







1 摘要
联邦学习(FL)允许多个客户在其私有数据上协作训练神经网络(NN)模型,而不会泄露数据。最近,针对FL的几起针对性中毒袭击事件已经出台。这些攻击为生成的模型注入了后门,使得对手控制的输入被错误分类。现有的反后门攻击的对策效率低下,通常只是为了将偏离模型排除在聚合之外。然而,这种方法还删除了具有偏差数据分布的客户机的良性模型,从而导致聚合模型对此类客户机的性能不佳。
为了解决这个问题,我们提出了DeepSight,一种用于缓解后门攻击的新型模型过滤方法。它基于三种新的技术,允许描述用于训练模型更新的数据分布,并寻求测量NN内部结构和输出中的细粒度差异。使用这些技术,DeepSight可以识别可疑的模型更新。我们还开发了一种方案,可以准确地对模型更新进行聚类。结合这两个组件的结果,DeepSight能够识别并消除包含具有高攻击影响的中毒模型的模型簇。我们还表明,可能未被发现的中毒模型的后门贡献可以通过现有的基于裁剪的防御有效缓解。我们评估了DeepSight的性能和有效性,并表明它可以缓解最先进的后门攻击,对模型在良性数据上的性能影响微乎其微。
1.1 攻击者的困境
攻击者可以任意选择攻击策略:一方面可以利用高比例的中毒数据训练后门任务;然而,这导致中毒模型不同于良性模型,使得中毒模型很容易被基于过滤的防御检测到。另一方面,如果对手不遵循此策略,则可以通过任何限制单个模型影响的防御措施轻松减轻攻击,因为良性模型的数量超过了中毒模型。因此,将两种防御策略结合在一起,会给对手造成一个两难的境地:要么攻击被防御的一部分过滤掉,要么另一部分使攻击的影响可以忽略不计。
1.2 本文的方法
为了解决这些问题,我们提出了DeepSight,这是一种新的模型过滤方法,它深入检查NN的内部结构和输出,以识别具有高攻击影响的恶意模型更新,同时保持良性模型更新,即使这些更新来自数据分布偏离的客户端。通过将我们的新过滤方案与裁剪相结合,我们利用了上述对抗困境,以确保对手的策略将训练集中在后门任务上。另一方面,这导致产生的NN的结构包含与此后门相关的工件。
主要贡献:
- 我们提出了DeepSight,这是一种新的防御方法,用于缓解针对联合学习(FL)的定向中毒(后门)攻击。DeepSight使用了一种新的过滤方案,该方案进行深度模型检查,并将其与剪切相结合,以识别目标中毒攻击。
- 我们提出了一种结合分类器和基于聚类的相似度估计的基于投票的模型过滤方案。单独的标签被用来可靠地识别带有恶意模型更新的集群,这样不仅使用一个模型的标签,还使用类似模型的标签来决定接受或拒绝一个模型更新。结合分类器作为中心机制,而不是基于异常值消除的策略,我们防止了数据分布偏离的良性客户端的模型被过滤掉,从而提高了聚合模型对这些客户端的数据的性能。
- 我们提出阈值超越度量,分析模型输出层的参数更新,以衡量其训练数据的同质性。我们使用这个度量来构建一个分类器,能够将模型更新标记为良性或可疑的。
- 基于三种不同的技术,我们设计了一种聚类算法的集成,以有效地识别和聚类具有相似训练数据的模型更新(§V -A3),以通过相似估计支持分类器。
- 我们提出了两种新的技术来测量nn结构和输出中的细粒度差异:第一种技术划分差异(DDifs)关注模型预测输出的变化,第二种方法是标准化更新能量(NEUPs)测量神经网络输出层参数更新的变化。据我们所知,这是第一项在联邦学习(FL)中对模型、预测和单个神经元进行深入分析以减轻中毒攻击的工作。
2 技术
2.1 Division Differences
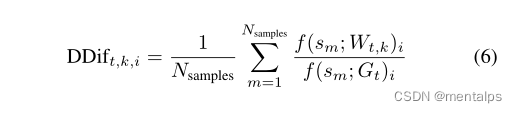
t
t
t代表联邦学习过程中的轮数,
k
k
k即为客户端的编号,
i
i
i为模型输出层的第i个神经元,
D
D
i
f
t
,
k
,
i
DDif_{t,k,i}
DDift,k,i代表在第t轮训练过程中第k个客户端的第i个神经元的划分差异。由于服务器没有训练样本或测试样本,因此文中采用的是随机数作为样本。想象一下如果两个客户端训练所用的数据是相似的,那么它们的DDif值就会是相似的。因此通过计算DDif就可以得出每个客户端的训练数据差异性。
2.2 Normalized Update Energy
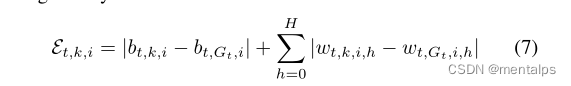
H
H
H:输出层神经元的个数
b
t
,
k
,
i
b_{t,k,i}
bt,k,i:在第t轮的第k个客户端的第i个输出神经元的偏移量
w
t
,
k
,
i
,
h
w_{t,k,i,h}
wt,k,i,h:输出层神经元的权重
ϵ
t
,
k
,
i
\epsilon_{t,k,i}
ϵt,k,i:客户端k在第t轮提交的模型的输出层神经元i的更新能力

C
t
,
k
,
i
C_{t,k,i}
Ct,k,i蕴藏着训练数据中标签的频率分布信息。归一化使得不同模型的频率分布具有可比性。因此,模型更新的单个neup不受该模型更新能量的总范围的影响。因此,来自不同模型的相似的neup说明不同客户端训练数据的相似比例具有相同的标签。
此外,它还使该技术在对抗对手A的混淆时更加健壮。否则,A可以使用一个客户端提交一个具有非常高的能量更新的模型,以使其余中毒模型的能量更新看起来更类似于良性模型。
2.3 Threshold Exceedings
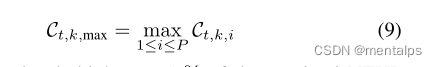

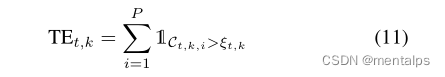
中毒模型的训练数据的异质性明显低于良性模型的训练数据。为了度量局部模型的NEUP的同质性,从而度量所使用训练数据的复杂性,我们基于该模型的最大NEUP为每个局部模型定义了一个阈值。然后我们计算每个模型有多少neup超过这个阈值。
为了将模型更新分类为良性或有害的,我们定义了阈值超过中位数的一半的分类边界。如果一个模型的阈值超出次数低于此阈值,则该模型被标记为有毒的。
- 计算输出层每一个神经元的更新量
- 对神经元的更新量进行归一化
- 利用最大更新量的神经元的值计算阈值
- 统计输出层神经元更新量超出阈值的个数
3 通过深度模型检查减轻对fl的后门攻击
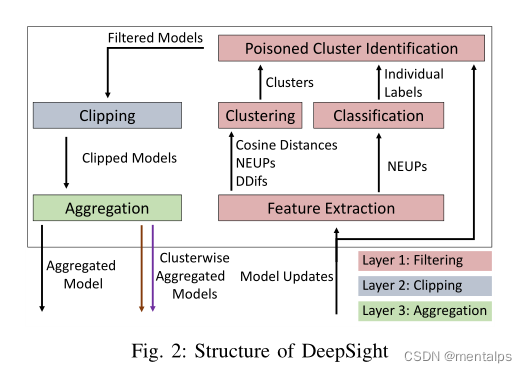
3.1 过滤层

Step1:计算两量客户端更新之间的余弦距离;
Step2:计算每个客户端的归一化更新量;
Step3:统计每一个客户端超出阈值的输出层神经元的个数thresh_exds;
Step4:使用三个随机数种子,分别计算每个客户端的DDIFs;
Step5:取thresh_exds的中位数的一半作为分类边界;
Step6:小于等于这个数的客户端被标记为有毒模型,记为1;
Step7:利用neups,ddifs,cosine_distances聚类;
Step8:统计每一个簇中的恶意模型的数量;
Step9:如果恶意模型的数量小于
τ
\tau
τ,则接受这个簇中的所有模型;

3.2 剪切层
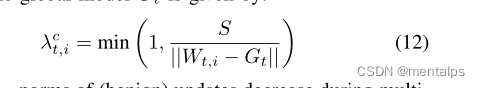
把模型的更新限制到S以内。S的取值为所有模型更新的中位数。
3.3 聚合层
在聚合层中,使用FedAvg将所有剩余的剪切模型聚合在一起。然而,在最后一轮中,聚合是按集群方式执行的,并且还包括筛选过的、裁剪过的模型,只有来自同一集群的模型被聚合在一起,每个客户端接收到为各自的集群聚合的模型。















 588
588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









