






一、什么是 GGUF?
GGUF 格式的全名为(GPT-Generated Unified Format),提到 GGUF 就不得不提到它的前身 GGML(GPT-Generated Model Language)。GGML 是专门为了机器学习设计的张量库,最早可以追溯到 2022/10。其目的是为了有一个单文件共享的格式,并且易于在不同架构的 GPU 和 CPU 上进行推理。但在后续的开发中,遇到了灵活性不足、相容性及难以维护的问题。
二、为什么要转换 GGUF 格式
在传统的 Deep Learning Model 开发中大多使用 PyTorch 来进行开发,但因为在部署时会面临相依 Lirbrary 太多、版本管理的问题于才有了 GGML、GGMF、GGJT 等格式,而在开源社群不停的迭代后 GGUF 就诞生了。
GGUF 实际上是基于 GGJT 的格式进行优化的,并解决了 GGML 当初面临的问题,包括:
1)可扩展性:轻松为 GGML 架构下的工具添加新功能,或者向 GGUF 模型添加新 Feature,不会破坏与现有模型的兼容性。
2)对 mmap(内存映射)的兼容性:该模型可以使用 mmap 进行加载(原理解析可见参考),实现快速载入和存储。(从 GGJT 开始导入,可参考 GitHub)
3)易于使用:模型可以使用少量代码轻松加载和存储,无需依赖的 Library,同时对于不同编程语言支持程度也高。
4)模型信息完整:加载模型所需的所有信息都包含在模型文件中,不需要额外编写设置文件。
5)有利于模型量化:GGUF 支持模型量化(4 位、8 位、F16),在 GPU 变得越来越昂贵的情况下,节省 vRAM 成本也非常重要。
三、以 Qwen2-0.5B 为例
1、模型下载
# from huggingface_hub import snapshot_download
from modelscope import snapshot_download
model_id="Qwen/Qwen2-0.5B-Instruct"
snapshot_download(model_id=model_id, cache_dir="qwen2_0.5b_instruct")
2、开始转换hf模型为gguf
需要用llama.cpp仓库的convert_hf_to_gguf.py脚本来转换
git clone https://github.com/ggerganov/llama.cpp.git
pip install -r llama.cpp/requirements.txt执行转换
# 如果不量化,保留模型的效果
python llama.cpp/convert_hf_to_gguf.py ./qwen2_0.5b_instruct --outtype f16 --verbose --outfile qwen2_0.5b_instruct_f16.gguf
# 如果需要量化(加速并有损效果),直接执行下面脚本就可以
python llama.cpp/convert_hf_to_gguf.py ./qwen2_0.5b_instruct --outtype q8_0 --verbose --outfile qwen2_0.5b_instruct_q8_0.gguf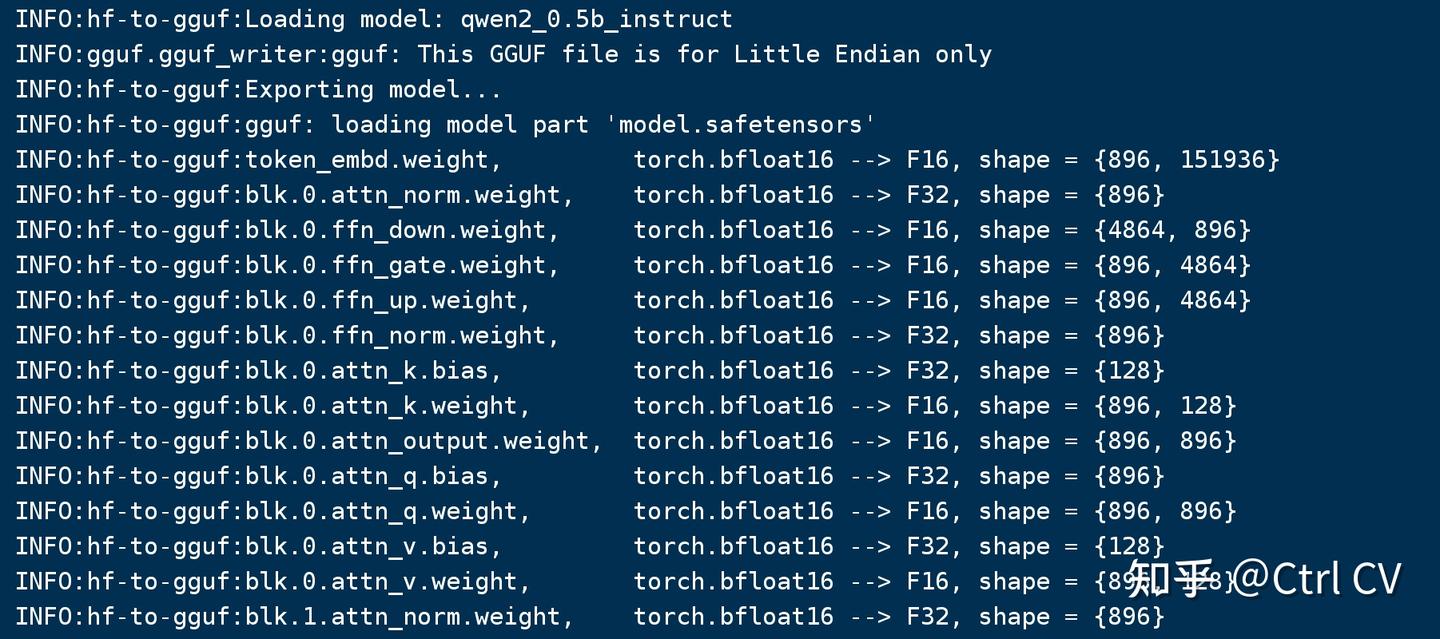
转换后模型如下:

这里--outtype是输出类型,代表含义:
q2_k:特定张量(Tensor)采用较高的精度设置,而其他的则保持基础级别。
q3_k_l、q3_k_m、q3_k_s:这些变体在不同张量上使用不同级别的精度,从而达到性能和效率的平衡。
q4_0:这是最初的量化方案,使用 4 位精度。
q4_1 和 q4_k_m、q4_k_s:这些提供了不同程度的准确性和推理速度,适合需要平衡资源使用的场景。
q5_0、q5_1、q5_k_m、q5_k_s:这些版本在保证更高准确度的同时,会使用更多的资源并且推理速度较慢。
q6_k 和 q8_0:这些提供了最高的精度,但是因为高资源消耗和慢速度,可能不适合所有用户。
fp16 和 f32: 不量化,保留原始精度。3、使用ollama运行gguf
转换好的 GGUF 模型可以使用以下的工具来运行:
ollama(推荐): 简化 AI 模型的本地部署与使用
llama.cpp:GGUF 的源项目。提供 CLI 和 Server 选项。
text-generation-webui:最广泛使用的网络界面,具有许多功能和强大的扩展。支持 GPU 加速。
GPT4All:一个免费且开源的本地运行图形用户界面,支持 Windows、Linux 和 macOS,并支持 GPU 加速。
LM Studio:一个易于使用且功能强大的本地图形用户界面,适用于 Windows 和 macOS(Silicon),支持 GPU 加速。
llama-cpp-python:支持 GPU 加速、LangChain 和 OpenAI 兼容 API 服务器的 Python 库。
candle:一个使用 Rust 编写的机器学习框架,具有 GPU 支持和易于使用的特点,适合追求性能的开发者。
可以使用ollama Modelfile,基于gguf模型文件快速部署并运行模型。
1)安装ollama
curl -fsSL https://ollama.com/install.sh | sh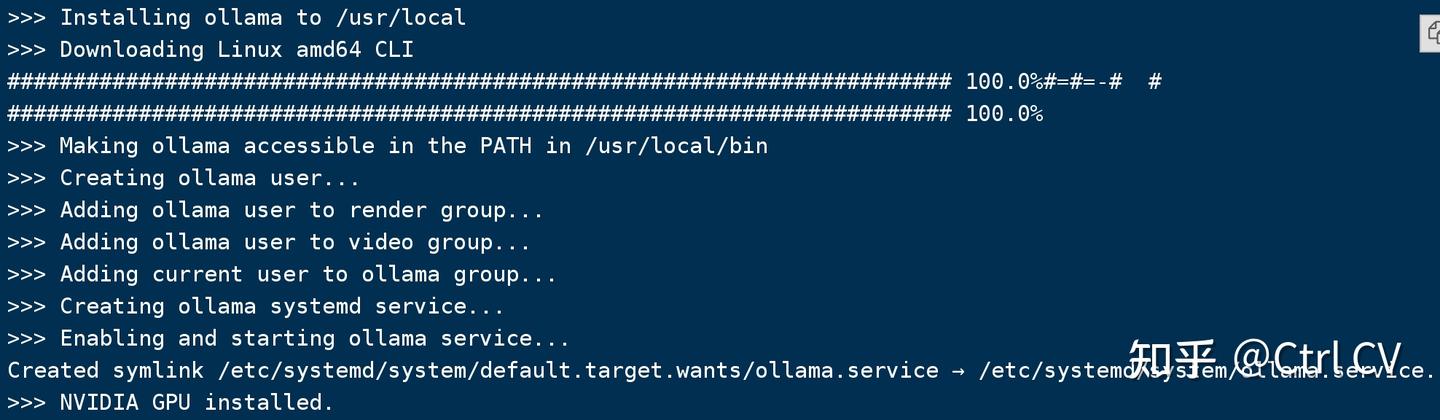
2)启动ollama服务
nohup ollama serve &3)创建ModelFile
复制模型路径,创建名为“ModelFile”的meta文件,内容如下
FROM ./qwen2-0.5b-instruct-q8_0.gguf
# set the temperature to 0.7 [higher is more creative, lower is more coherent]
PARAMETER temperature 0.7
PARAMETER top_p 0.8
PARAMETER repeat_penalty 1.05
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
{{ .Response }}<|im_end|>"""
# set the system message
SYSTEM """
You are a helpful assistant.
"""4)创建自定义模型
使用ollama create命令创建自定义模型
ollama create qwen2_0.5b_instruct --file ./ModelFile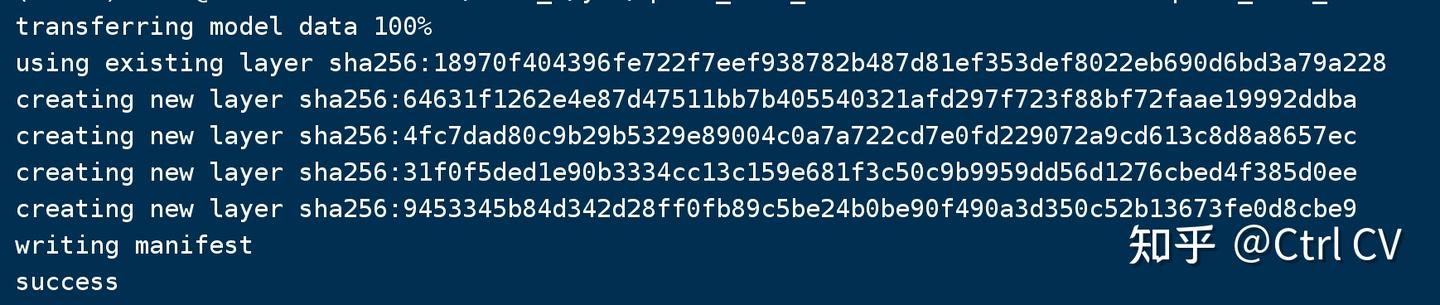
5)运行模型:
ollama run qwen2_0.5b_instruct 6)对于大文件,由于文件上传的限制,我们将其拆分为多个部分。它们共享一个前缀,后缀表示其索引。例如
qwq-32b-q5_k_m-00001-of-00006.gguf, qwq-32b-q5_k_m-00002-of-00006.gguf, ... and qwq-32b-q5_k_m-00006-of-00006.gguf
(可选)合并:对于分割文件,您需要先使用命令llama gguf split将其合并,如下所示:
# ./llama-gguf-split --merge <first-split-file-path> <merged-file-path>
./llama-gguf-split --merge qwq-32b-q5_k_m-00001-of-00006.gguf qwq-32b-q5_k_m.gguf

















 4569
4569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









