







前言
本文将从零到一地介绍如何使用 Python 语言,基于 DeepSeek 大模型能力,开发一款辅助记忆英语单词的 AI Agent 智能体。
这是本人于 2025 年 2 月某个周末突发奇想写的 AI Agent,相信你即使是小白也能学会如何构造简单的结构化提示词,并开发简易的 AI 智能体。
完整代码开源地址:https://github.com/Tr0e/EnglishAIAgent。欢迎关注我的 Github,获取更多开源代码。
单词AI智能体
应用思路来源
思路来源于一次无意间与 DeepSeek AI 的问答:

如此生动的单词记忆法自然会备受人们的喜爱,那么我是不是可以写个 AI 工具,当我把单词列表(比如大学英语四级词汇)传入我的工具,每个单词自动讲一个故事帮助记忆,并自动生成一篇汇总文档?
定制化Prompt
提示词是开发 AI Agent 的灵魂,它帮助我们引导 LLM 大模型完成我们预期的任务。写出一份高质量的提示词,是解决 AI Agent 开发的关键环节。
先定义提示词,此处直接给出答案:
markdown_prompt = """
## 角色定义
你是一名专业的英语教师,擅长以生动、易懂的方式传授不喜欢记忆的学生如何记住英语单词。
## 工作规则
- 你的方法是通过联想记忆、分解记忆、词根记忆等方式,摆脱枯燥的死记硬背。
- 你将获取到一个单词列表,请逐一分析每个单词的中文意思,然后构思如何才能让学生轻松地记住。
## 具体示例
比如你会让学生这样记住救护车(ambulance)的单词:
1)联想记忆:想象一辆救护车(ambulance)在紧急情况下飞驰而过,发出“俺不能死”(ambulance的谐音)的呼声,这样的联想可以帮助你记住这个单词。
2)分解记忆:将“ambulance”分解为“am”(是)、“bu”(不)、“lan”(拦)、“ce”(车),可以编成一个小故事:“我(am)不(bu)拦(lan)车(ce),因为那是救护车”。
## 响应格式
最后请按照以下格式返回数据:
1)通过json字符串存储你的分析结果,json字符串包含:单词、单词中文释义、音标、最佳的记忆方法;
2)完整的格式示例如下,请务必严格遵守此格式:
{
response:[
{
"word": "ambulance",
"pronounce": "/ˈæmbjʊləns/",
"chinese_meaning": "救护车",
"memory_method": "联想记忆法:想象一辆救护车在紧急情况下飞驰而过,发出'俺不能死'(ambulance的谐音)的呼声"
},
{
"word": "butterfly",
"pronounce": "/ˈbʌtəflaɪ/",
"chinese_meaning": "蝴蝶",
"memory_method": "分解记忆法:有一只蝴蝶,它的翅膀上涂满了黄油(butter),在空中飞(fly)来飞去,非常引人注目"
}
]
}
"""
上述提示词采用了提示词工程里面几种主流的技巧:结构化提示词、少样本提示等。关于构建高质量提示词的方法,推荐学习:提示工程指南。
Agent代码编写
通过 txt 存储待分析的单词列表:
接着构造 AI Agent 的代码,由于 DeepSeek 官方 API Key 目前无法申请,改用硅基流动平台的 API:
"""
@File:EnglishAiAgent.py
@Time:2025/2/8 21:23
@Auth:Tr0e
@Github:https://github.com/Tr0e
@Description:借助DeepSeek大模型,自动生成英语单词的助记文档
@版本迭代:
v1.0 2025/02/08,首版本开发完成
"""
import json
import requests
markdown_prompt = """
## 角色定义
你是一名专业的英语教师,擅长以生动、易懂的方式传授不喜欢记忆的学生如何记住英语单词。
## 工作规则
- 你的方法是通过联想记忆、分解记忆、词根记忆等方式,摆脱枯燥的死记硬背。
- 你将获取到一个单词列表,请逐一分析每个单词的中文意思,然后构思如何才能让学生轻松地记住。
## 具体示例
比如你会让学生这样记住救护车(ambulance)的单词:
1)联想记忆:想象一辆救护车(ambulance)在紧急情况下飞驰而过,发出“俺不能死”(ambulance的谐音)的呼声,这样的联想可以帮助你记住这个单词。
2)分解记忆:将“ambulance”分解为“am”(是)、“bu”(不)、“lan”(拦)、“ce”(车),可以编成一个小故事:“我(am)不(bu)拦(lan)车(ce),因为那是救护车”。
## 响应格式
最后请按照以下格式返回数据:
1)通过json字符串存储你的分析结果,json字符串包含:单词、单词中文释义、音标、最佳的记忆方法;
2)完整的格式示例如下,请务必严格遵守此格式:
{
response:[
{
"word": "ambulance",
"pronounce": "/ˈæmbjʊləns/",
"chinese_meaning": "救护车",
"memory_method": "联想记忆法:想象一辆救护车在紧急情况下飞驰而过,发出'俺不能死'(ambulance的谐音)的呼声"
},
{
"word": "butterfly",
"pronounce": "/ˈbʌtəflaɪ/",
"chinese_meaning": "蝴蝶",
"memory_method": "分解记忆法:有一只蝴蝶,它的翅膀上涂满了黄油(butter),在空中飞(fly)来飞去,非常引人注目"
}
]
}
"""
def siliconflow_api_call_by_block(user_question, api_key, prompt):
"""
通过硅基流动平台调用deepseek模型(阻塞模式响应)
"""
url = "https://api.siliconflow.cn/v1/chat/completions"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = {
"model": "deepseek-ai/DeepSeek-V3",
"messages": [
{
"role": "system",
"content": f"{prompt}"
},
{
"role": "user",
"content": user_question
}
],
"stream": False,
"max_tokens": 4096,
"stop": ["null"],
"temperature": 0.7,
"top_p": 0.7,
"top_k": 50,
"frequency_penalty": 0.5,
"n": 1,
"response_format": {"type": "text"},
"tools": []
}
response = requests.request("POST", url, json=payload, headers=headers)
# print(response.text)
if response.status_code == 200:
json_obj = json.loads(response.text)
result = json_obj['choices'][0]['message']['content']
print(f"[+]AI的回答:\n{result}")
return result
else:
print(f"[!]请求失败,状态码:{response.status_code}")
return None
def generate_markdown(data, filename="words.md"):
"""
生成一个Markdown文档,将提供的单词数据以表格形式展示。
"""
# 构建Markdown表格内容
markdown_content = "# 英语单词助记文档 \n\n"
markdown_content += "| 单词 | 音标发音 | 单词含义 | 记忆方法 |\n"
markdown_content += "|------|-----------|-----------------|---------------|\n"
# 检查data是否为字典,并且包含'response'键
if isinstance(data, dict) and 'response' in data:
items = data['response']
else:
print("[-]Error: 数据格式不正确,无法找到'response'字段。")
return
for item in items:
# 检查每个item是否为字典
if isinstance(item, dict):
markdown_content += f"| {item.get('word', '')} | {item.get('pronounce', '')} | {item.get('chinese_meaning', '')} | {item.get('memory_method', '')} |\n"
else:
print(f"[-]Warning: Item is not a dictionary: {item}")
# 将Markdown内容写入文件
with open(filename, "w", encoding="utf-8") as file:
file.write(markdown_content)
print(f"[+]Success! Markdown文件已生成:{filename}")
def process_words(api_key, prompt):
# 读取单词文件并分割成列表
with open("word.txt", "r", encoding="utf-8") as f:
words = f.read().splitlines()
# 初始化存储所有结果的列表
all_data = []
batch_size = 3 # 每批次最多3个单词,确保不会超出API响应最大长度限制
# 分批次处理
for i in range(0, len(words), batch_size):
batch = words[i:i + batch_size]
print(f"[+]正在处理第 {i // batch_size + 1} 批单词: {', '.join(batch)}")
# 拼接当前批次的单词(保持每行一个单词的格式)
word_block = "\n".join(batch)
api_response = siliconflow_api_call_by_block(word_block, api_key, prompt)
if api_response is None:
print(f"❌第 {i // batch_size + 1} 批处理失败,请检查API密钥和网络连接")
continue
try:
# 清洗并解析JSON响应
cleaned_response = api_response.strip("```json").strip("```")
batch_data = json.loads(cleaned_response)
# 合并到总数据集
all_data.extend(batch_data["response"])
print(f"✅第 {i // batch_size + 1} 批处理成功,累计已处理 {len(all_data)} 个单词")
except json.JSONDecodeError as e:
print(f"❌第 {i // batch_size + 1} 批JSON解析失败: {str(e)}")
print("原始响应内容:")
print(api_response)
# 生成最终Markdown文件
if all_data:
generate_markdown({"response": all_data})
print(f"\n🎉全部处理完成,共成功处理 {len(all_data)} 个单词")
else:
print("\n⚠️未成功处理任何单词")
if __name__ == '__main__':
process_words("sk-XXX", markdown_prompt)
整份代码逻辑流程很简单:
- 从本地读取待转换的英语单词列表,比如中小学词汇、大学四六级词汇;
- 构建提示词,引导 AI 大模型针对每个单词构造一个容易记忆的方法,并返回结果;
- 借助 Python 本地将 AI 返回的结果整理生成一个 Markdown 文件,方便查阅。
Agent效果演示
运行效果如下:
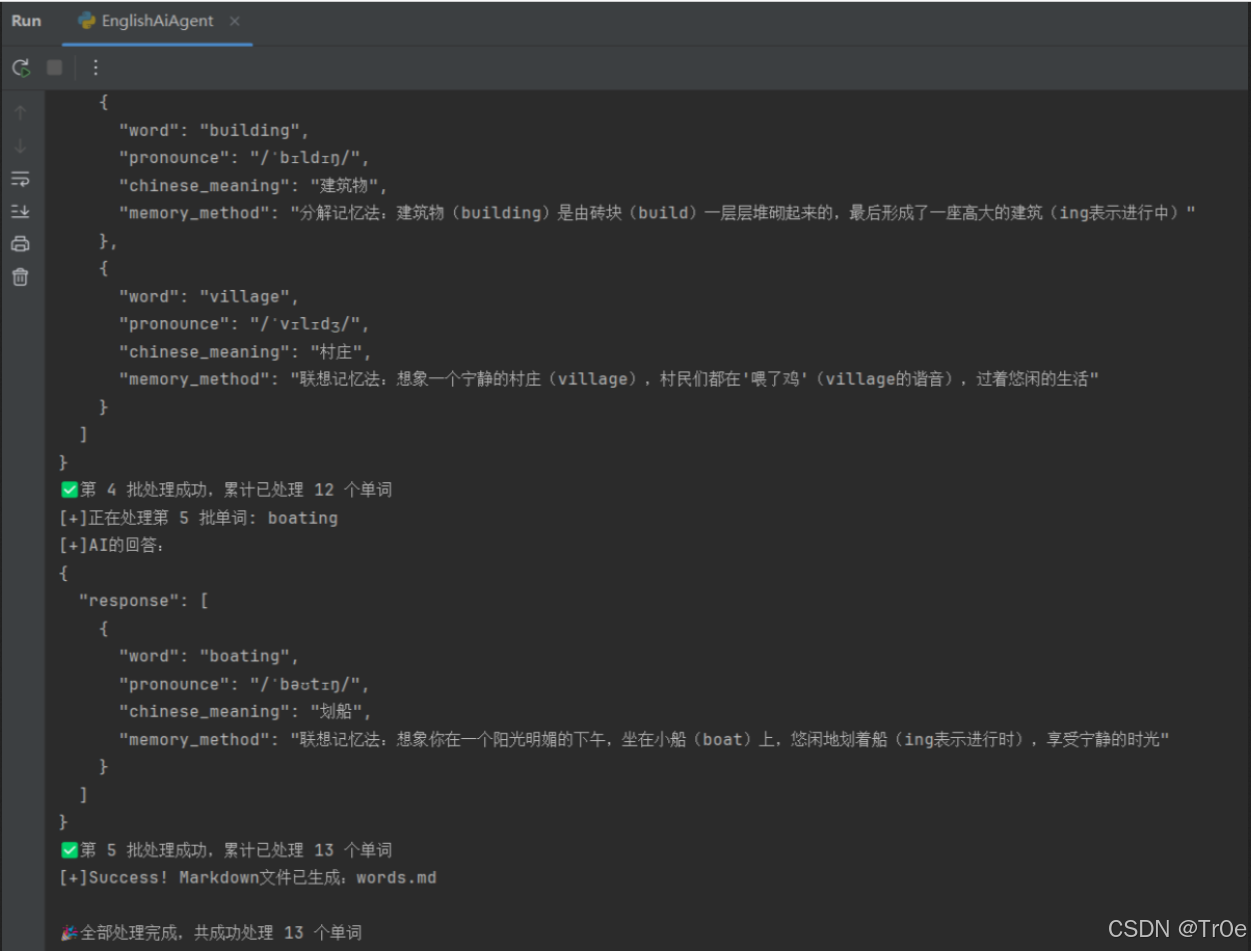
生成的 Markdown 文件:

完整运行日志:
python.exe D:\EnglishAiAgent.py
[+]正在处理第 1 批单词: beside, behind, nature
[+]AI的回答:
{
"response": [
{
"word": "beside",
"pronounce": "/bɪˈsaɪd/",
"chinese_meaning": "在旁边",
"memory_method": "联想记忆法:想象一个人站在你的旁边(beside),你对他轻声说'别塞的'(beside的谐音),让他不要挤你"
},
{
"word": "behind",
"pronounce": "/bɪˈhaɪnd/",
"chinese_meaning": "在后面",
"memory_method": "分解记忆法:将'behind'分解为'be'(是)和'hind'(后部),可以编成一个小故事:'我(be)在后部(hind)等着你,所以我在后面(behind)'"
},
{
"word": "nature",
"pronounce": "/ˈneɪtʃər/",
"chinese_meaning": "自然",
"memory_method": "词根记忆法:'nature'的词根是'natus',意为出生。可以想象大自然(nature)是所有生命的出生地,这样就能记住这个单词"
}
]
}
✅第 1 批处理成功,累计已处理 3 个单词
[+]正在处理第 2 批单词: forest, river, lake
[+]AI的回答:
{
"response": [
{
"word": "forest",
"pronounce": "/ˈfɒrɪst/",
"chinese_meaning": "森林",
"memory_method": "联想记忆法:想象你在森林(forest)里,四周都是高大的树木,你听到风吹过树叶发出'佛瑞斯特'的声音,仿佛在呼唤你进入这片神秘的绿色世界"
},
{
"word": "river",
"pronounce": "/ˈrɪvə/",
"chinese_meaning": "河流",
"memory_method": "分解记忆法:将'river'分解为'ri'(日)和'ver'(维尔),想象太阳(日)照耀在维尔河上,河水波光粼粼,美丽动人"
},
{
"word": "lake",
"pronounce": "/leɪk/",
"chinese_meaning": "湖泊",
"memory_method": "谐音记忆法:湖泊(lake)的发音类似于'累渴',想象你在炎热的夏天走了很久的路,感到又累又渴,突然看到一片清澈的湖泊,立刻跳进去解渴"
}
]
}
✅第 2 批处理成功,累计已处理 6 个单词
[+]正在处理第 3 批单词: mountain, hill, tree
[+]AI的回答:
{
"response": [
{
"word": "mountain",
"pronounce": "/ˈmaʊntɪn/",
"chinese_meaning": "山",
"memory_method": "联想记忆法:想象一座大山(mountain)上有一个巨大的'馒头'(mountain的谐音),这样的联想可以帮助你记住这个单词"
},
{
"word": "hill",
"pronounce": "/hɪl/",
"chinese_meaning": "小山丘",
"memory_method": "分解记忆法:将'hill'分解为'hi'(嗨)和'll'(两个L),可以编成一个小故事:'嗨(hi),这两个L(ll)形状的小山丘真可爱'"
},
{
"word": "tree",
"pronounce": "/triː/",
"chinese_meaning": "树",
"memory_method": "联想记忆法:想象一棵树(tree)上挂满了'T恤'(tree的谐音),这样的联想可以帮助你记住这个单词"
}
]
}
✅第 3 批处理成功,累计已处理 9 个单词
[+]正在处理第 4 批单词: bridge, building, village
[+]AI的回答:
{
"response": [
{
"word": "bridge",
"pronounce": "/brɪdʒ/",
"chinese_meaning": "桥",
"memory_method": "联想记忆法:想象一座桥(bridge)连接两岸,桥上的行人都在'不急'(bridge的谐音)地慢慢走过,享受风景"
},
{
"word": "building",
"pronounce": "/ˈbɪldɪŋ/",
"chinese_meaning": "建筑物",
"memory_method": "分解记忆法:建筑物(building)是由砖块(build)一层层堆砌起来的,最后形成了一座高大的建筑(ing表示进行中)"
},
{
"word": "village",
"pronounce": "/ˈvɪlɪdʒ/",
"chinese_meaning": "村庄",
"memory_method": "联想记忆法:想象一个宁静的村庄(village),村民们都在'喂了鸡'(village的谐音),过着悠闲的生活"
}
]
}
✅第 4 批处理成功,累计已处理 12 个单词
[+]正在处理第 5 批单词: boating
[+]AI的回答:
{
"response": [
{
"word": "boating",
"pronounce": "/ˈbəʊtɪŋ/",
"chinese_meaning": "划船",
"memory_method": "联想记忆法:想象你在一个阳光明媚的下午,坐在小船(boat)上,悠闲地划着船(ing表示进行时),享受宁静的时光"
}
]
}
✅第 5 批处理成功,累计已处理 13 个单词
[+]Success! Markdown文件已生成:words.md
🎉全部处理完成,共成功处理 13 个单词
Process finished with exit code 0
总结
本文从零到一地介绍如何开发一款辅助记忆英语单词的 AI Agent 智能体英语,相信你即使是小白也能学会如何构造简单的结构化提示词,并开发简易的 AI 智能体。
完整代码开源地址:https://github.com/Tr0e/EnglishAIAgent。欢迎关注我的 Github,获取更多开源代码。



















 853
853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











