







01#
导语
爱奇艺大数据技术广泛应用于运营决策、用户增长、广告分发、视频推荐、搜索、会员营销等场景,为公司的业务增长和用户体验提供了重要的数据驱动引擎。
多年来,随着公司业务的发展,爱奇艺大数据平台已积累了海量数据,这些数据分散在多个AZ(Availability Zone,可用区)的多个大数据集群里,彼此割裂、不互通,存在数据孤岛,给数据使用带来了极大的不便。业务使用数据时,需要知道数据在哪个集群,寻找起来比较麻烦。如果依赖的数据在另一个集群,需要将该数据同步到计算所在的集群,导致数据冗余,增加存储成本,且难以维护。
为了解决上述这些问题,爱奇艺大数据团队构建了多 AZ 统一调度架构,支持不同 AZ、不同集群间数据读写路由、计算调度路由,使得业务可以无感访问不同集群上的数据,在不同集群间无感迁移数据、按需调度计算,大幅降低存储计算成本,提升数据开发与分析效率。
02#
爱奇艺大数据简介
2.1 爱奇艺大数据体系
爱奇艺大数据体系构建在 Hadoop、Spark、Flink等开源大数据生态之上,提供了数据采集、数据湖、实时与离线计算、机器学习、数据分析等多种基础服务,并自研了日志服务中心、大数据开发平台、机器学习平台、实时分析平台等一系列大数据相关平台,打通数据采集、数据处理、数据分析、数据应用等整个数据流程,提升数据的流通效率。
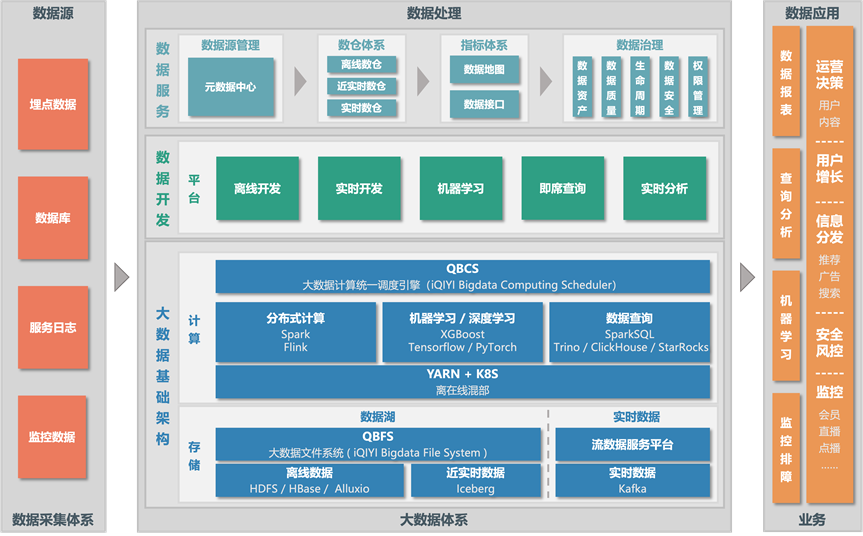 图1 爱奇艺大数据体系
图1 爱奇艺大数据体系
2.2 需求与挑战
在多 AZ 统一调度架构落地前,爱奇艺大数据分布在多个 AZ 内的 7 个Hadoop 集群上,其部署模式如图 2 所示。
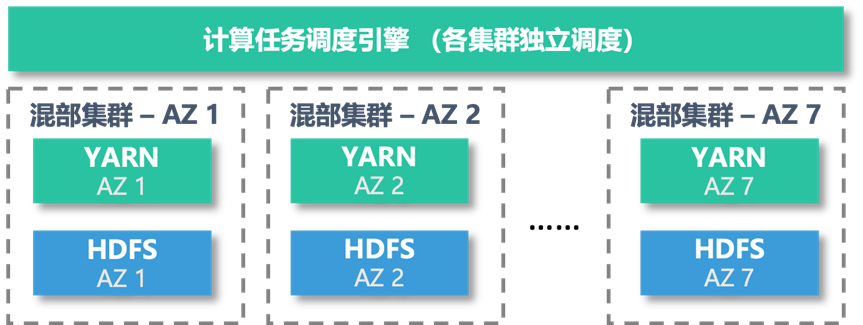
图2 爱奇艺大数据集群旧部署模式
使用方式及问题如下:
大数据团队根据各个业务的数据与计算资源需求,事先规划将不同业务分配到不同集群上,这决定了各个集群的规模。但随着业务的发展,事先规划往往赶不上实际变化。由于数据、计算被绑定在某个集群上,没法跨集群自由调度,各个集群的负载容易变得不均衡。我们多次遇到机房瓶颈导致某个集群无法扩容,只能整个业务或者整个集群搬迁,带来非常大的工作量。
业务创建数据、读取数据、提交计算任务等日常操作都需要指定集群,带来不必要的学习成本,影响数据开发与分析效率。
不同集群拥有各自的元数据中心,元数据不互通,没法跨集群访问,导致如果依赖的数据在另一个集群,需要同步到本集群才能访问,造成数十 PB 的数据冗余,大量浪费存储成本,且数据同步任务维护成本高。
要解决这些问题,一种思路是构建一个超大的单一集群,但超大规模集群容易遭遇性能瓶颈、机房物理空间限制,且需承担较大的稳定性风险和维护代价。
为了在多集群的基础上解决上述问题,爱奇艺大数据团队提出多 AZ 统一调度架构的解决方案,目标是打通底层集群间的物理屏障,提供统一的存储、计算资源池,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 698
698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









