







MMpreTrain算法库介绍
MMPretrain 是一个全新升级的预训练开源算法框架,旨在提供各种强大的预训练主干网络并支持了不同的预训练策略。

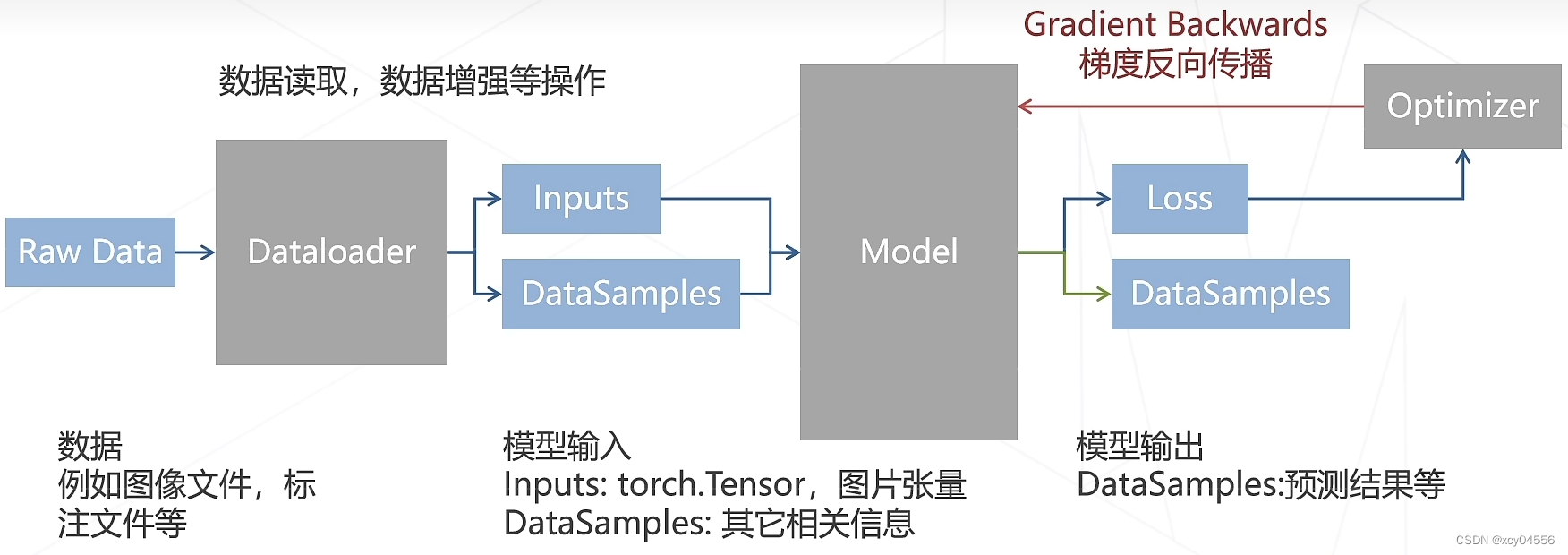
配置文件
- 模型结构:构模型有几层、每层多少通道数等
- 数据:数据集划分、数据文件路径、批大小、数据增强策略等
- 训练优化:梯度下降算法、学习率参数、训练总轮次、学习率变化策略等
- 运行时:GPU、分布式环境配置等
- 辅助功能:如打印日志、定时保存 checkpoint 等
代码框架

数据流
经典主干网络
早期深度神经网络
- AlexNet(2012)
- VGG(2014)
- GoogLeNet(2014)
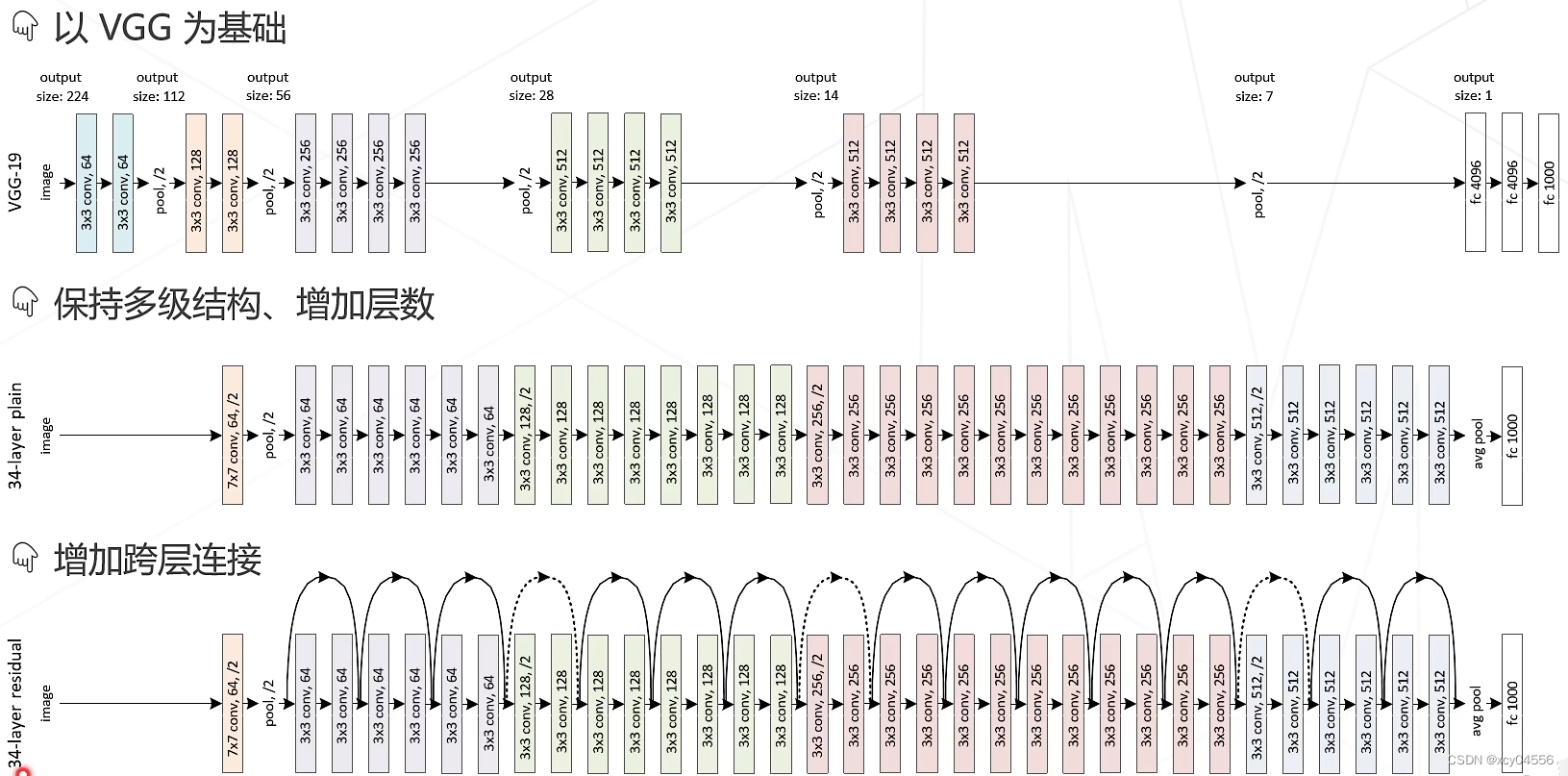
问题:精度退化问题——模型层数增加到一定程度后,分类正确率不增反降。
分析:卷积退化为恒等映射时,深层网络与浅层网络相同所以,深层网络应具备不差于浅层网络的分类精度。
猜想:虽然深层网络有潜力达到更高的精度,但常规的优化算法难以找到这个更优的模型即,让新增加的卷积层拟合一个近似恒等映射,恰好可以让浅层网络变好一点。
残差建模:让新增加的层拟合浅层网络与深层网络之间的差异,更容易学习梯度可以直接回传到浅层网络监督浅层网络的学习没有引入额外参入,让参数更有效贡献到最终的模型中。
残差网络 Resnet(2015)
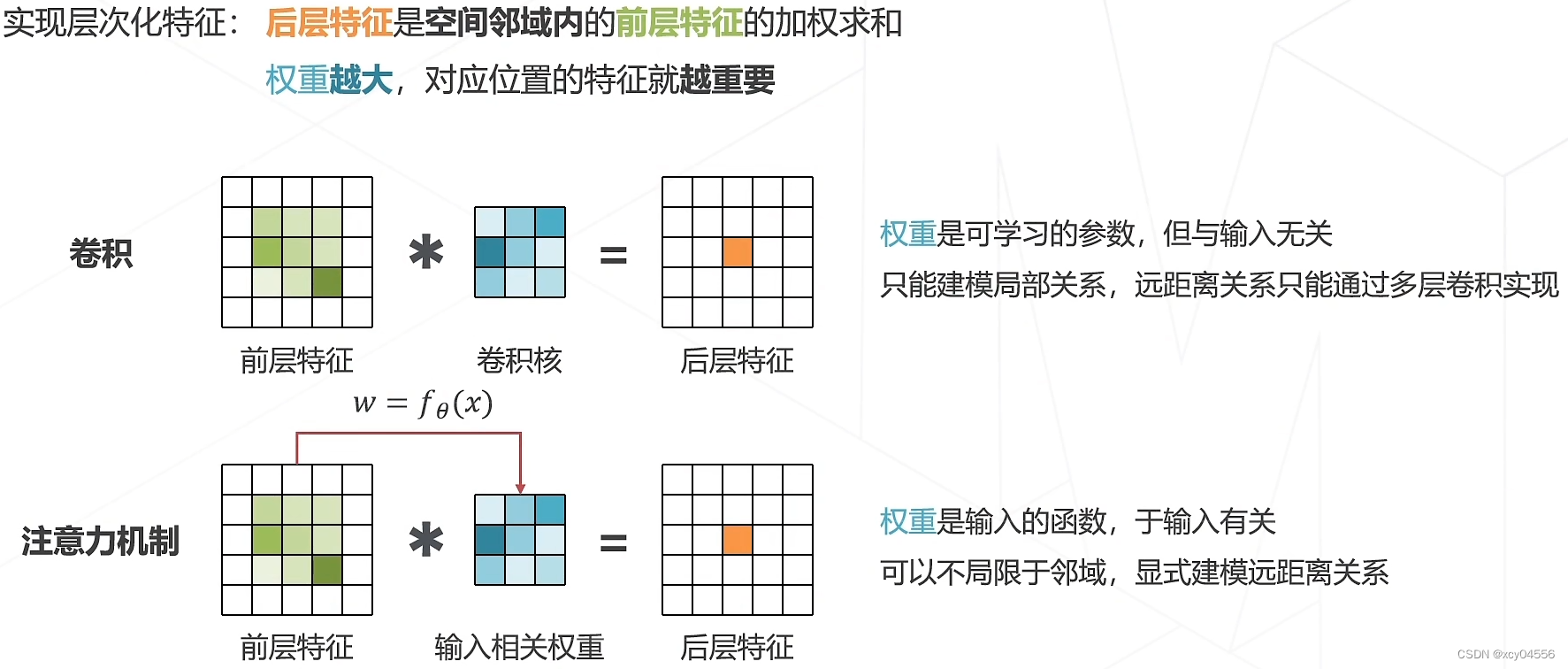
Vision Transformer(2020)

注意力机制Attention Mechanism
自监督学习
- 基于各种代理任务
- 基于对比学习
- 基于掩码学习














 112
112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









