









1、map unordered_map unordered_set
map<int, int> map; // 可以按照Key 的大小排序,并且 是可以重复的key ----底层是红黑树 O(logN)
unordered_map <int, int> um; //不能有重复的key 并未是没有排序的 但是查找的时间可以达到O(1)的时间复杂度,因为底层是一个哈希桶
#include <iostream>
#include <map>
#include <unordered_map>
#include <unordered_set>
using namespace std;
int main()
{
map<int, int> map; // 可以按照Key 的大小排序,并且 是可以重复的key ----底层是红黑树 O(logN)
map.insert(make_pair(1,2));
map.insert(make_pair(6, 20));
map.insert(make_pair(7, 16));
map.insert(make_pair(5, 20));
map.insert(make_pair(2, 7));
map.insert(make_pair(7, 1));
for (auto e : map)
cout << " map :" << e.first << " , " << e.second << endl;
// map set multi_map multi_set 都是中序遍历 , O(logN)
unordered_map <int, int> um; //不能有重复的key 并未是没有排序的 但是查找的时间可以达到O(1)的时间复杂度,因为底层是一个哈希桶
um.insert(make_pair(1, 2));
um.insert(make_pair(6, 20));
um.insert(make_pair(7, 16));
um.insert(make_pair(5, 20));
um.insert(make_pair(2, 7));
um.insert(make_pair(7, 1));
um.insert(make_pair(2, 17));
um.insert(make_pair(2, 57));
um.insert(make_pair(2, 77));
for (auto e : um)
cout << "unordered_map : " << e.first << " , " << e.second << endl;
unordered_set <int> us;
us.insert(10);
us.insert(50);
unordered_set <int>::iterator it = us.begin();
while (it != us.end())
{
cout << "++++unordered_set+++++++ " <<*it <<endl;
++it;
}
return 0;
}二、哈希函数
例如:数据集合{1,7,6,4,5,9};
哈希函数设置为:hash(key) = key % capacity; capacity为存储元素底层空间大小,这里设置为10
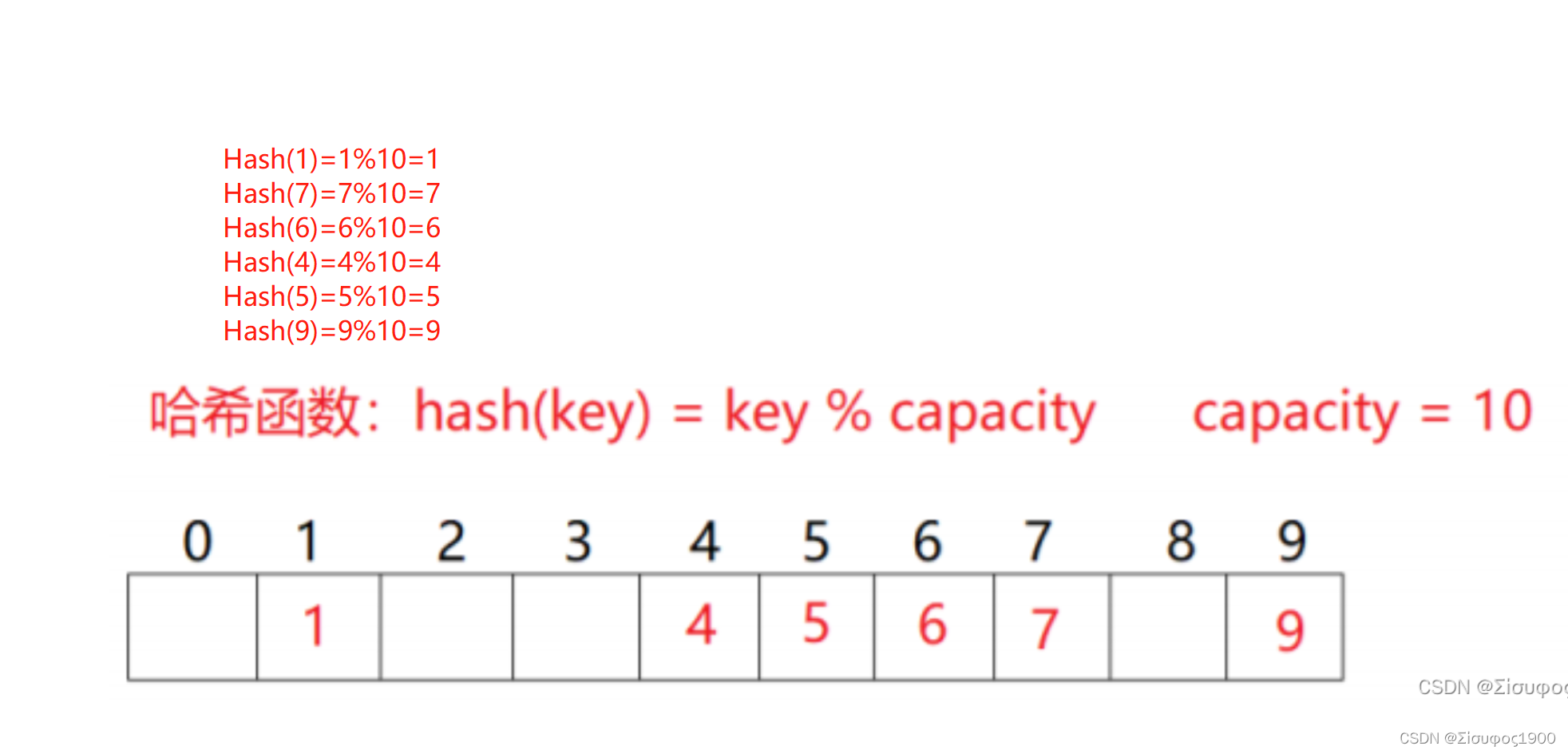
哈希冲突:
若上面再来一个数据44,那么依据上面的计算就是错误的,4 的那个位置有两个值,这种情况就是hash 冲突。不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。哈希冲突的解决可以分为两大类,闭散列和开散列
闭散列:开发地址法
当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。那如何寻找下一个空位置呢?
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。

那么这种情况下就可能发生两种操作,第一便是查找,第二便是删除:
查找的话就是1 通过hash 函数计算的方法计算出是在那个索引下面,
2 判断这个索引的值和要查找的是不是一样,如果不一样就依次向后面找
2 二次探测 Hi=(H0+i^2)%m m 是表的大小,H0是第一次计算得到的哈希值, i= 123....
三、开放地址法解决哈希冲突
#include <iostream>
#include <map>
#include <unordered_map>
#include <vector>
#include<string.h>
using namespace std;
enum Status // 表示hash 表的状态
{
EMPTY,
EXIST,
DELETE
};
template<class K,class V >
struct DataNode
{
public :
pair<K, V> _kv = pair<K, V>();
Status status= EMPTY;
};
template<class K, class V >
class MyHashTable
{
public:
typedef struct DataNode<K, V> HashNode;
MyHashTable(size_t n = 5) :h_size(0)
{
hv_Node.resize(n);
}
void CheckCapacity()
{
if (hv_Node.size() == 0|| h_size*10/ hv_Node.size()>=7)
{
// 开始扩容
h_size = hv_Node.size() == 0 ? 5 : 2 * hv_Node.size();
MyHashTable<K,V> newV_Node(h_size);
//将扩容之前的数据全都复制到这个新的容器里面
for (int i = 0; i < hv_Node.size(); i++) {
if (hv_Node[i].status == EXIST)
{
newV_Node.insert(hv_Node[i]._kv);
}
}
swap(hv_Node, newV_Node.hv_Node);
}
}
// 插入数据
bool insert(const pair<K,V> &kv)
{
// 检测容量
CheckCapacity();
// 利用哈希函数进行位置的计算,这里用的就是除留余数发
int index = kv.first % hv_Node.size();
while (hv_Node[index].status==EXIST) // 如果index 这个位置已经有值了
{
// 主要是看index的位置是不是和要即将插入的K相同
if (hv_Node[index].status==EXIST&& hv_Node[index]._kv.first==kv.first) {
return false;
++index;
if (index == hv_Node.size())
{
index = 0;
}
}
}
// 进过上面的循环没有找到形同的K
hv_Node[index]._kv = kv;
hv_Node[index].status = EXIST;
++h_size;
return true;
}
HashNode* FindByK(const K &key)
{
//先利用哈希函数进行位置计算出key的位置
int index = key % hv_Node.size();
while (hv_Node[index].status != EMPTY) // 如果index 这个位置已经有值了
{
// 主要是看index的位置是不是和要即将插入的K相同
if (hv_Node[index].status == EXIST && hv_Node[index]._kv.first == key)
{
return &hv_Node[index];
++index;
if (index == hv_Node.size())
{
index = 0;
}
}
}
return NULL;
}
bool erase(const K& key)
{
HashNode* cur = find(key);
if (cur)
{
//删除 只修改状态
cur->status = DELETE;
--h_size;
return true;
}
return false;
}
HashNode* operator [](const K& key)
{
return FindByK(key);
}
vector<HashNode> hv_Node; //数据容器
size_t h_size; // 表的大小
};
#if 1
int main()
{
MyHashTable<int,string> hashmap = MyHashTable<int, string>();
pair<int, string> p1,p2,p3,p4,p5,p6;
p1.first = 1;
p1.second = "aaaa";
p2.first = 2;
p2.second = "bbbb";
p3.first = 3;
p3.second = "ccc";
p4.first = 4;
p4.second = "dd";
p5.first = 5;
p5.second = "eee";
p6.first = 6;
p6.second = "fff";
hashmap.insert(p1);
hashmap.insert(p2);
hashmap.insert(p3);
hashmap.insert(p4);
hashmap.insert(p5);
hashmap.insert(p6);
//hashmap[2];
//const pair<K,V> &kv
//for(auto e: hashmap)
cout << "MyHashTable [] : " << hashmap[2]->_kv.first << ", " << hashmap[2]->_kv.second << endl;
cout << "MyHashTable : "<< hashmap.FindByK(3)->_kv.second << ", " << hashmap.FindByK(6)->_kv.second << endl;
return 0;
}
#endif // 0













 442
442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









