






优化器的比较
几种常见优化器
SGD(Stochastic Gradient Descent)
SGD基本上已经被弃用了,因为其效果和其他优化器相比实在差太多了,不仅速度比较慢,而且还容易停止训练。今天用mmdetection训练retinanet的时候,一直导致loss梯度爆炸,困惑了好几天,config查了查发现优化器使用的是SGD。。。人都是傻得。然后看了前辈的config,发现用的是Adam,今天已经在跑了,效果很好。
言归正传,SGD的确在GD上开创了一个先河。SGD 每次更新时对每个样本进行梯度更新,对于很大的数据集来说,可能会有相似的样本,这样 BGD 在计算梯度时会出现冗余,而 SGD 一次只进行一次更新,就没有冗余,而且比较快,并且可以新增样本。
x
t
+
1
=
x
t
+
η
t
g
t
x_{t+1} = x_t + \eta_t g_t
xt+1=xt+ηtgt
θ
=
θ
−
η
⋅
∇
θ
J
(
θ
;
x
(
i
)
;
y
(
i
)
)
\theta = \theta -\eta \cdot \nabla_{\theta}J(\theta; x^{(i)};y^{(i)})
θ=θ−η⋅∇θJ(θ;x(i);y(i))
这里的
g
t
g_t
gt就是所谓的随机梯度,也就是说,虽然包含一定的随机性,但是从期望上来看,它是等于正确的导数的。用一张图来表示,其实 SGD 就像是喝醉了酒的 GD,它依稀认得路,最后也能自己走回家,但是走得歪歪扭扭。(红色的是 GD 的路线,偏粉红的是 SGD 的路线)。

- 缺点:
因为SGD像一个喝醉的人,需要迷迷糊糊走很多步才能收敛,没有明确的目标进行快速梯度下降。 - 优点:
实践中,人们发现,除了算得快,SGD 有非常多的优良性质。它能够自动逃离鞍点,自动逃离比较差的局部最优点,而且,最后找到的答案还具有很强的一般性(generalization),即能够在自己之前没有见过但是服从同样分布的数据集上表现非常好!
实际上,有大量的机器学习的问题使用的函数都满足这样的性质。比如 Orthogonal tensor decomposition,dictionary learning, matrix completion 等等。而且,其实并不用担心最后得到的点只是一个局部最优,而不是全局最优。因为实际上人们发现大量的机器学习问题,几乎所有的局部最优是几乎一样好的,也就是说,只要找到一个局部最优点,其实就已经找到了全局最优,比如 Orthogonal tensor decomposition 就满足这样的性质,还有小马哥 NIPS16 的 best student paper 证明了 matrix completion 也满足这样的性质。我觉得神经网络从某些角度来看,也是(几乎)满足的,只是不知道怎么证。
Mini-batch Gradient Descent
批梯度下降是介于两者之间的方法,可以用如下公式进行描述:
θ = θ − η ⋅ ∇ θ J ( θ ; x i : i + n ; y i : i + n ) \theta = \theta - \eta · \nabla_\theta J(\theta;x^{i:i+n};y^{i:i+n}) θ=θ−η⋅∇θJ(θ;xi:i+n;yi:i+n)
它在一定程度上避免了前两者的弊端,是当前深度学习领域最常用的方法,常用SGD称呼。
改进版优化器
- 如何选择合适的学习率。学习率过小导致过慢收敛速度,过大则会影响收敛性能;
- 如何调整学习率。
- 不同参数学习率自适应问题。
- 如何跳出局部最优。
momentum动量
第一张是不带动量的,第二张是带了动量的。可以看出,梯度下降的快一点,可以加速SGD收敛。


Adagrad
它是一种自适应学习率的方法,对于低频率参数执行高学习率,对于高频参数执行地学习率。该特性使得它比较适合于处理稀疏数据。它公式描述如下:
g
t
,
i
=
∇
θ
t
J
(
θ
t
,
i
)
θ
t
+
1
,
i
=
θ
t
,
i
−
η
⋅
g
t
,
i
θ
t
+
1
,
i
=
θ
t
,
i
−
η
G
t
,
i
i
+
ϵ
⋅
g
t
,
i
g_{t,i} = \nabla_{\theta_t} J(\theta_{t,i}) \\ \theta_{t+1,i} = \theta_{t,i} - \eta · g_{t,i}\\ \theta_{t+1,i} = \theta_{t,i} - \frac{\eta}{\sqrt {G_{t,ii} + \epsilon}} · g_{t,i}
gt,i=∇θtJ(θt,i)θt+1,i=θt,i−η⋅gt,iθt+1,i=θt,i−Gt,ii+ϵη⋅gt,i
Adadelta
这个算法是对 Adagrad 的改进,
和 Adagrad 相比,就是分母的 G 换成了过去的梯度平方的衰减平均值,指数衰减平均值

RMSprop
RMSprop 是 Geoff Hinton 提出的一种自适应学习率方法。
RMSprop 和 Adadelta 都是为了解决 Adagrad 学习率急剧下降问题的。
梯度更新规则:
RMSprop 与 Adadelta 的第一种形式相同:(使用的是指数加权平均,旨在消除梯度下降中的摆动,与Momentum的效果一样,某一维度的导数比较大,则指数加权平均就大,某一维度的导数比较小,则其指数加权平均就小,这样就保证了各维度导数都在一个量级,进而减少了摆动。允许使用一个更大的学习率η)

超参数设定值:
Hinton 建议设定 γ 为 0.9, 学习率 η 为 0.001。
Adam:Adaptive Moment Estimation
这个算法是另一种计算每个参数的自适应学习率的方法。相当于 RMSprop + Momentum
除了像 Adadelta 和 RMSprop 一样存储了过去梯度的平方 vt 的指数衰减平均值 ,也像 momentum 一样保持了过去梯度 mt 的指数衰减平均值(公式一和和二)
如果 mt 和 vt 被初始化为 0 向量,那它们就会向 0 偏置,所以做了偏差校正,通过计算偏差校正后的 mt 和 vt 来抵消这些偏差(公式三和四)
然后梯度更新(公式五)
公式描述如下:

Adam优化器的表现可圈可点。实践表明,Adam 比其他适应性学习方法效果要好。
实验表明
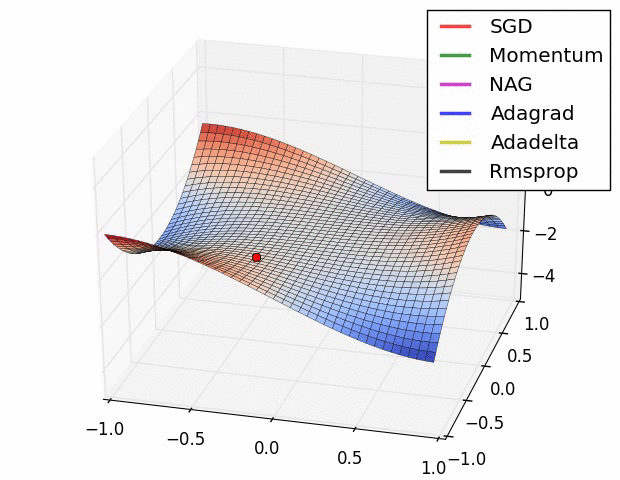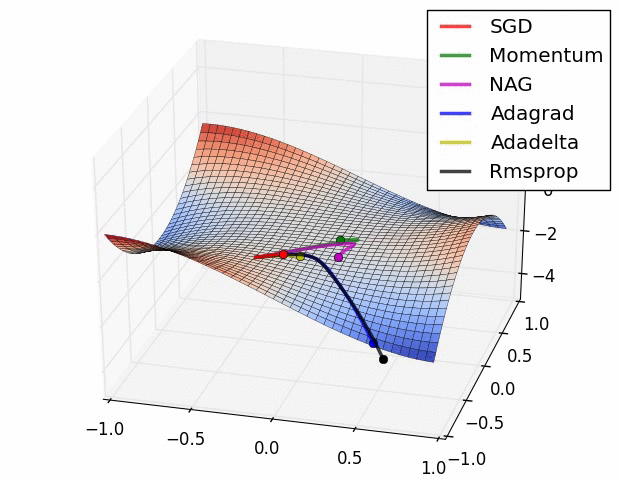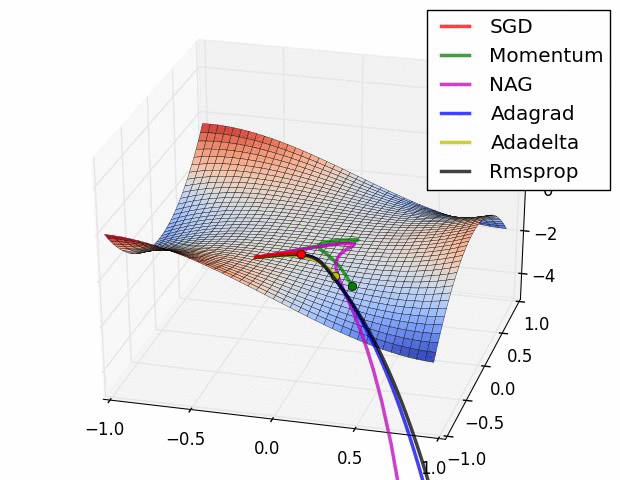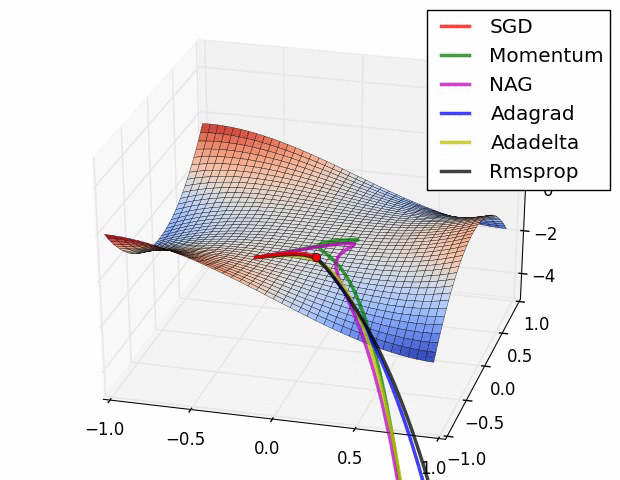

上面两种情况都可以看出,Adagrad, Adadelta, RMSprop 几乎很快就找到了正确的方向并前进,收敛速度也相当快,而其它方法要么很慢,要么走了很多弯路才找到。
由图可知自适应学习率方法即 Adagrad, Adadelta, RMSprop, Adam 在这种情景下会更合适而且收敛性更好。
如何选择优化算法
如果数据是稀疏的,就用自适用方法,即 Adagrad, Adadelta, RMSprop, Adam。
RMSprop, Adadelta, Adam 在很多情况下的效果是相似的。
Adam 就是在 RMSprop 的基础上加了 bias-correction 和 momentum。随着梯度变的稀疏,Adam 比 RMSprop 效果会好。
整体来讲,Adam 是最好的选择。
很多论文里都会用 SGD,没有 momentum 等。SGD 虽然能达到极小值,但是比其它算法用的时间长,而且可能会被困在鞍点。
如果需要更快的收敛,或者是训练更深更复杂的神经网络,需要用一种自适应的算法。


















 976
976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











