







当前AI技术已经全面在爱奇艺搜索引擎中落地应用。与传统搜索仅能查找片名不同,爱奇艺的AI搜索功能让用户能够在搜索阶段使用更多模糊信息获得想找的影片。首次将生成式AI技术应用于角色搜索、剧情搜索、明星搜索、奖项搜索和语义搜索五大场景。通过对模糊搜索query的精准理解提供了多样化的内容推荐,使用户能够通过几个简单的关键词,快速找到与影视剧密切相关的热门角色、经典剧情场景和明星阵容等内容,标志着找片和搜片进入了AI时代,而这些相关创新实践在用户体验和内容分发效果上都获得了积极反馈。
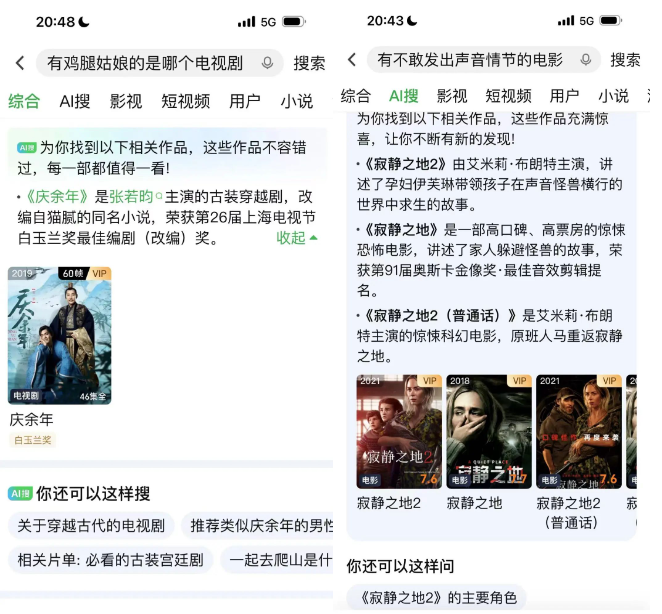
上述两张图展示了AI搜索在爱奇艺搜索中的产品样式。它们分为三个主要部分:顶部的“TIPS”,这部分以“为你找到以下作品”开头,通过简短精炼的一句话来介绍影片的信息。中部的影视卡片是为用户找到的影片内容,用户可以通过点击这些卡片直接观看影片。底部的“你还可以这样搜/问”是query引导词,用于引导用户进一步进行搜索和提问。接下来,我们将分别介绍这三部分的相关技术点。
01#
基于COT技术的TIPS生成
TIPS信息是用户第一眼看到的信息,TIPS的信息可以快速了解影片的信息,通过这些信息用户能迅速掌握影片详情,对于用户的观影决策起着至关重要的辅助作用。
由于影片信息繁多,包括演职员信息和剧情信息,它们合并起来可能会超过上千字。如何用简洁的语言为每部作品生成一条有吸引力的TIPS,是一项非常具有挑战性的工作。经过多次实验,我们最终确定使用COT技术生成TIPS。
Chain-of-Thought(CoT)[1]是一种改进的Prompt技术,旨在提升大规模语言模型在复杂推理任务上的表现,特别是针对复杂的数学问题,例如算术推理、常识推理和符号推理。CoT技术通过要求模型在输出最终答案之前,将一个复杂问题逐步分解为多个子问题,依次进行求解,从而提升模型的推理能力。一个简单的CoT实例如下图所示:
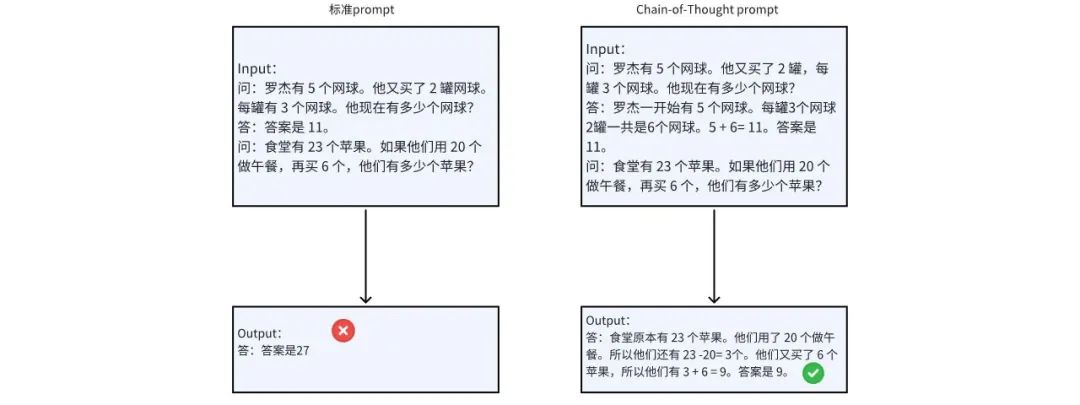
图1 COT简介
类似的,我们将TIPS生成任务拆解为两个步骤。第一步,从众多信息中提取影片的亮点,从而过滤掉原内容中大量无用信息,保留核心信息。第二步,将亮点信息最终组织成一条有吸引力的TIPS内容。
以《手机》这部作品为例,第一步,从原始内容抽取出亮点信息:
著名从业者:导演冯小刚,主演张国立、葛优
改编信息:改编自刘震云同名小说《手机》
吸引点:冯式幽默, 讽刺现实, 婚姻危机, 三角恋
剧情简介:本片讲述了主持人严守一因手机导致婚姻危机的故事
然后,根据以上信息模型再进行总结,生成这部作品的推荐语:
《手机》由冯小刚执导,葛优、张国立主演,改编自刘震云同名小说,是现实题材与冯式幽默的完美结合。
具体的执行过程可参考下图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1029
1029

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









