







every blog every motto: You will never know unless you try
0. 前言
本文旨在讲解有关语义分割的基础内容,并进行实战。
1. 正文
1.1 前提梗概
1.1.1 引言
不要强求不可知,要从已知推未知
为了更好的了解语义分割,会先简单回顾一下作为深度学习“Hello World ”的mnist / fashion-mnist
1.1.2 mnist / fashion_mnsit
mnist是一个手写数字识别的数据集,一张图像上只有一个数字,如下图所示
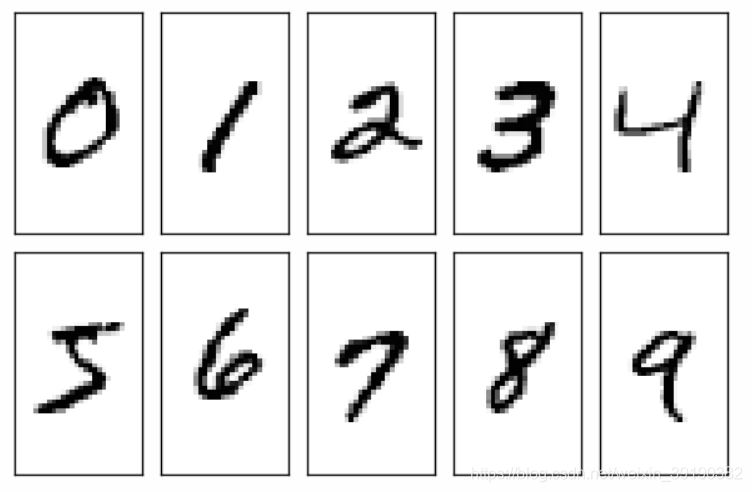
上面每张图片即是一个原图/样本(x),他的标签是对应数字的字符(y / label)
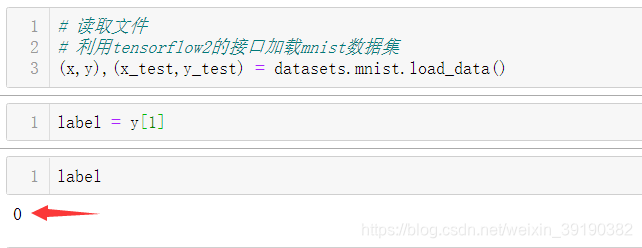
主要任务是分类,即对识别每张图片的数字!
有关fashion_mnist数据集也是类似,具体可参考想看就点我
总结: mnist/fashion_mnist ,原图 / 训练样本(x)是一张仅含一种物体的图片,标签(y) 是一个字符或者说one_hot编码。对其处理也较为简单,属于分类任务
1.2 语义分割基础
1.2.1 概念
- 直观理解:
一言以蔽之: 是将一张(含有多种物体的)图片,识别出其中的每一种物体。
语义分割的直观理解,如下图所示。
动画理解(实际意义):

最简单的语义分割,当属于“二分类”,即识别出图片中的两种地物,一种归为背景,另一种归为想要提取的物体(如我们接下来要说的斑马线) - 进一步理解:
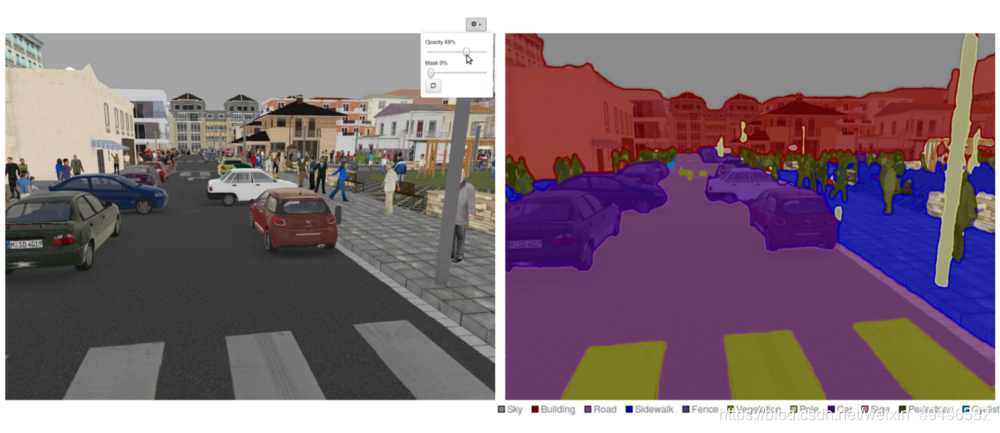
我们以遥感影像为例,如下图所示:
左边是原图/样本(x),右图是标签(label,黑色的是背景,红色的是标注的建筑物)
注: 标注自己的训练样本
这里的标签是一张图片,不同于mnsit(标签是一个字符串)
这里的标签是一张图片,不同于mnsit(标签是一个字符串)
这里的标签是一张图片,不同于mnsit(标签是一个字符串)

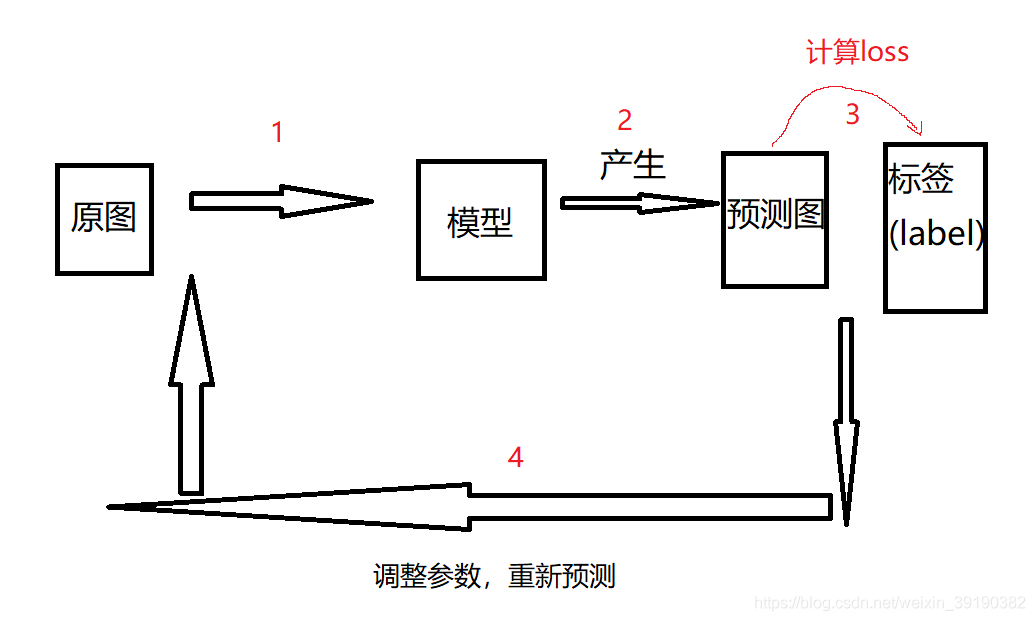
- 更进一步理解:
通过如下过程,不断计算损失函数,调整参数,直至loss函数最小,即参数最优为止。
- 深入理解:
整个网络如下图所示,分为两部分,分别是编码、解码部分。
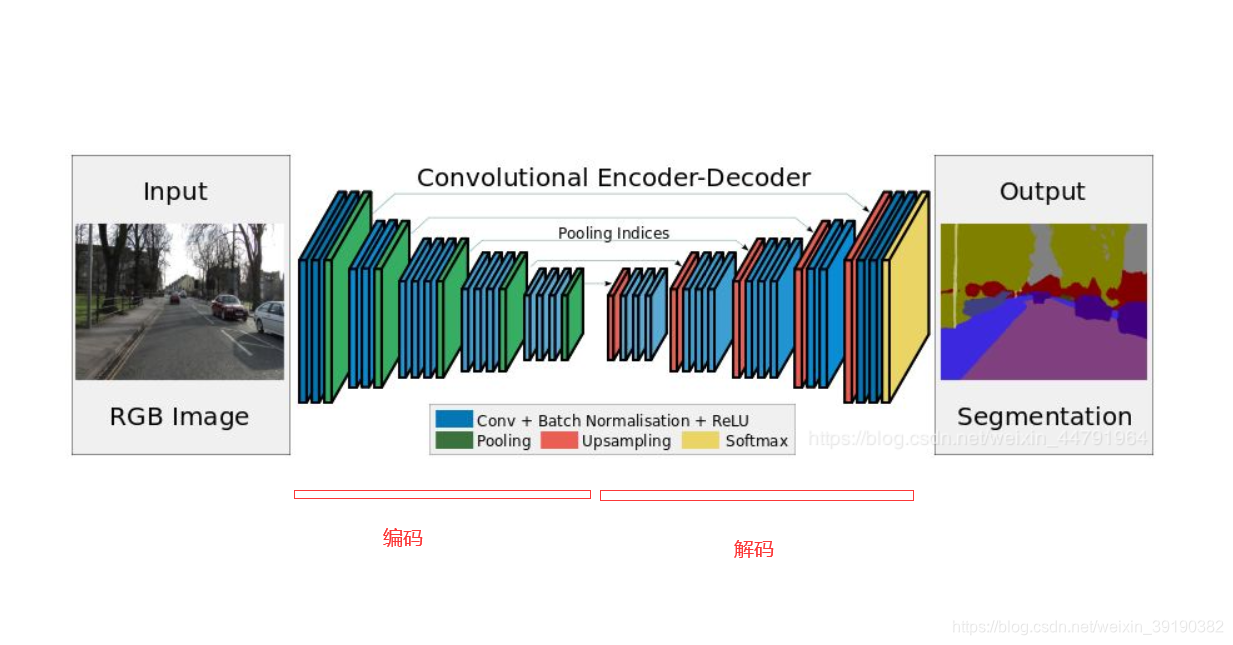
图像shape的变化:
编码:图像(size)不断变小,同时不断变厚(通道数增加)
解码:图像(size)不断变大(最终恢复到原图的1/2),同时不断变薄(通道数减小)
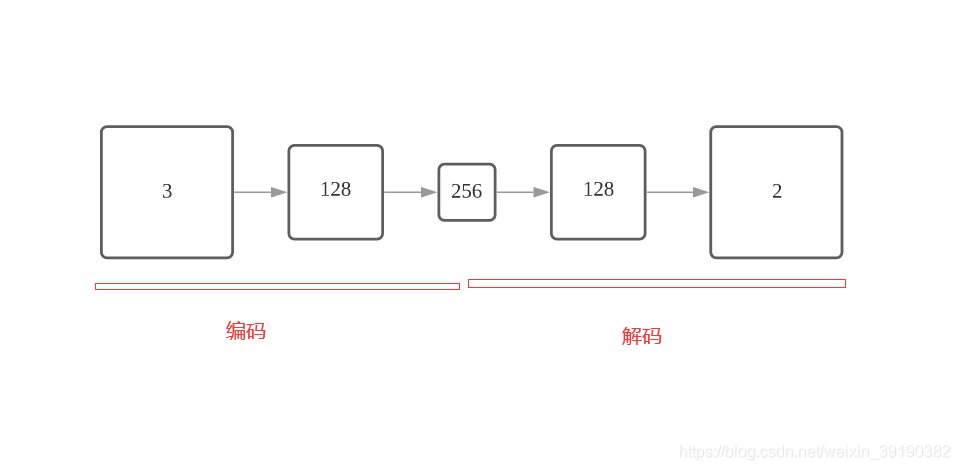
1.2.2 网络结构
说明: 网络结构如下图所示,但其中size和shape的具体数字与代码中不对,原因是我用此网络跑了其他的图片,也是基于别的图片画的网络结构,由此可以看出,各输入图片经过模型后,各特征图的缩放比例没有变化,在于初始大小不同而已。

链接: 用Plotneuralnet画神经网络图
1.2.3 结果展示
使用下方代码,进行预测,最终结果。
原图:

预测结果:
可以发现,基本将斑马线标出,由于训练数据(191个)较少,有这样的结果还算不错。

1.3 代码部分
说明: 具体代码,文后附链接。
1.3.1 模型部分(model.py)
主函数如下:
如上所说,模型分为两部分,编码、解码。
def main():
"""
model 的主程序,语义分割,分为两部分,第一部分特征提取,第二部分放大图片
:param Height: 图片长
:param Width: 图片宽
:return: (H,W,3) -> (h,w,2)
"""
# 第一部分 编码,提取特征,图像size减小,通道增加
img_input, feature_map_list = encoder(input_height=Height, input_width=Width)
# 第二部分 解码,将图像上采样,size放大,通道减小
output = decoder(feature_map_list, class_number=class_number, input_height=Height, input_width=Width,
encoder_level=3)
# 构建模型
model = Model(img_input, output)
# model.summary()
print('模型输入shape:', img_input.shape, '模型输出图像shape:', output.shape)
print('-'*100)
return model
模型的前半部分,编码部分:
下采样过程,下采样包括卷积和池化。
基于VGG16的编码网络,用于提取特征,有关卷积运算可参考文章1、文章2
def encoder(input_height, input_width):
"""
语义分割的第一部分,特征提取,主要用到VGG网络,函数式API
:param input_height: 输入图像的长
:param input_width: 输入图像的宽
:return: 返回:输入图像,提取到的5个特征
"""
# 输入
img_input = Input(shape=(input_height, input_width, 3))
# print('--')
# print(img_input.shape)
# 三行为一个结构单元,size减半
# 416,416,3 -> 208,208,64,
x = Conv2D(64, (3, 3), activation='relu', padding='same')(img_input)
x = Conv2D(64, (3, 3), activation='relu', padding='same')(x)
x = MaxPool2D((2, 2), strides=(2, 2))(x)
f1 = x # 暂存提取的特征
# 208,208,64 -> 104,104,128
x = Conv2D(128, (3, 3), activation='relu', padding='same')(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same')(x)
x = MaxPool2D((2, 2), strides=(2, 2))(x)
f2 = x # 暂存提取的特征
# 104,104,128 -> 52,52,256
x = Conv2D(256, (3, 3), activation='relu', padding='same')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same')(x)
x = MaxPool2D((2, 2), strides=(2, 2))(x)
f3 = x # 暂存提取的特征
# 52,52,256 -> 26,26,512
x = Conv2D(512, (3, 3), activation='relu', padding='same')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same')(x)
x = MaxPool2D((2, 2), strides=(2, 2))(x)
f4 = x # 暂存提取的特征
# 26,26,512 -> 13,13,512
x = Conv2D(512, (3, 3), activation='relu', padding='same')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same')(x)
x = MaxPool2D((2, 2), strides=(2, 2))(x)
f5 = x # 暂存提取的特征
# print(img_input.shape[1:])
return img_input, [f1, f2, f3, f4, f5]
模型的后半部分,解码部分:
上采样过程,
关于模型后半部分的经过softmax的理解,2020.9.26添加
def decoder(feature_map_list, class_number, input_height=416, input_width=416, encoder_level=3):
"""
语义分割的后半部分,上采样,将图片放大,
:param feature_map_list: 特征图(多个),encoder得到
:param class_number: 分类数
:param input_height: 输入图像长
:param input_width: 输入图像宽
:param encoder_level: 利用的特征图,这里利用f4
:return: output , 返回放大后的特征图 (208*208,2)
"""
# 获取一个特征图,特征图来源encoder里面的f1,f2,f3,f4,f5; 这里获取f4
feature_map = feature_map_list[encoder_level]
# 解码过程 ,以下 (26,26,512) -> (208,208,64)
# f4.shape=(26,26,512) -> 26,26,512
x = ZeroPadding2D((1, 1))(feature_map)
x = Conv2D(512, (3, 3), padding='valid')(x)
x = BatchNormalization()(x)
# 上采样,图像长宽扩大2倍,(26,26,512) -> (52,52,256)
x = UpSampling2D((2, 2))(x)
x = ZeroPadding2D((1, 1))(x)
x = Conv2D(256, (3, 3), padding='valid')(x)
x = BatchNormalization()(x)
# 上采样,图像长宽扩大2倍 (52,52,512) -> (104,104,128)
x = UpSampling2D((2, 2))(x)
x = ZeroPadding2D((1, 1))(x)
x = Conv2D(128, (3, 3), padding='valid')(x)
x = BatchNormalization()(x)
# 上采样,图像长宽扩大2倍,(104,104,128) -> (208,208,64)
x = UpSampling2D((2, 2))(x)
x = ZeroPadding2D((1, 1))(x)
x = Conv2D(64, (3, 3), padding='valid')(x)
x = BatchNormalization()(x)
# 再进行一次卷积,将通道数变为2(要分类的数目) (208,208,64) -> (208,208,2)
x = Conv2D(class_number, (3, 3), padding='same')(x)
# print(x.shape)
# reshape: (208,208,2) -> (208*208,2)
# y = Reshape((208,208,-1))(x)
# print('y shape:',y.shape)
x = Reshape((int(input_height / 2) * int(input_width / 2), -1))(x)
# print(x.shape)
# 求取概率
output = Softmax()(x)
return output
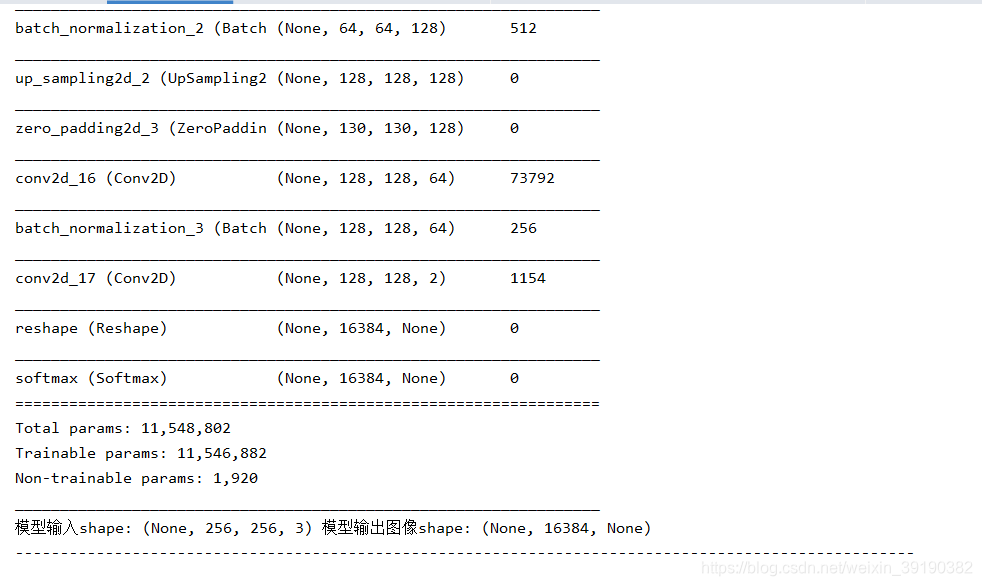
网络结构,summary:
1.3.2 训练部分(train.py)
主函数,如下:
def main():
# 获取已建立的模型,并加载官方与训练参数,模型编译
model = get_model()
# 打印模型摘要
# model.summary()
# 获取样本(训练集&验证集) 和标签的对应关系,trian_num,val_num
lines, train_nums, val_nums = get_data()
# 设置回调函数 并返回保存的路径
callbacks, logdir = set_callbacks()
# 生成样本和标签
# generate_arrays_from_file(lines, batch_size=batch_size)
# 训练
model.fit_generator(generate_arrays_from_file(lines[:train_nums], batch_size),
steps_per_epoch=max(1, train_nums // batch_size),
epochs=50, verbose=1, callbacks=callbacks,
validation_data=generate_arrays_from_file(lines[train_nums:], batch_size),
validation_steps=max(1, val_nums // batch_size),
initial_epoch=0)
save_weight_path = os.path.join(logdir, 'last.h5') # 保存模型参数的路径
model.save_weights(save_weight_path)
1.3.3 预测部分(predict.py)
axis参数辨析,点我
主函数,如下:
def main():
""" 模型预测"""
model = get_model()
predicting(model)
1.4 源码及视频讲解
1.4.1 源码
https://github.com/onceone/Semantic-segmentation
数据集:提取码pp6w —>数据集来源
1.4.2 视频讲解
感谢评论区shu_0233的指出。
https://www.bilibili.com/video/BV1Bi4y1G7PE?from=search&seid=9616538879256765990
知识无价,如果帮助到你,不妨请喝一杯奶茶~~


参考文献
[1] https://blog.csdn.net/weixin_39190382/article/details/105890812
[2] https://blog.csdn.net/weixin_44791964/article/details/102979289
[3] https://baijiahao.baidu.com/s?id=1602428106371812559&wfr=spider&for=pc
[4] https://blog.csdn.net/weixin_40446557/article/details/85624579
[5] https://www.sohu.com/a/301097998_120054440
[6] https://www.cnblogs.com/xianhan/p/9145966.html
[7] https://blog.csdn.net/weixin_39190382/article/details/105692853
[8] https://blog.csdn.net/weixin_39190382/article/details/105702100
[9] https://blog.csdn.net/weixin_39190382/article/details/104083347
[10] https://blog.csdn.net/weixin_39190382/article/details/108803650



















 3582
3582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











