







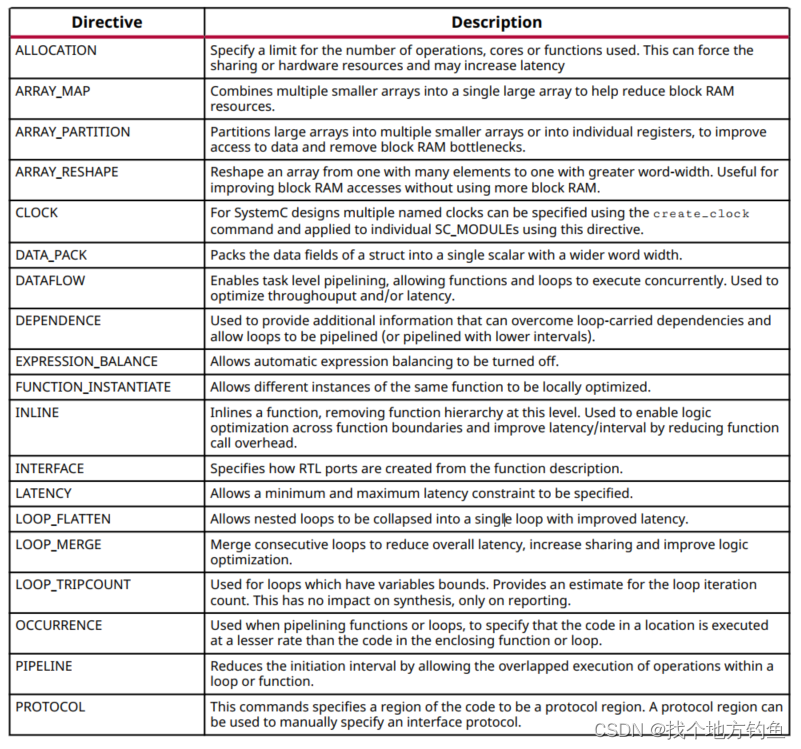
一、optimization directives合集
以下表格中为Vivado HLS 的各种优化指令(directive),相关技术用于满足生成的RTL所需性能、面积目标等。(表格来自Vivado HLS的ug902用户手册。)
二、单个directive简单介绍
1、ALLOCATION
举例1
ALLOCATION directive允许限制在设计中使用的操作符、内核或函数的数量。 例如,如果一个名为foo的函数设计有317个乘法,但FPGA只有256个乘法器资源(dsp48)。 下面显示的分配指令指示Vivado HLS创建一个最多256个乘法(mul)操作符的设计:
dout_t array_arith (dio_t d[317]) {
static int acc;
int i;
#pragma HLS ALLOCATION instances=mul limit=256 operation
for (i=0;i<317;i++) {
#pragma HLS UNROLL
acc += acc * d[i];
}
rerun acc;
}举例2
虽然有INLINE指令,但是由于foo_top函数中ALLOCATION那条指令对于函数个数的限制,最终其实相当于只INLINE了一个函数。所以有ALLOCATION的foo_top函数的面积是没有ALLOCATION的时候的三分之一。
foo_sub (p, q) {
#pragma HLS INLINE
int q1 = q + 10;
foo(p1,q); // foo_3
...
}
void foo_top { a, b, c, d} {
#pragma HLS ALLOCATION instances=foo limit=1 function
...
foo(a,b); //foo_1
foo(a,c); //foo_2
foo_sub(a,d);
...
}本质上,ALLOCATION指令在Latency 和Area之间做折衷。因为Area受到了限制,自然Latency 就会可能增长。
2.ARRAY_MAP
将多个较小的数组组合成一个大型阵列,以帮助减少块 RAM 资源。
通常使用 pragma HLS array_map 命令(具有相同的实例=目标)将多个较小的数组组合成一个较大的数组。 然后可以将这个更大的数组定位到单个更大的内存(RAM 或 FIFO)资源。
当设备支持时,每个数组都映射到块 RAM 或 UltraRAM。 FPGA 中提供的基本块 RAM 单元是 18K。如果许多小数组没有使用完整的 18K,更好地利用 Block RAM 资源是将许多小数组映射到一个更大的数组中。(如果块 RAM 大于 18K,它们会自动映射到多个 18K 单元。)
ARRAY_MAP 编译指示支持两种将小数组映射到大数组的方法:
水平映射(Horizontal):这对应于通过连接原始数组来创建一个新数组。 在物理上,这被实现为具有更多元素的单个数组。

在HLS中可以通过ARRAY_MAP中设置Horizontal,则合并后的数组长度为M+N:
![]()
Arrays array1 and array2 can be combined into a single array, specified as array3 in the
following example:
void foo (...) {
int8 array1[M];
int12 array2[N];
#pragma HLS ARRAY_MAP variable=array1 instance=array3 horizontal
#pragma HLS ARRAY_MAP variable=array2 instance=array3 horizontal
...
loop_1: for(i=0;i<M;i++) {
array1[i] = ...;
array2[i] = ...;
...
}
...
}In this example, the ARRAY_MAP directive transforms the arrays as shown in the following
figure.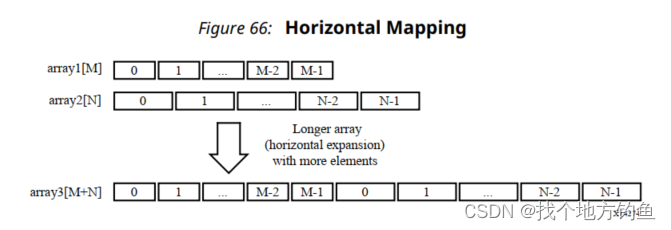
垂直映射(Vertical) :这对应于通过连接数组中的原始字段来创建一个新数组。 在物理上,这被实现为具有更大位宽的单个数组。

相应位置的元素做位拼接,最终数组的长度是最长的数组长度,宽度会发生变化。
3.ARRAY_PARTITION
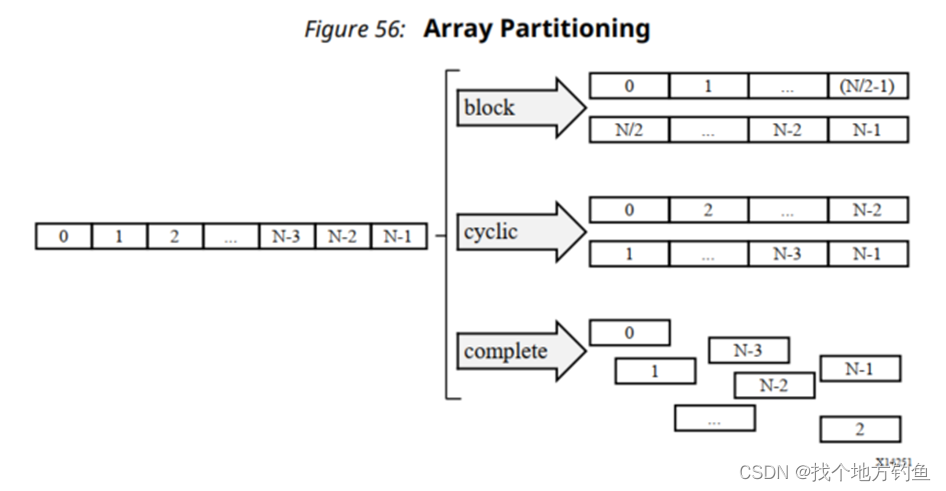
Arrays are partitioned using the ARRAY_PARTITION directive. Vivado HLS provides three types of array partitioning, as shown in the following figure. The three styles of partitioning are:
• block: The original array is split into equally sized blocks of consecutive elements of the
original array.原始数组被分割成大小相等的原始数组连续元素块。
• cyclic: The original array is split into equally sized blocks interleaving the elements of the
original array.原始数组被分割成大小相等的块,这些块之间再做交织。
• complete: The default operation is to split the array into its individual elements. This
corresponds to resolving a memory into registers.默认操作是将数组拆分为单个元素。 这对应于将内存解析为寄存器,数组分为单独的元素进行操作。
4. ARRAY_RESHAPE
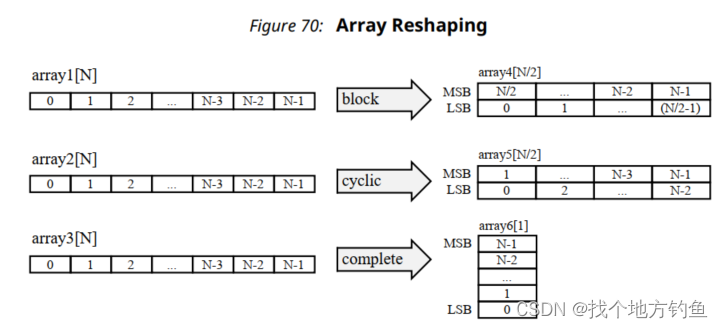
The ARRAY_RESHAPE directive combines ARRAY_PARTITIONING with the vertical mode of ARRAY_MAP and is used to reduce the number of block RAM while still allowing the beneficial
attributes of partitioning: parallel access to the data.
ARRAY_RESHAPE 指令将ARRAY_PARTITIONING与ARRAY_MAP的垂直模式结合起来,用于减少块RAM的数量,同时仍然允许分区的有益属性:并行访问数据。
直接组合ARRAY_PARTITION和纵向的ARRAY_MAP结合在一起, 这样可以在一定程度上减少资源而且可以获得一定的吞吐率ARRAY_PARTITION就是为了提高并行性,同时读取数据。
void foo (...) {
int array1[N];
int array2[N];
int array3[N];
#pragma HLS ARRAY_RESHAPE variable=array1 block factor=2 dim=1
#pragma HLS ARRAY_RESHAPE variable=array2 cycle factor=2 dim=1
#pragma HLS ARRAY_RESHAPE variable=array3 complete dim=1
...
}
5.CLOCK
对于SystemC设计,可以使用create_clock命令指定多个命名时钟,并使用此指令将其应用于单个SC_MODULEs。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
参考文献
HLS-指令使用指南_hls resource_Vuko-wxh的博客-CSDN博客
HLS Lesson17-数组优化:数组映射和重组_mob604756f37073的技术博客_51CTO博客
ug902手册















 3652
3652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









