






01#
导言
Alluxio 是一款开源分布式数据编排系统,它介于存储与计算之间,提供了分布式缓存、全局数据访问等能力,为跨集群大数据分析、AI 训练等场景提供数据加速服务。Alluxio 提供统一的客户端 API 和全局命名空间,使应用程序能够通过一个通用接口连接到多种存储系统,解决了数据访问延迟和存储系统兼容性的问题。
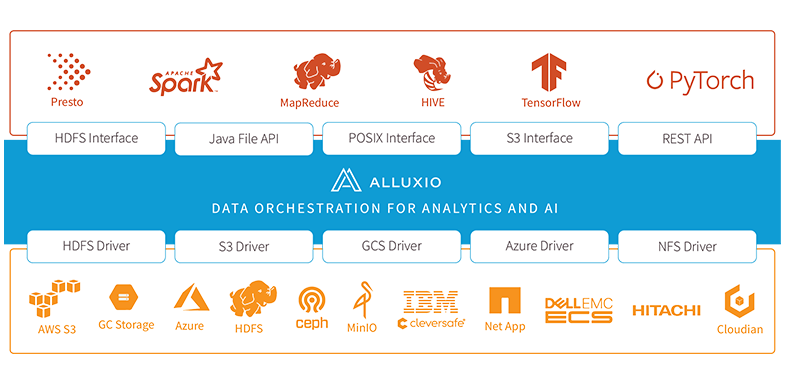 图 1 Alluxio 架构
图 1 Alluxio 架构
在爱奇艺,我们主要利用 Alluxio 的分布式缓存能力,用于减少分散在多个 AZ (Availability Zone,可用区)的大数据集群跨 AZ 数据传输,节省专线带宽。同时,我们也将 Alluxio 用于解决数据分析场景下 OLAP 存储计算分离架构带来的数据查询延迟变大的问题,提升分析性能。
本文将介绍 Alluxio 缓存在这两个场景下的集成方案与管理策略,以及实践过程中遇到的问题和解决方法。
02#
Alluxio在大数据多AZ统一架构的应用
爱奇艺大数据分散在多个 AZ 的集群中,我们构建了多 AZ 统一调度架构(如图 2 所示,详情见《爱奇艺大数据多 AZ 统一调度架构》),实现跨集群的数据无缝访问和计算调度,显著降低了存储和计算成本。
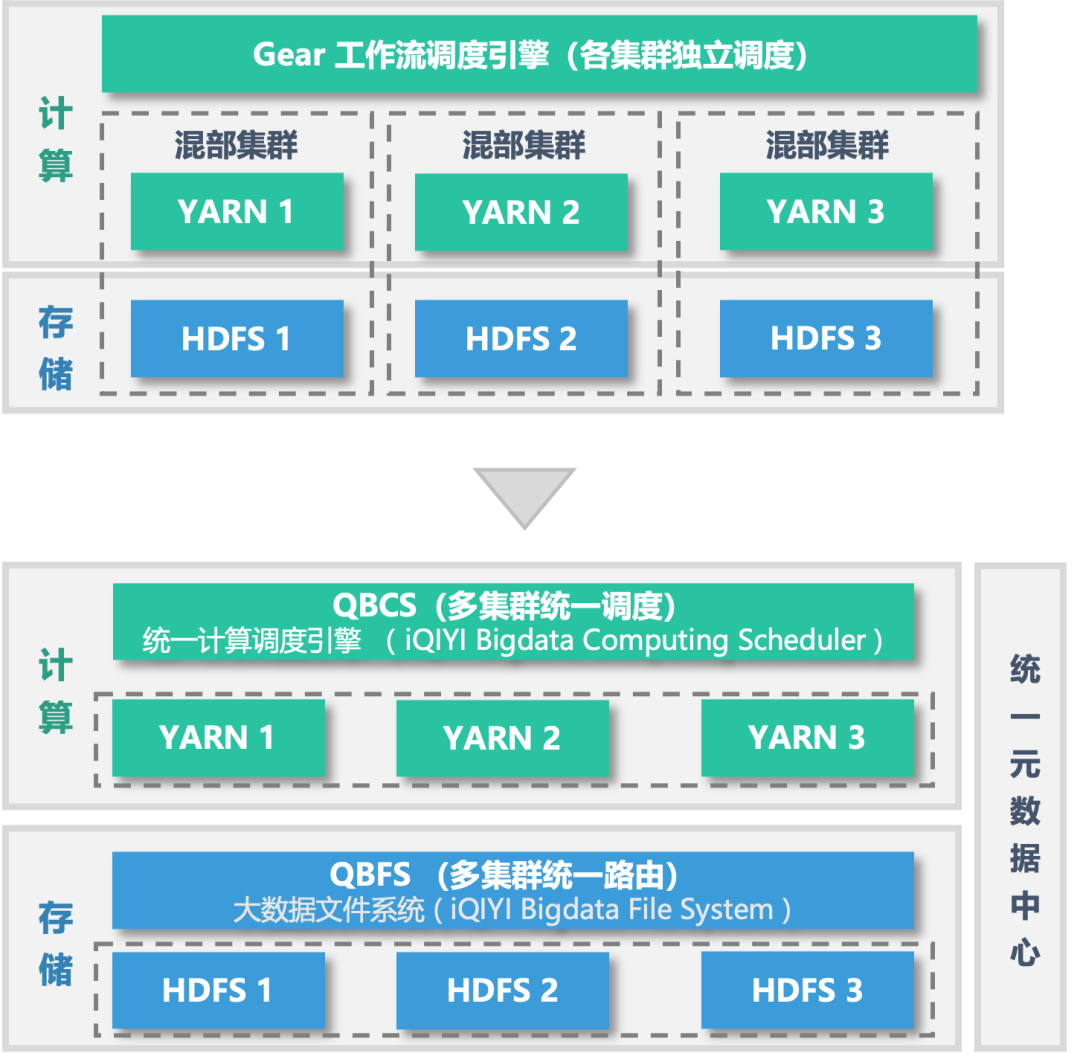 图 2 从多 AZ 演进为统一 AZ
图 2 从多 AZ 演进为统一 AZ
在多 AZ 统一调度架构中,不同集群上的数据通过自研的 QBFS (iQIYI Bigdata FileSystem) 大数据文件系统进行统一路由。上层 Spark、Flink 等大数据计算框架统一对接 QBFS,无需关心数据在哪个集群上,这引发大量的跨 AZ 数据访问,带来跨 AZ 传输延迟、性能波动及专线网络流量等新挑战。为此,我们引入 Alluxio,与 QBFS 大数据文件系统集成,构建了跨 AZ 的 QBFS-Alluxio 缓存系统,根据数据热度自动加载热数据,减少跨 AZ 传输,节省专线带宽成本。
2.1 QBFS-Alluxio缓存体系
QBFS 是一个虚拟文件系统,屏蔽底层不同存储服务的细节,向上层计算引擎暴露统一的命名空间。其底层支持多种存储类型(如 HDFS、私有云对象存储、公有云对象存储等),并支持 Alluxio 缓存系统。QBFS 提供跨集群/跨文件系统的统一命名空间、缓存加速、分层存储等功能。
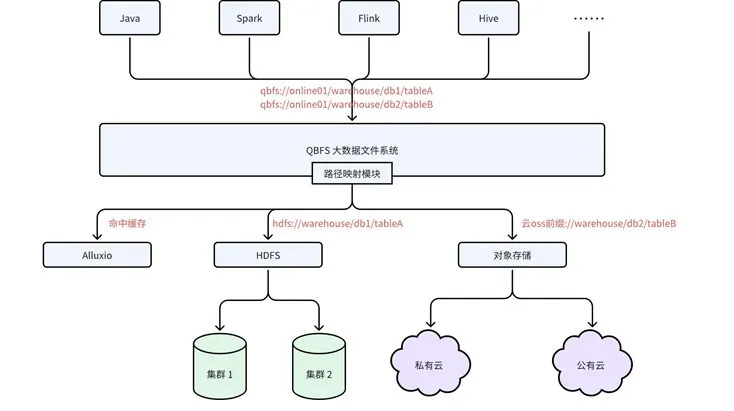
图 3 QBFS 与计算引擎、UFS、缓存的关系
计算引擎和业务客户端的读写行为通过 QBFS 客户端统一管控,因此我们能够基于 QBFS 构建 QBFS-Alluxio 缓存体系,对计算引擎透明地增强 Alluxio 的路由、降级和配置管理等能力。QBFS-Alluxio 缓存体系由以下几个关键组件构成:
QBFS 客户端/服务端:计算引擎通过 QBFS 客户端与 UFS 或 Alluxio 交互,由 QBFS 服务端的挂载配置来动态决定访问具体的存储服务或缓存服务。
热度分析服务:辅助决定哪些表应该加入缓存,充分发挥缓存价值。
缓存探活服务:定期检测 Alluxio 集群的可用性,同步给 QBFS 服务端,帮
助客户端进行异常降级。
缓存管理服务:提供缓存挂载、卸载的接口并保证这个过程中的数据一致性,主动清理过期缓存。
图 4 QBFS-Alluxio 缓存体系架构
计算引擎透明接入缓存
Alluxio 集成到 QBFS 涉及到如下组件,使得 Alluxio 可以无缝地与 QBFS 协同工作。
QBFS 客户端:封装Alluxio客户端对上层提供HCFS兼容接口,将命中缓存请求转发到Alluxio。
Alluxio-QBFS 插件:适配支持 Alluxio 以 QBFS 协议访问 UFS, 有两个好处:
确保 Alluxio 访问 UFS 的行为与 QBFS 中的挂载语义一致,例如 QBFS的
持久层路径可能会挂载到多个存储服务。
Alluxio 不需要维护所有 UFS 集群的配置文件, 全部在 QBFS 服务端统一
管理。
以下是计算引擎透明访问 Alluxio 的详细流程:
文件请求:计算引擎从 MetaStore 或其他途径获取文件请求地址,并调用 QBFS 客户端发起文件请求。
路由决策:QBFSFileSystem 作为 QBFS 客户端的请求入口,基于从 QBFS 服务端获取的持久层、缓存层路由规则、集群状态共同决定本次请求走缓存代理或持久代理。
缓存命中:如果命中缓存路由规则,缓存层代理将 qbfs 地址转换为 alluxio 地址,通过 Alluxio SDK 与 Alluxio 集群交互。
UFS 访问:Alluxio 集群收到请求后,如果需要与 UFS 交互(如缓存未命中),通过 QBFS 客户端发起请求直接通过 UFS 代理与 UFS 进行交互。
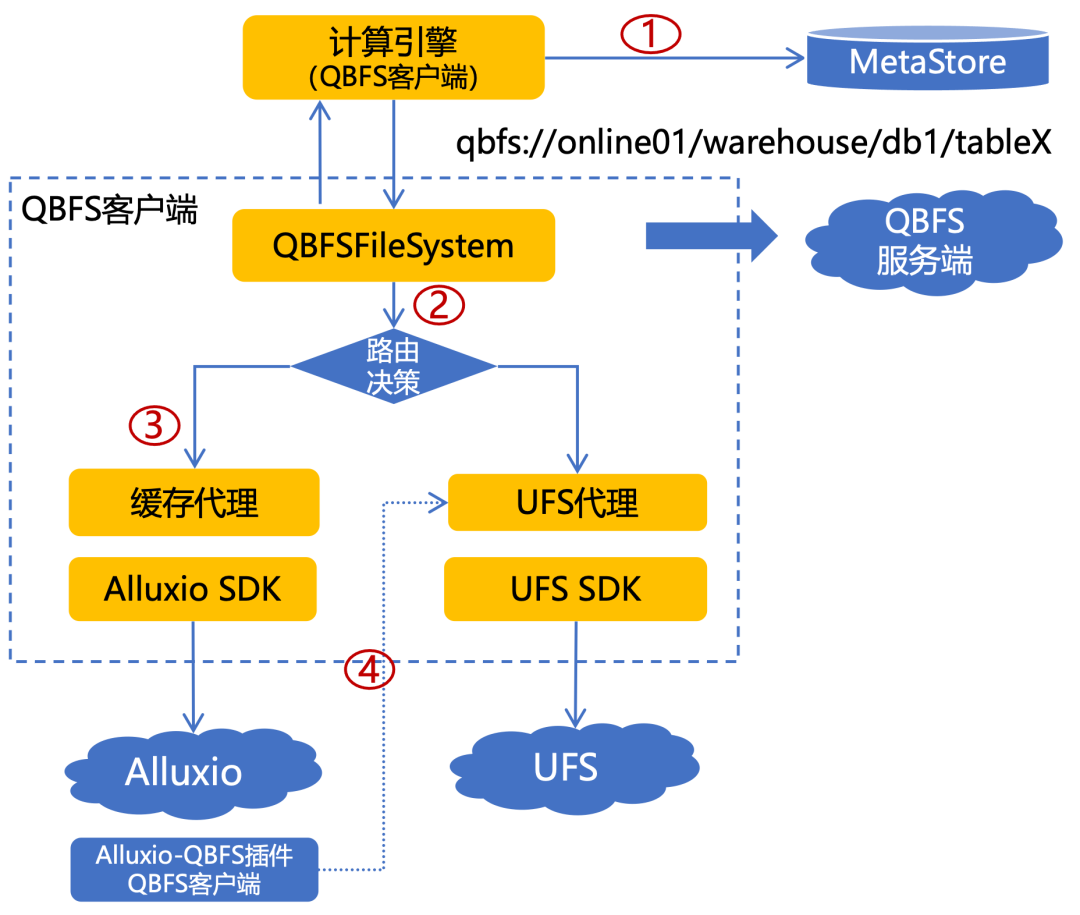
图 5 计算引擎透明访问 Alluxio 整体流程
缓存挂载与淘汰策略
由于 ETL 计算和 OLAP 查询的粒度通常是表层级(如 Hive 或 Iceberg 表),所以我们将缓存的控制粒度也设定为表级。在计算引擎能够访问 Alluxio 之后,我们的下一步是识别哪些数据适合接入缓存,以及哪些数据需要清理,以保障缓存的命中率和性能。
为了评估一个表或分区是否适合加入缓存,我们引入关键指标:文件的重复访问率。该指标反映了一个文件在指定时间窗口内重复访问的流量比例。重复访问率越高,意味着缓存这些数据能够显著提升效能。我们通过热度分析把文件级别的重复访问率聚合到表级别,来评估表的缓存价值和热度范围。
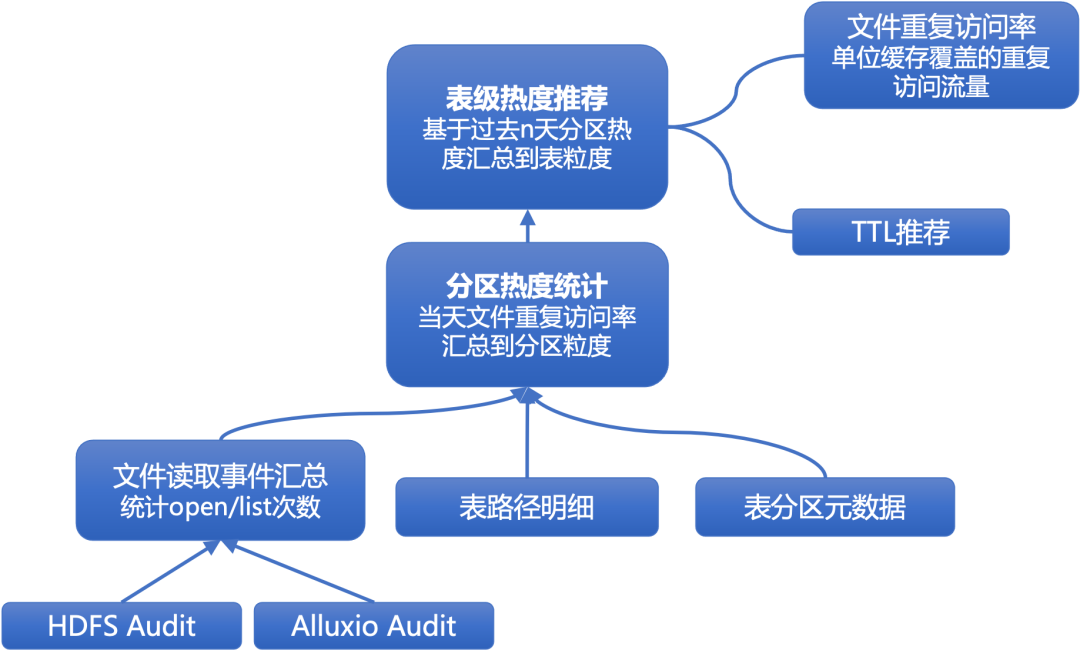
图 6 缓存热度分析模型
热度分析的流程如下:
文件读取事件汇总:从 HDFS 和 Alluxio 的审计日志中收集前一天的读取事件,并汇总每个文件的重复访问率(重复访问流量/文件大小)。由于 audit 日志中没有直接记录读流量的信息,我们通过统计 openFile 和 listStatus 操作的次数来近似代表文件的访问频率,再结合文件大小估算每个文件的读取流量。
分区热度分析:将文件级别的事件汇总信息与表元数据关联,按表分区进行统计和聚合,得到每个分区的重复访问率。
表热度分析:我们利用历史数据来提高分析的准确性。通过统计过去 N 天的分区访问数据,可以计算出每个分区在不同日期的访问密度中位数,并剔除异常值。最终,将这些分区的数据在表级别进行聚合,生成缓存推荐列表。这包括推荐的分区数量和最早分区偏移量,以便决策优化。
基于热度分析的结果,通过如下几个手段确保缓存中的数据是高频访问且及时更新的,从而提高缓存管理的效率和性能:
控制缓存的表及 TTL:将有缓存价值的表挂载到缓存中,并设置 TTL(仅允许该范围内的分区访问缓存);
主动剔除热度降低的表:同时将热度降低的表从缓存中移除。
按分区清理过去缓存:尽管 Alluxio 缓存空间满了之后会采用被动的 LRU 缓存淘汰策略,但这种策略会同步阻塞请求,影响性能。因此,我们通过缓存管理系统基于表配置的缓存 TTL,每天按分区清理过期缓存。这样可以确保缓存中的数据是高频访问且及时更新的。
表级缓存动态配置
我们将适合缓存的表挂载到缓存时,还会对每个表设置特定的 Alluxio 客户端配置以适应不同表和计算引擎的需求,这些定制化配置能够优化缓存性能。例如:
Hive 表:因为通常为天级更新,可以配置写时不缓存,仅在查询时缓存需要的数据,保障缓存命中率的同时减少不必要的缓存空间占用。
Iceberg 表:因为通常每 5 分钟进行更新,为了提高查询时的缓存命中率,配置在写入时即缓存数据。这样可以显著减少查询时 I/O 的频繁波动。
线上业务:对于查询耗时要求高的业务,通过将热数据设置为pin在缓存,避免热数据被淘汰。
通过在 QBFS 侧实现灵活的缓存路由,我们能够为不同类型的表配置最适合的缓存策略。例如,允许 Iceberg 表最近 7 天的数据和元数据以 CACHE_THROUGH(写入同时缓存数据,数据预热)的配置访问 Alluxio 集群,其他分区数据继续访问 HDFS,从而避免冷数据挤占缓存资源。
缓存降级
我们在 QBFS 客户端实现了两种降级机制以尽可能的降低 Alluxio 异常对业务造成的负面影响。
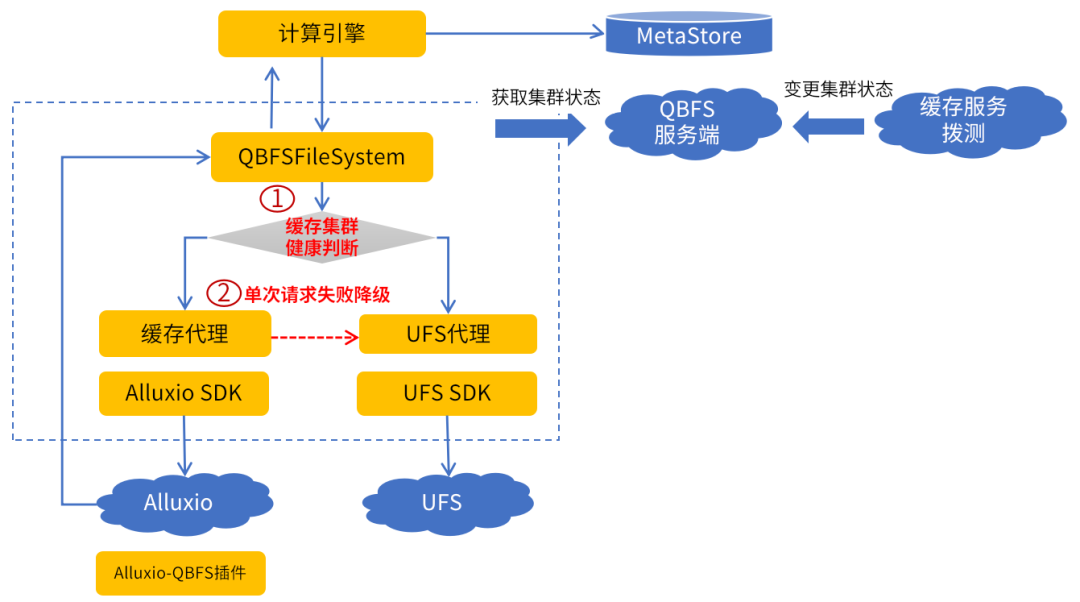
图 7 QBFS 客户端缓存降级
1.集群拨测降级
为了应对 Alluxio 集群整体不可用的情况,例如 Master 节点故障、挂起、选主失败、Worker 节点批量宕机。QBFS 客户端支持集群级别的缓存请求整体降级 UFS, 最大限度地减少无效的降级重试。
降级措施:通过缓存探活服务定期检测 Alluxio 集群状态并同步给 QBFS 服务端。当 Alluxio 集群状态异常时,QBFS 客户端分钟级感知异常, 禁用相关集群的缓存挂载并将请求直接委托给 UFS 处理。
恢复措施:Alluxio 集群恢复后,缓存管理服务按照业务优先级进行元数据同步、恢复缓存挂载,避免数据不一致。
2.单次请求降级
为了应对 Alluxio 集群整体能提供服务,但是部分请求失败的情况,例如部分 Worker 无法响应请求。这种情况我们不希望 Alluxio 集群级别降级, QBFS 客户端支持单次请求降级、做到既不全量降级也不频繁重试:
读请求在缓存层失败后降级到持久层重试,确保读操作成功。为确保数据一致性,写请求在缓存层失败时不允许降级重试,持续性写入失败则需要运维人员介入解决异常。
冷却处理策略:为防止每个请求重试导致任务或查询整体性能下降,客户端维护各 Alluxio 集群的请求失败率。当失败率超过设定阈值时,后续请求将直接降级到持久层,减少性能损耗。以概率方式放行部分请求到缓存层,以在 Alluxio 正常后恢复缓存加速能力。
2.2 Alluxio 跨AZ部署与优化
降低跨网络专线的流量,平衡网络带宽和查询性能,比较常见的解决方案是在每个 AZ 可用区内构建本地缓存服务,缓存热数据,从而减少对跨 AZ 数据访问的依赖。
但是在我们的大数据多 AZ 统一调度架构下,如果在每个 AZ 中都独立构建 Alluxio 服务,可能会产生多个 Alluxio 集群间数据不一致的情况。例如,我们的架构中计算任务会根据 YARN 的负载动态调度到不同 AZ 的 Hadoop 集群,同一张表的数据可能写入 Alluxio 集群 1 或 Alluxio 集群 2, 如果没有数据同步机制来维护元数据的一致性,彼此之间写入的数据在对方的 Alluxio 缓存中不可见。但是额外的数据同步机制会增加缓存维护的复杂性。
基于上述理由,我们选择了跨 AZ 的 Alluxio 大集群模式来构建公共缓存层,通过控制写入都走同一个 Alluxio 集群,保证只有一份元数据、从而消除了元数据不一致的可能。我们在 Hadoop 公共服务中搭建了跨 AZ 的 Alluxio 大集群,Worker 分布在多个 AZ 下、Alluxio Worker 与大数据计算节点混合部署,利用计算节点的空闲磁盘资源。
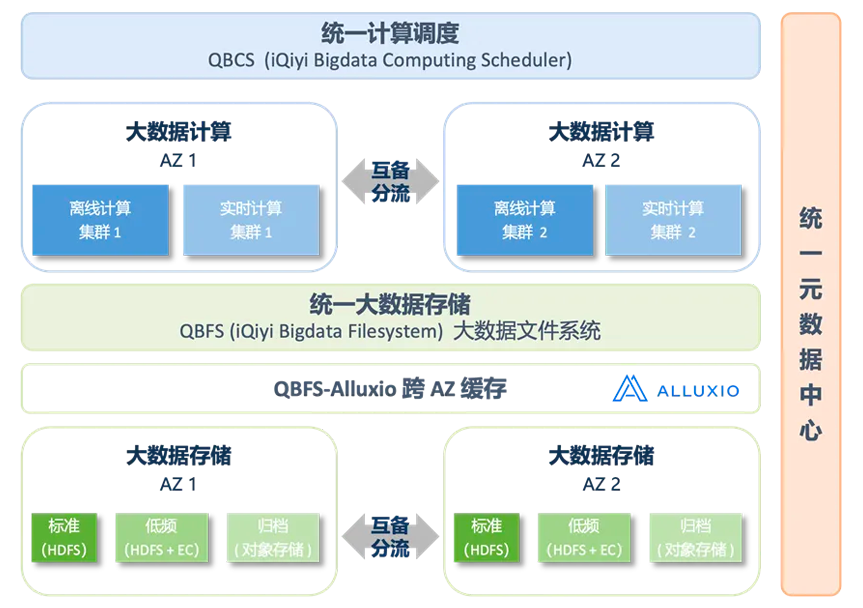 图 8 引入Alluxio后的多AZ统一调度架构
图 8 引入Alluxio后的多AZ统一调度架构
下面介绍我们在跨 AZ Alluxio 大集群部署模式下,在 Alluxio 层面做的改造优化。
StrictAzPolicy Worker 选择策略
当 Alluxio Worker 分布在不同的可用区 (AZ) 时,现有的 Worker 读选择策略(如LocalFirst、
CapacityBasedDeterministicHashPolicy、DeterministicHashPolicy 等)没有考虑 Worker 的 AZ 分布。这导致不能保证数据缓存到靠近客户端的 Worker 中。例如,当 AZ-A 内已有缓存副本时,AZ-B 的客户端会直接从 AZ-A 读取缓存,而不会将副本缓存到 AZ-B 的 Worker 中,进而导致 AZ-A 以外的客户端始终需要跨专线读取缓存。
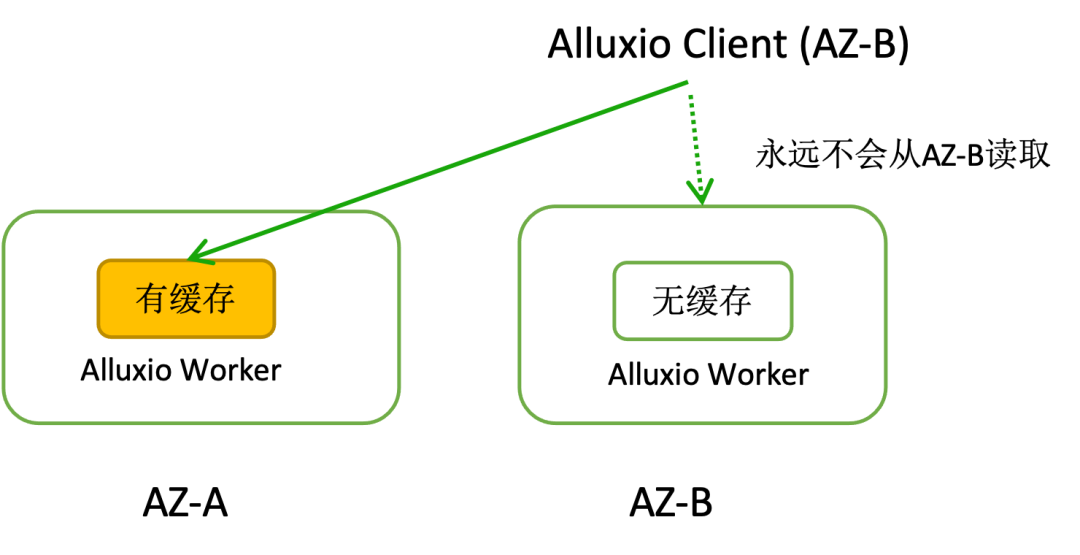
图 9 跨AZ Alluxio 集群下 BlockLocationPolicy 存在的问题
为了解决这一问题,我们扩展了BlockLocationPolicy(Worker 选择策略),实现了 StrictAzPolicy,该策略在读操作时严格考虑客户端所在的 AZ。在新的策略下能够保证数据缓存的地域性,减少跨 AZ 读取带来的延迟和成本。
StrictAzPolicy 策略思路如下:
当客户端所在 AZ 的 Worker 没有缓存数据时,从 UFS 读取数据并缓存在本 AZ 中。我们修改了参数
alluxio.user.ufs.block.read.location.policy.deterministic.hash.shards 的语义,原本该参数用于定义从 UFS 读取数据块时的位置策略,将读取位置分割为多少个副本。现在,我们将其语义调整为在每个可用区 (AZ) 内分割的副本数量,确保每个 AZ 下都缓存至少 1 副本。
客户端总是从所在 AZ 的 Worker 读取缓存,减少跨 AZ 读取带来的延迟和成本。
PageStorage 减少读放大
Alluxio 在 2.8 社区版本及之后引入了更加细粒度的 Page 级缓存存储(最小 1 MB),作为现有 Block 级(默认 64 MB)缓存存储的替代选项。与 Block 级存储相比,Page 级缓存显著减少了 Alluxio 从底层文件系统(UFS)加载数据时的读放大问题。Page 缓存不会增加 Master 的元数据负担,因为 Master 管理的元数据仍然是以 Block 为粒度。Worker 则负责将 Block 切分成 Page 进行存储和管理。
例如,在 Block 存储模式下,每个块的大小为 64 MB,当客户端仅需要读取 Parquet 或 ORC 文件的页脚(通常只有几 KB)时,Alluxio 仍需将整个 64 MB 的块加载到缓存中,这导致了较大的读放大。而采用页面级缓存,由于页面粒度较小,仅需加载一个 1 MB 的页面即可完成相同的读取操作,从而减少了不必要的数据加载,提升了效率和性能。
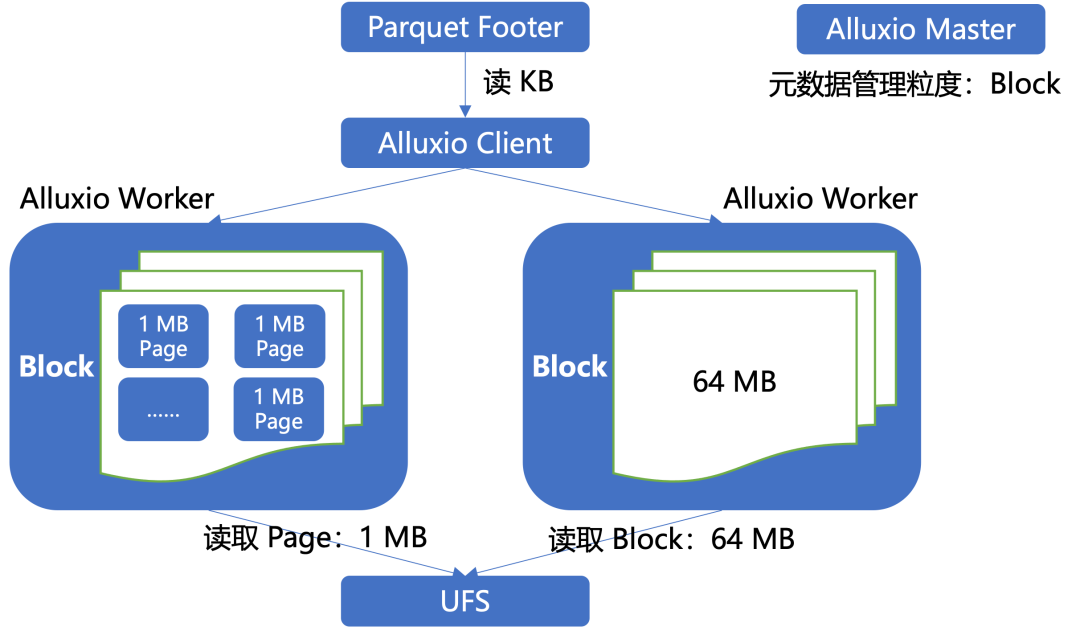
图 10 PageStorage、BlockStorage 读 UFS 区别
1.TPC-H 读流量测试
我们使用 100 GB 的 TPC-H 数据集测试了不同存储方式下的网络流量情况,TPC-H 的大多数查询涉及大量的表扫描和聚合操作,这使得其工作负载通常以顺序读为主,同时伴有少量的随机读。这种特性更符合离在线计算任务的场景。结果显示 Page 缓存粒度相比 Block 缓存粒度减少了 33% 的读放大。
我们选择使用 1 MB 的 Page 缓存粒度进行存储。
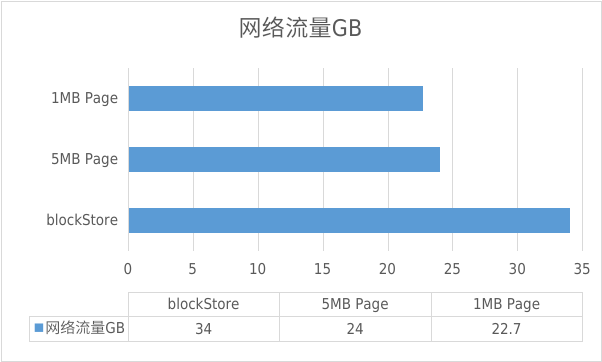
图 11 不同存储粒度在 TPC-H 测试读流量情况
2.Page性能优化
在应用页面级缓存时,我们发现 Alluxio 每次读缓存数据时都会初始化
PagedUfsBlockReader,会进行大量无意义的ByteBuffer.allocateDirect 内存分配(例如,5 MB 页面在一个 SQL 查询中会引发上千次分配)影响性能。为解决这一问题,我们对 PagedUfsBlockReader 进行了优化,只有在真正需要从 UFS 读取数据时才初始化 ByteBuffer。这一优化少了不必要的内存分配,提升了查询性能。详细的优化可以参见 GitHub Pull Request #18390。
以 5 MB Page 为例,TPC-H 测试集在优化前后,Trino 端到端的 P90、P95 及总耗时性能表现对比如下:
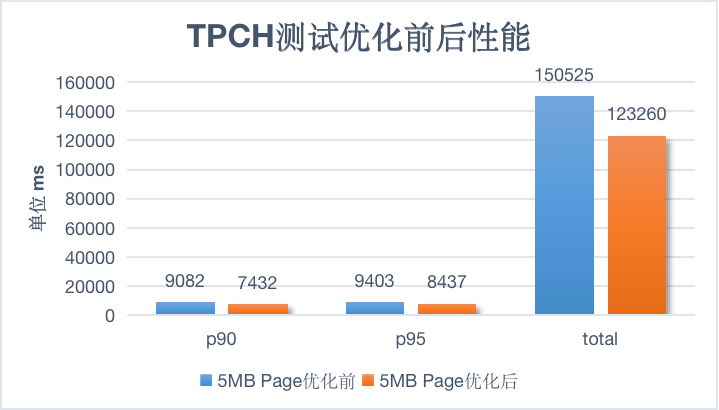
图 12 PageStorage 优化前后的 Trino TPCH 性能对比
在具体的应用验证中,例如在爱奇艺某 Hive 查询分析场景中,通过缓存 12 TB 的数据,覆盖了 140 TB 的流量,减少了 90% 的跨网络流量。
03#
Alluxio在爱奇艺数据分析场景的应用
在爱奇艺的近实时分析场景中,我们使用 Trino 和 StarRocks 服务来支持。数据源存储在公共 HDFS 集群中,其承载了大部分离在线计算任务,负载很高、查询的 I/O 波动较大。此外,由于 HDFS 使用的是机械硬盘(HDD),其性能无法满足在线业务的实时需求。为了解决这一问题,我们引入了 Alluxio 来缓存热数据。
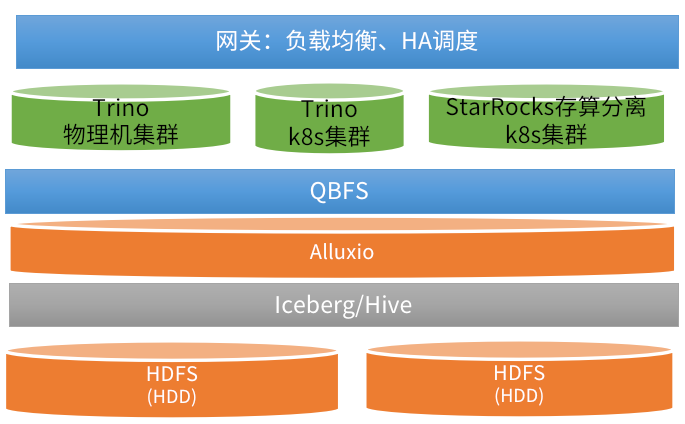
图 13 爱奇艺近实时 OLAP 分析服务架构
对于 Trino 和 StarRocks 服务,同一用户的查询会在多个集群中进行负载均衡调度。如果采用 Alluxio 的 Edge 模式(客户端缓存),虽然无需额外的运维成本,但是多集群间缓存无法共享,导致数据冗余,并且无法与 QBFS 集成以复用通用的缓存增强控制。因此,在 OLAP 缓存场景中,我们选择了 Alluxio 的集群模式,通过将 Alluxio Worker 与 Trino Worker 混合部署,充分利用 CPU 和存储资源。
我们为 Trino 移植了软亲和调度功能,以提高缓存本地读的比例。虽然我们期望能显著提升端到端查询性能,但实际结果未如预期。因此,我们对 Alluxio worker 的本地读取和远程读取性能进行了测试。
测试结果显示,读取文件的大小对性能有显著影响。对于 500 MB 的文件,读取性能相比 600 KB 的文件有两倍的提升,尽管两种情况下的读取速度都是毫秒级别,且都非常快。
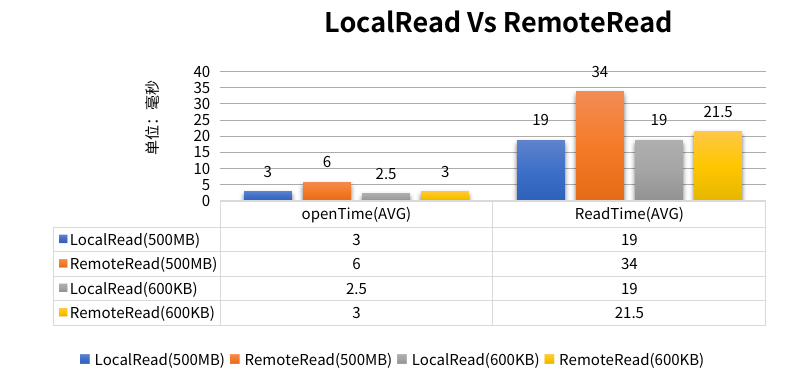
图 14 LocalRead RemoteRaed在不同文件大小下的读取耗时
在我们的测试环境中,Alluxio worker 并未在硬件资源、服务资源或网络带宽等方面遇到瓶颈。这意味着,在资源未受限的情况下,提高本地读取比例对性能的提升有限。然而,如果在更高负荷或资源受限的情况下,提高本地读取将变得非常必要,以避免潜在的瓶颈并提升整体查询性能。
目前在 OLAP 场景下,我们将线上业务的表主动接入 Alluxio 以获得更快、更稳定的 I/O, 其余表主要是根据热度分析结果,将缓存价值更高的表透明接入 Alluxio。广告数据查询、日志分析、CDN网络监控等多个业务都接入了 Alluxio 缓存,IO密集型的查询性能提速 20 倍,平均性能提升 3 倍。
3.1 广告数据查询缓存加速
在广告的流批一体场景中,原来的实时数据通过 Kafka 写到 Kudu,离线数据同步到 Hive,通过 Impala 来统一查询,基于离线覆盖的进度将查询分发到 Kudu 和 Hive。
使用 Iceberg 以后,实时和离线数据都更新 Iceberg,数据写入公共HDFS实现了存储的统一, 任务开发统一为 SQL开发,广告智能出价全链路提速近 5 倍。其中 Trino 查询部分,因为业务数据存储在公共 HDFS 集群,查询 I/O 耗时波动大。在接入 Alluxio 后业务查询 P99 降低 50%。
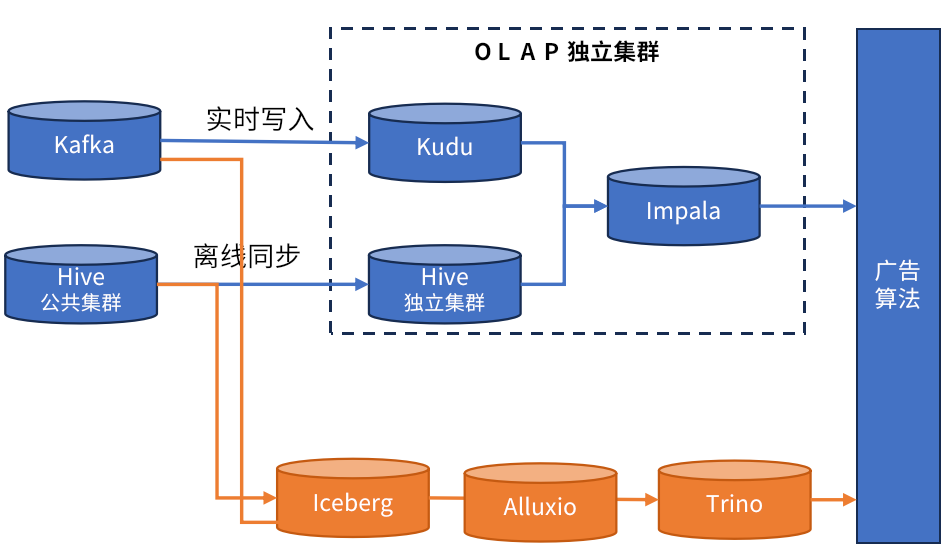
图 15 广告 Iceberg 流批一体,通过 Alluxio 加速查询
3.2 日志分析缓存加速
在日志分析场景中,我们将日志从 ES 迁移到 Iceberg 数据湖中,通过 Trino 来查询,大幅节省存储计算成本。但大多数用户都感知到日志查询速度下降(P99 响应时间从 5 秒增加到超过 30 秒)。经过分析 SQL 执行过程,我们发现大部分耗时都在 HDFS 的文件读取上, 因此我们引入 Alluxio 来降低 IO 耗时:
动态缓存管理:根据每张表的访问记录,对访问频繁表的开启缓存,长期未访问的表则关闭缓存。
性能提升:开启 Alluxio 后,SQL 执行时长显著下降,查询稳定性大幅提升,P99 响应时间稳定在 10 秒内。
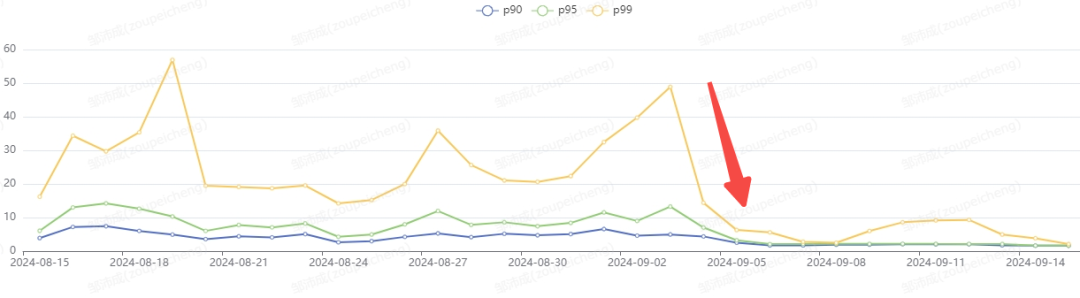
图 16 引入 Alluxio 前后性能变化
04#
未来计划
在缓存热度分析方面,有两个优化方向:第一,优化读取流量的统计方式,从 QBFS 客户端收集更加准确的读取流量数据,而不是通过 list/open 操作近似估算流量;第二,在 Alluxio 中增加 caller context,以确保计算任务信息在整个存储层的流转中不会丢失,从而更便于排障。
在使用场景方面,我们也在不断探索,包括未来在公有云的缓存加速,以及在 AI 大模型场景中的应用。

也许你还想看


















 1021
1021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









