







随机搜索
我们试图用不同的迭代方法来优化w,这其中我们想到最笨的方法就是随机搜索。
你需要很多权重值,随机采样,然后将他们输入损失函数。看看它们的效果如何,这绝对是个很烂的算法,我们可以通过随机搜索训练一个线性分类器。

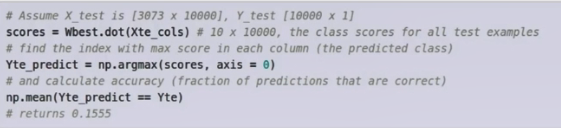
对CIFAR-10有10个类别,所以随机概率就是10%,在全凭运气情况下,通过几次随机实验,会通过W值的设定,使精确地达到15%,好于随机概率但离95%的最高精确度还有很大距离
梯度下降法

有限差分(数值梯度)
如果你想知道一个地形任意方向的斜率,它就等于这一点上的梯度和该店单位方向向量的点积,所以梯度很重要,因为给出了函数在当前点的一阶线性逼近,所以很多深度学习都是计算梯度,用这些梯度迭代,更新你的参数向量。
在计算机上计算梯度一个简单的方法,是有限差分法。

上图中对每个w分别加一个很小的量,来计算出梯度。这是一种方法,但是运算非常满也不是一种好的算法,如果这个深度神经网络非常大,这个函数f会很慢。需要改良方法。
解析梯度

在这里可以直接写出梯度的表达式,比起有限差分法,进行计算分析将更有效率,首先效率更高,第二只需要计算一个表达式所以很快

总结

总结来说也许并不会使用数值梯度,但它简单有意义,实际上总是在使用解析梯度,然而有趣的是数值梯度却很有用的调试工具。当你已经写了一部分代码,在写一部分来计算损失和梯度的损失,你怎么来验证你写入代码的解析表达式是正确的,正常的方法就是使用数值梯度。
当你使用数值梯度时,这个过程很缓慢且不精确。你需要减少参数量来保证在有效时间内。
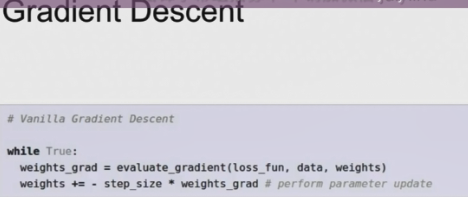
首先我们初始话w为随机值,当为真时,我们计算损失和梯度。然后向梯度想反的方向更新权重值。要记住,梯度指向函数的最大增加方向,而梯度减小则指向函数最大减小的方向。
步长(学习率)
所以我们一直想函数减小方向最后网络就会收敛。但是步长是一个超参数,这就告诉我们每次计算梯度时候,向那个方向前进多少,这个步长也被叫做学习率,这是最终要需要设定的值。
学习率是我要检查的第一个超参数,其他比如模型大小,需要多少正则化,我会晚点做,找到合适的学习率是我们首先要做的事情。

这是一张2维示意图,表示我们误差函数,中心的红色区域表示误差较低是我们需要的,绿蓝区域表示误差较大,是我们要避免的。
所以这里以图中一点来计算梯度的反方向。我们希望它将指向最终的最小值。如果重复这个过程,我们会达到最小值

由于有些数据集数比较多,这会使运算减慢,单次更新w时间比较长,这里可以取随机的小批分批训练。这些数据都是2的次方
所以就是为真时,随机取一些minibatch数据,评估minibatch的误差值和梯度,然后更新各个参数,基于这一误差以及梯度的估计。
图像的特征
直接输入原始像素值,传递给线性分类器,效果并不好,当深度神经网络大规模运用前,常用方式就是两步走。
计算图片各种特征代表,计算与图片形象相关的数值,将不同特征结合一起得到图像的特征表述,这一输入会作为输入源传入线性分类器中而不是元素像素。

这样做的动机是想象我们有一个训练数据集如左侧所示,红点分布在中间,蓝点分布在周围,对这种方式我们不能用一个线性的决策边界。如果我们用一个灵活的特征转换,在这个例子中我们用了极坐标的转换,我们得到转换特征,就可以把复杂的数据集变成线性可分的。然后由线性分类器,正确分类。
转换极坐标也许对图像分类没什么有用的意义,但是可以记下一些有用的转换特征。
颜色直方图

获取每个像素值,对应的光谱,把它分类到柱状里,将每一个像素,然后计算每个柱状里像素出现的频次。从全局告诉哦我们呢图像中有那些颜色。
比如这里这只青蛙告诉我们许多绿色的分量。
你可以在实践中发现这些简单的分量
另一个特征表示是词袋















 1026
1026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









