学会如何使用自定义数据集和 ultralytics 应用它到您的项目中。
目录
步骤 1:下载数据集
步骤 2:安装 Ultralytics
步骤 3:加载 YOLOv9-seg 预训练模型和推断
步骤 4:在自定义数据集上微调 YOLOv9-seg
步骤 5:加载自定义模型
步骤 6:对测试图像进行推断
步骤 1:下载数据集
我们将使用 Furniture BBox To Segmentation (SAM) 数据集进行本教程。您可以从 Kaggle 获取 Furniture BBox To Segmentation (SAM) 数据集,Kaggle 是一个流行的数据科学竞赛、数据集和机器学习资源平台。下载数据集后,如果数据集被压缩(例如 ZIP 或 TAR 文件),您可能需要解压缩文件。
数据集链接:http://kaggle.com/datasets/nicolaasregnier/furniture
步骤 2:安装 Ultralytics
!pip install ultralytics -q导入包
from ultralytics import YOLO
import matplotlib.pyplot as plt
import cv2
import pandas as pd
import seaborn as sns步骤 3:使用预训练的 YoloV9 权重进行推断
model = YOLO('yolov9c-seg.pt')
model.predict("image.jpg", save=True)1. model = YOLO('yolov9c-seg.pt'):
这一行初始化了一个 YOLOv9(You Only Look Once)模型,用于物体分割。
该模型从名为 'yolov9c-seg.pt' 的文件中加载,其中包含了专门设计用于分割任务的 YOLOv9 架构的预训练权重和配置。
2. model.predict("image.jpg", save=True):
这一行使用初始化的 YOLOv9 模型对名为 "image.jpg" 的输入图像执行预测。
predict 函数接受输入图像并进行分割,识别并勾画图像中的物体。
save=True 参数表示分割结果将被保存。
步骤 4:在自定义数据集上微调 YOLOv9-seg
yolov9 的配置:
dataDir = '/content/Furniture/sam_preds_training_set/'
workingDir = '/content/'变量 dataDir 表示对象分割模型的训练数据所在的目录路径。训练数据存储在一个名为 "sam_preds_training_set" 的目录下,该目录位于 "/content" 目录下的 "Furniture" 目录中。类似地,变量 workingDir 表示存储主要工作文件的目录路径。
num_classes = 2
classes = ['Chair', 'Sofa']1. num_classes = 2:这个变量指定了模型将被训练以分割的类别或分类的总数。在本例中,num_classes 设置为 2,表示模型将学习识别两个不同的物体类别。
2. classes = ['Chair', 'Sofa']:这个列表包含了模型将被训练以识别的类别或对象的名称。列表中的每个元素对应一个特定的类标签。这些类别被定义为 'Chair' 和 'Sofa',模型将被训练以分割属于这些类别的物体。
import yaml
import osfile_dict = {
'train': os.path.join(dataDir, 'train'),
'val': os.path.join(dataDir, 'val'),
'test': os.path.join(dataDir, 'test'),
'nc': num_classes,
'names': classes
}
with open(os.path.join(workingDir, 'data.yaml'), 'w+') as f:
yaml.dump(file_dict, f)1. file_dict:创建一个包含数据集信息的字典:
'train'、'val' 和 'test':训练、验证和测试数据目录的路径,分别。这些路径通过将 dataDir(包含数据集的目录)与相应的目录名称连接而获得。
'nc':数据集中类别的数量,由变量 num_classes 表示。
'names':一个类名列表,由变量 classes 表示。
with open(...) as f:以写入模式('w+')打开名为 'data.yaml' 的文件。如果文件不存在,将被创建。with 语句确保在写入后正确关闭文件。
yaml.dump(file_dict, f):将 file_dict 字典的内容写入到 YAML 文件 f 中。yaml.dump() 函数将 Python 对象序列化为 YAML 格式并写入到指定的文件对象中。
model = YOLO('yolov9c-seg.pt')
model.train(data='/content/data.yaml' , epochs=30 , imgsz=640)初始化一个 YOLOv9 模型,用于对象分割,使用指定的预训练权重文件 'yolov9c-seg.pt'。然后将模型训练在由 data 参数指定的自定义数据集上,data 参数指向包含数据集配置细节(如训练和验证图像的路径、类别数量和类别名称)的 YAML 文件 'data.yaml'。
步骤 5:加载自定义模型
best_model_path = '/content/runs/segment/train/weights/best.pt'
best_model = YOLO(best_model_path)我们正在定义训练期间获得的最佳性能模型的路径。best_model_path 变量保存了存储最佳模型权重的文件路径。这些权重表示在训练数据上表现最佳的 YOLOv9 模型的学习参数。
接下来,我们使用 best_model_path 实例化 YOLO 对象。这将使用训练期间获得的最佳模型的权重初始化 YOLO 模型的一个实例。这个被实例化的 YOLO 模型,称为 best_model,现在已经准备好用于对新数据进行预测。
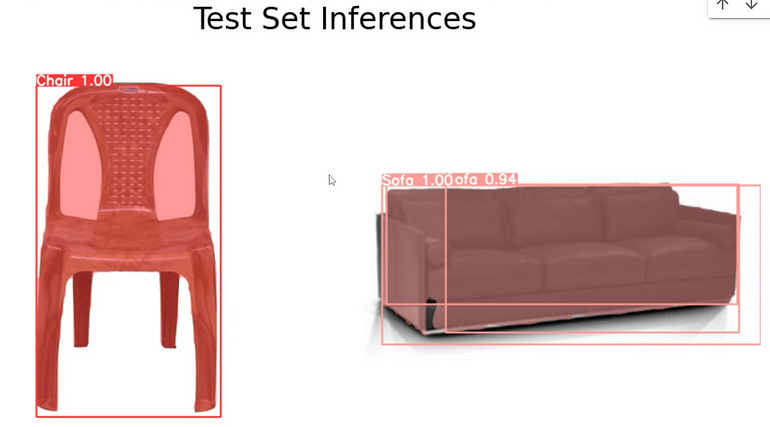
步骤 6:对测试图像进行推断
# Define the path to the validation images
valid_images_path = os.path.join(dataDir, 'test', 'images')# List all jpg images in the directory
image_files = [file for file in os.listdir(valid_images_path) if file.endswith('.jpg')]
# Select images at equal intervals
num_images = len(image_files)
selected_images = [image_files[i] for i in range(0, num_images, num_images // 4)]
# Initialize the subplot
fig, axes = plt.subplots(2, 2, figsize=(10, 10))
fig.suptitle('Test Set Inferences', fontsize=24)
# Perform inference on each selected image and display it
for i, ax in enumerate(axes.flatten()):
image_path = os.path.join(valid_images_path, selected_images[i])
results = best_model.predict(source=image_path, imgsz=640)
annotated_image = results[0].plot()
annotated_image_rgb = cv2.cvtColor(annotated_image, cv2.COLOR_BGR2RGB)
ax.imshow(annotated_image_rgb)
ax.axis('off')
plt.tight_layout()
plt.show()定义验证图像的路径:这一行构建了在 dataDir 目录中包含测试图像的目录路径。
列出目录中的所有 jpg 图像:它创建了一个包含指定目录中所有 JPEG 图像文件的列表。
以相等间隔选择图像:它从列表中选择子集图像以进行可视化。在本例中,它选择了总图像数量的四分之一。
初始化子图:这一行创建一个 2x2 的子图网格,用于显示所选图像及其对应的预测。
对每个选择的图像进行推断并显示:它遍历每个子图,对相应的选择图像使用 best_model.predict() 函数进行推断,并显示带有边界框或分割掩码的标注图像。
最后,使用 plt.tight_layout() 整理子图并使用 plt.show() 显示它们。
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除















 4072
4072











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









