







深度学习模型组件之优化器–自适应学习率优化方法(Adadelta、Adam、AdamW)
文章目录
在深度学习中,优化器是训练过程中不可或缺的一部分。不同的优化器通过调整学习率和更新规则来帮助模型收敛得更快、更好。本文将详细介绍三种常用的优化器: Adadelta、 Adam 和 AdamW,并展示它们的核心公式、工作原理、优缺点以及应用场景。
1. Adadelta
1.1 公式
Adadelta 的核心公式如下:
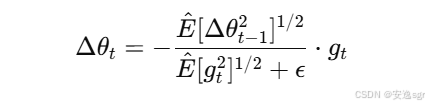
其中:
Δθt是参数更新;gt是当前时间步的梯度;E^[Δθt−12]是之前梯度的累积平方;E^[gt2]是当前梯度的平方的累积;ϵ是一个小常数,用于避免除零错误。
1.2 优点
- 自适应学习率:
Adadelta不需要预定义学习率,通过梯度的变化动态调整学习率。 - 避免学习率衰减: 与其他优化器不同,
Adadelta没有显式的学习率衰减机制,这使得优化过程更加稳定。
1.3 缺点
- 参数更新较慢: 在一些任务中,
Adadelta的更新速度可能较慢,尤其是在复杂的深度神经网络中。 - 内存消耗较大:
Adadelta存储了梯度的平方和参数的更新历史,因此需要更多的内存资源。
1.4 应用场景
- 动态调整学习率: 适用于那些无法手动调整学习率的任务,特别是对于一些不容易设定初始学习率的情况。
- 不需要手动调整学习率: 对于一些快速原型设计的任务,
Adadelta是一个不错的选择。
1.5 代码示例
import torch
import torch.optim as optim
# 假设我们有一个模型和数据
model = torch.nn.Linear(10, 1)
optimizer = optim.Adadelta(model.parameters(), lr=1.0)
# 假设损失函数
criterion = torch.nn.MSELoss()
# 假设输入和目标
input = torch.randn(32, 10)
target = torch.randn(32, 1)
# 训练过程
optimizer.zero_grad()
output = model(input)
loss = criterion(output, target)
loss.backward()
optimizer.step()
2. Adam (Adaptive Moment Estimation)
2.1 公式
Adam 优化器的核心公式如下:
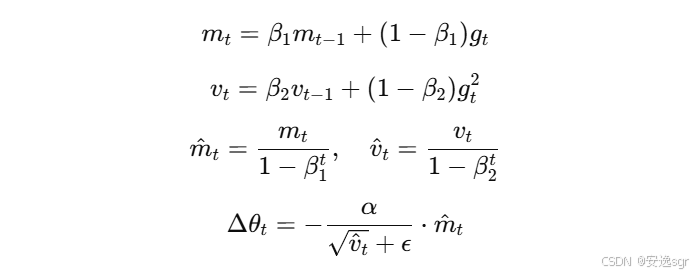
其中:
mt是梯度的一阶矩(均值);vt是梯度的二阶矩(方差);m^t是对mt和vt进行偏差修正后的估计;gt是当前时间步的梯度;β1和β2是一阶矩和二阶矩的衰减率;ϵ是一个小常数,用于避免除零错误;α是学习率。
2.2 优点
- 动态调整学习率:
Adam通过一阶矩和二阶矩的自适应调整,使得每个参数的学习率是动态的。 - 适应稀疏梯度: 对于一些稀疏梯度问题,
Adam展现出较好的性能。 - 偏差修正: 通过修正一阶和二阶矩的偏差,
Adam在初期训练阶段表现更加稳定。
2.3 缺点
- 过拟合: 在一些正则化要求较强的模型中,
Adam可能导致过拟合,特别是对于大型模型。 - 内存消耗:
Adam需要存储一阶和二阶矩的估计,因此需要更多的内存资源。
2.4 应用场景
- 大多数深度学习任务:
Adam适用于各种深度学习任务,尤其是在处理大规模数据集和深层神经网络时表现优异。 - 稀疏数据和参数: 在处理稀疏梯度或稀疏参数的任务时,
Adam是非常合适的选择。
2.5 代码示例:
import torch
import torch.optim as optim
# 假设我们有一个模型和数据
model = torch.nn.Linear(10, 1)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 假设损失函数
criterion = torch.nn.MSELoss()
# 假设输入和目标
input = torch.randn(32, 10)
target = torch.randn(32, 1)
# 训练过程
optimizer.zero_grad()
output = model(input)
loss = criterion(output, target)
loss.backward()
optimizer.step()
3. AdamW
3.1 公式
AdamW 的核心公式与 Adam 非常相似,不同之处在于它将权重衰减与梯度更新过程分开。AdamW 的参数更新公式如下:
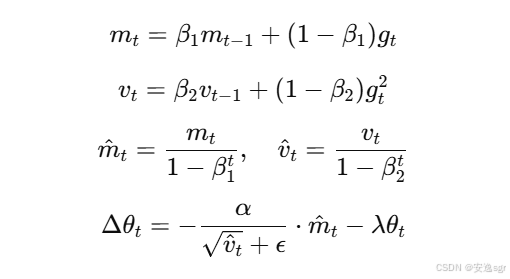
其中:
λ是权重衰减系数;- 其他符号与
Adam中相同。
3.2 优点
- 更好的正则化: 通过将权重衰减项从梯度更新中分离出来,
AdamW在正则化方面比 Adam 更加有效。 - 更高的泛化能力: 由于权重衰减对模型权重的约束,
AdamW能有效减少过拟合,尤其适用于大规模模型。
3.3 缺点
- 超参数调整: 相比于
Adam,AdamW需要额外调整权重衰减系数,可能增加调参的复杂度。 - 计算成本: 虽然与 Adam 相似,但添加了权重衰减项,可能在计算和内存上稍有增加。
3.4 应用场景
- 大型模型训练:
AdamW在需要正则化的大型模型(如Transformer、BERT)中有显著优势。 - 需要强正则化的任务: 对于需要避免过拟合的任务,特别是在复杂模型中,
AdamW是更好的选择。
3.5 代码示例:
import torch
import torch.optim as optim
# 假设我们有一个模型和数据
model = torch.nn.Linear(10, 1)
optimizer = optim.AdamW(model.parameters(), lr=0.001, weight_decay=0.01)
# 假设损失函数
criterion = torch.nn.MSELoss()
# 假设输入和目标
input = torch.randn(32, 10)
target = torch.randn(32, 1)
# 训练过程
optimizer.zero_grad()
output = model(input)
loss = criterion(output, target)
loss.backward()
optimizer.step()
4.总结
| 优化器 | 核心思想 | 公式 | 优缺点 | 适用场景 |
|---|---|---|---|---|
| Adadelta | 基于 RMSprop 的改进版本,自适应调整学习率 | 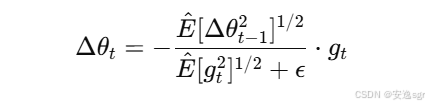 | 优点:动态调整学习率,不需要手动设置;缺点:更新较慢,内存消耗大 | 需要动态调整学习率的任务,快速原型设计 |
| Adam | 结合动量和 RMSprop 的优点,通过一阶和二阶矩自适应调整 | 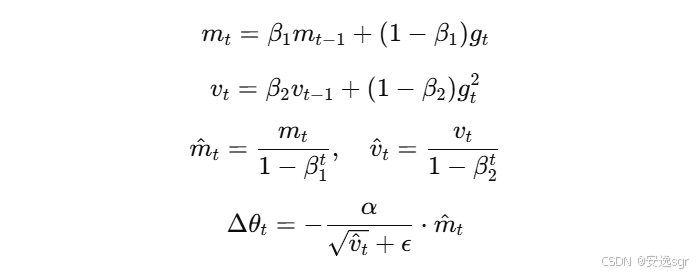 | 优点:动态调整学习率,适应稀疏梯度,偏差修正;缺点:可能导致过拟合,内存消耗大 | 大多数深度学习任务,稀疏数据处理 |
| AdamW | 在 Adam 基础上添加权重衰减,适合大模型正则化 | 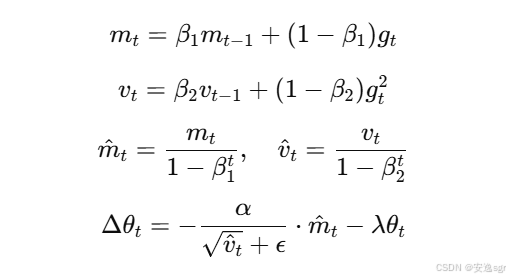 | 优点:更好的正则化,减少过拟合;缺点:需要额外调整权重衰减系数 | 大型模型训练,需要正则化的任务 |


















 350
350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









