







1 摘要
虽然机器学习(ML)模型越来越被信任,可以在不同的领域做出决策,但使用这种模型的系统的安全性也越来越受到关注。特别是,ML模型通常使用来自潜在不可信来源的数据进行训练,为对手提供了通过将精心制作的样本插入训练集中来操纵它们的机会。最近的工作表明,这种类型的攻击被称为投毒攻击,允许对手在模型中插入后门或木马程序,在推断时使用简单的外部后门触发器,并且仅从模型本身的黑盒角度启用恶意行为。检测这种类型的攻击具有挑战性,因为只有当存在后门触发器时才会发生意外行为,而只有对手知道该触发器。模型用户,无论是训练数据的直接用户还是来自目录的预训练模型的用户,都不能保证其基于ml的系统的安全运行。在本文中,我们提出了一种用于神经网络的后门检测和清除的新方法。
本文的贡献:
- 我们提出了第一种检测恶意插入训练集的有毒数据的方法,以生成不需要验证和可信数据的后门。
- 我们通过在三个不同的文本和图像数据集上评估AC方法,证明了AC方法在检测不同应用程序中的有毒数据方面非常成功。
- 我们证明,AC方法是鲁棒的在复杂中毒场景下,其中类别是多模态的和多个后门插入。
2 本文方法
2.1 基本原理
我们的方法背后的直觉是,虽然后门和目标样本受到有毒网络的相同分类,但它们受到这种分类的原因是不同的。在来自目标类的标准样本的情况下,网络在输入中识别它已经学习到的与目标类对应的特征。在后门示例的情况下,它会识别与源类和后门触发器相关的特征,这将导致它将输入分类为目标类。这种机制上的差异在网络激活中应该是明显的,它代表了网络如何做出“决定”。
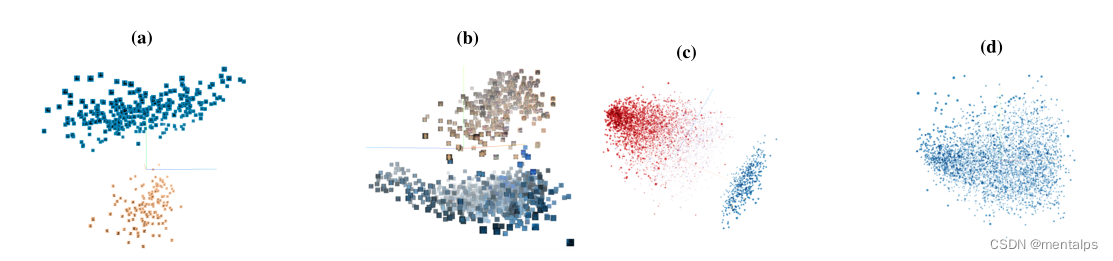
最后一个隐藏层的激活投影到前3个原理组件上。最后一个隐藏层的激活投影到前3个原理组件上。(a)激活标记为6的图像。(b)激活标有速度限制的图像。©(中毒)负面评论类的激活(d)(正常)正面评论类的激活。
2.2 算法

Step1:使用不可信的数据训练模型;
Step2:初始化
A
A
A,
A
[
i
]
A[i]
A[i]表示对应i标签的激活层的数据;
Step3:收集每一个样本对应的激活层数据;
Step4:采用PCA技术对每一类标签进行降维;
Step5:采用kemans方法对降维的数据聚类;
Step6:分析聚类结果;
2.3 聚类分析方法
1)Exclusionary Reclassification:
我们的第一个聚类分析方法涉及训练一个新模型,而不需要与相关聚类对应的数据。一旦训练好新模型,我们就用它来对不同的聚类进行分类。如果集群包含合法数据的激活,然后我们预计相应的数据将在很大程度上被分类为他的标签。但是,如果群集包含有毒数据,则模型将在很大程度上将数据分类为源类。因此,我们建议以下ExRe评分评估给定的集群是否对应于有毒数据。设
l
l
l是集群中分类为其标签的数据点的数量。设p为分类为C的数据点数,其中C是除了标签之外的大多数数据点被分类的类别。那么如果
l
/
p
>
T
l/p>T
l/p>T,其中T是防御者设置的阈值,我们认为集群是合法的,如果
l
/
p
>
T
l/p>T
l/p>T,我们认为它有毒,其中p是毒物的源类。我们建议使用默认值阈值参数的值为1,但可以调整根据防御者的需要。
2)Relative Size Comparison:
分析这两个聚类的一种更简单快捷的方法是比较它们的相对大小。在我们的实验中(参见后续章节),我们发现通过2-均值聚类,有毒数据的激活几乎总是(99%的时间)被放置在与合法数据不同的集群中。因此,当带有给定标签的p%数据被毒害时,我们期望一个集群包含大约p%的数据,而另一个集群包含大约(100 - p)%的数据。相比之下,当数据没有中毒时,我们发现激活倾向于分离成两个大小差不多相等的集群。因此,如果我们期望对给定标签不超过p%的数据可以被对手毒害,那么如果集群包含≤p%的数据,我们就可以认为集群是有毒的。
3)Silhouette Score:
图2c和图2d表明,两个簇更好地描述了数据中毒时的激活,但一个簇更好地描述了数据未中毒时的激活。因此,我们可以使用度量来评估集群数量与激活匹配的程度,以确定相应的数据是否已被毒害。我们发现在这方面工作得很好的是轮廓评分,轮廓分数低表明聚类不能很好地拟合数据,可以认为该类是无害的。轮廓分数高表明两个集群确实很好地拟合了数据,并且,假设对手不能毒害超过一半的数据,我们可以认为较小的集群可以被认为是有毒的。理想情况下,可以使用干净可信的数据集来确定干净数据的预期轮廓分数。否则,我们在MNIST、LISA和 Rotten Tomatoes数据集上的实验表明0.10和0.15之间的阈值是合理的。
2.4 后门修复
一旦使用激活聚类识别出有毒数据,在使用模型之前仍然需要修复模型。当然,一种选择是简单地删除有害数据并从头开始重新训练模型。然而,一个更快的选择是用它的源类重新标记有毒数据,并继续在这些样本上训练模型,直到它再次收敛。

















 4829
4829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









