





声明:
1. 简单总结一下人脸识别的发展历史,如有侵权请联系本人删除文章,谢谢!
2. 如转载请注明出处,谢谢。
背景
自上世纪七十年代开始,人脸识别就已经成为计算机视觉和生物特征识别技术中研究最热门的方向之一。 到目前为止,人脸识别面临诸多技术挑战,比如人头部姿态变化,跨年龄人面部变化,光照变化,表情变化,人脸被遮挡等(如下图,参考文献[1])。

人脸识别系统
输入1张包含人脸的图像,通常人脸识别系统包含如下几大模块:
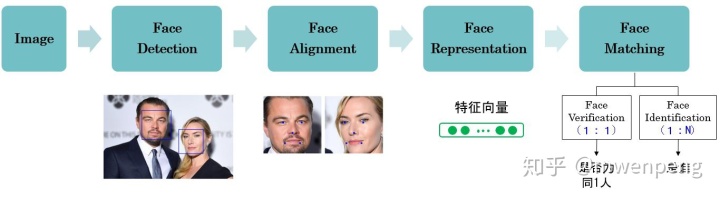
(1)人脸检测(Face Detection)
从图像中找到人脸并返回人脸包围框坐标(bounding box,或bbox)。
(2)人脸对齐或称人脸配准(Face Alignment)
检测人脸特征点,并据此进行仿射变换,对人脸进行尺度和角度的归一化。近年的技术可以这一步将人脸正面化。
(3)人脸表征(Face Representation)
从人脸图像像素中计算提取人脸紧凑且具鉴别性的特征向量,理想的特征是能够从同一个体的人脸不同图像中提取相似的特征向量。
(4)人脸匹配(Face Matching)
将两幅图像的特征向量进行比较,得到相似分数,用于表示这两幅人脸图像属于同一个人的似然性。总体来说,主要有两个应用场景:人脸验证(Face Verification)和人脸识别(Face Identification)(如下图,参考文献[2])。
-人脸验证(Face Verification),做的是1:1的比对,其身份验证模式本质上是计算机对当前人脸与人像数据库进行快速人脸比对,并得出是否匹配的过程,可以简单理解为证明你就是你。就是我们先告诉人脸识别系统,我是张三,然后用来验证站在机器面前的“我”到底是不是张三。
-人脸识别(Face Identification),做的是1:N的比对,即系统采集了“我”的一张照片之后,从海量的人像数据库中找到与当前使用者人脸数据相符合的图像,并进行匹配,找出来“我是谁”。
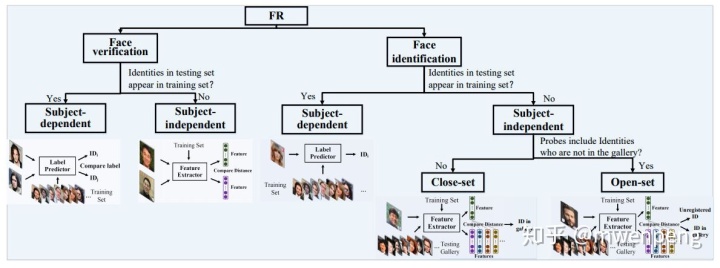
根据test face是否一定在training dataset中。如果是,则称作subject-dependent;否则,称作subject-independent。subject-dependent 一般用于“明星检测”中,像手机中的人脸识别是subject-independent。在实际应用场景中,如果需要识别的face是在总的gallery中的,则是close-set;否则,就是open-set。
人脸特征提取
基于人工设计的特征和传统的机器学习技术的传统方法目前已经被使用大规模数据集训练的深度神经网络所取代。简单概述一下传统方法(基于几何,基于整体,基于特征和混合方法)和深度学习方法。
(1)基于几何的方法(Geometry-based Methods)
早期的人脸识别方法使用特定的边缘和轮廓检测找到人脸特征点,并据此计算特征点之间相互位置和距离,用来衡量两幅人脸图像的相似程度。
这些方法往往在极少个体(10-20个人)的人脸数据库中进行实验,但在早期使得计算机来识别人脸称为可能。
(2)基于整体的方法(Holistic Methods)
这类方法对图像整体进行投影操作提取特征。包括我们熟悉的主分量分析(PCA)、线性鉴别分析(LDA),通过寻找一组投影向量将人脸图像降维,再将低维特征送入类似SVM等机器学习分类器进行人脸分类。
局部保持投影(LPP)是这个方向另一个重要算法,实践证明LPP往往优于PCA、LDA。这个方向还有一项重要工作是图像稀疏表示(sparse representation),及由此衍生的稀疏表示分类器,以重建误差最小衡量分类结果。以LFW数据集(Labeled Faces in the Wild)评估为衡量标准,这一类基于整体变换的方法中,取得最高精度的是joint Bayesian方法,达到92.4%的精度。
(3)基于特征的方法(Feature-based Methods)
在人脸图像中的不同位置提取局部特征的方法,这种方法往往比基于整体的方法更具鲁棒性。较早的基于特征的方法比如模块特征脸(modular eigenfaces),还有类似在图像块中提取HOG、LBP、SIFT、SURF特征(这些特征更具鉴别性),将各模块局部特征的向量串联,作为人脸表示。
(4)混合方法(Hybrid Methods)
先使用基于特征的方法(比如LBP、SIFT)提取局部特征,再使用子空间方法(比如PCA、LDA)投影获取低维、鉴别特征,将基于整体和基于特征的方法相结合的方法。这一类方法中有不少基于Gabor+子空间方法。大量文献中LBP特征是这一类方法中重要的局部特征。
由于此处文献很多,基本涉及到使用不同的分块方法、使用不同的局部特征(Gabor、LBP、SIFT、LTP、LPQ等)、使用不同的子空间方法(PCA、LDA、MFDA、Laplacian PCA、Kernel PCA、kernel LDA等)的不同排列组合。
在这一类方法中,GaussianFace在LFW上获得了最好的精度98.52%,几乎匹敌很多后来出现的深度学习方法。
(5)基于深度学习的方法(Deep Learning Methods)
深度学习尤其是深度卷积神经网络方法最大的优势是可以从数据集中学习特征,如果数据集能够覆盖人脸识别中常遇到的各种情况,则系统能够自动学习克服各种挑战的特征。在早期的神经网络研究中也有用于人脸识别的报道,但由于数据集不够大,网络不够深,效果也一般,没能吸引大家的注意力。
在CNN改进人脸识别的文献中,DeepFace和DeepID是先驱,成功吸引众多学者研究该方向。DeepFace的出现将LFW上state-of-the-art人脸识别方法误差降低了27%!
深度学习
深度学习成功用于人脸识别的三大要素:大规模数据集、先进的网络架构、有针对性的损失函数。
- 大规模数据集
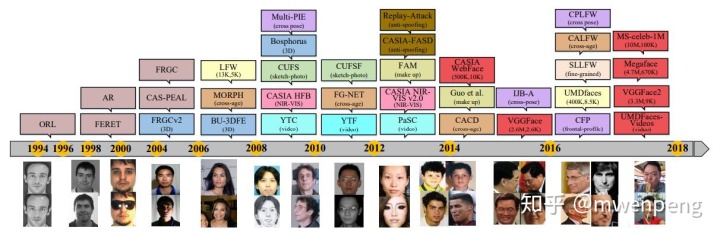
业界陆续建立公开了可供深度学习训练的多个大规模数据集(如下图,参考文献[2])。下图为数据集的演变过程。 在2007年之前,早期的数据集偏向受控的和小型的。2007年,随着LFW数据集的公开,标志着人脸数据开始包含了不受限制的条件下获取的face。从那时起,设计了更多具有不同任务和场景的测试数据库。2014年,CASIA-Webface提供了第一个广泛使用的公共训练数据集,大规模训练用的数据集开始成为热门话题。红色矩形代表训练数据集,其他颜色矩形代表具有不同任务和场景的测试数据集。
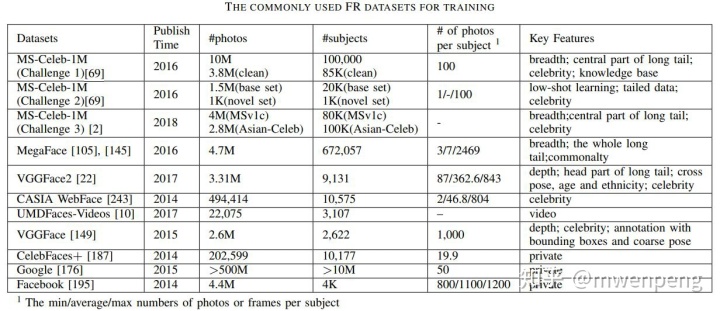
下表是一些具有代表性的训练用的人脸识别数据集(参考文献[2])。
需要注意的是,每个数据集都含有Noise(噪声)。一般来说,数据集所包含的图像数越多,Noise也就越多,训练时对性能(精度)的影响也就越大(如下图,参考文献[3])。所以,如何构建一个去噪且大规模的数据集对人脸识别的研究和发展都是非常有意义的。
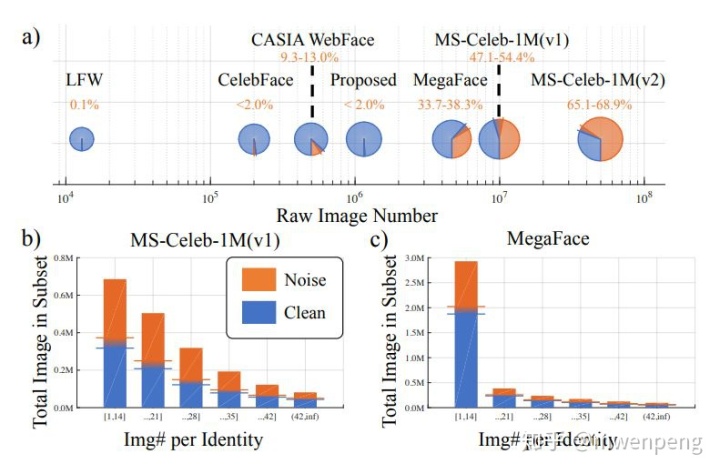
关于数据集的【量】,这个有一个讨论:
Are deeper datasets better than wider datasets?
就结果来说,wider更好。有兴趣的可以看看参考文献[4]
- 先进的网络架构
在深度人脸识别中使用的网络结构基本都和深度目标分类一样,都是从alexnet发展到senet。我们这里按照最具影响力的结构发展来介绍,如下图(参考文献[2])。

在2012年,Alexnet在Imagenet上获得了最好的结果,超过第二名一大截。Alexnet包含了5层卷积层和三层全连接层,他同时整合了多种技术,如ReLU,dropout,数据增强等等。然后在2014年,VGGNet被提出,其中包含非常小的卷积过滤器(3x3),和在每次2x2池化之后,将通道数进行加倍。它成功的让CNN的深度提升到了16-19层,其网络结果表明了通过深度结构学习非线性映射的灵活性。在2015年,22层的GoogleNet引入一个"inception模块"。在2016年ResNet横空出世。
受到目标分类中的进展影响,深度人脸识别也追寻着这些主流结构的使用。在2014年,DeepFace是第一个采用了7层局部连接层的一个9层CNN。通过对数据进行三维对齐,它在LFW上获得了97.35%的准确度。在2015年,FaceNet使用一个私有的人脸数据集去训练Googlenet,通过一个新颖的在线triplet挖掘方式生成许多人脸块,然后在对齐的匹配/不匹配人脸块三元组上使用triplet loss函数,获得了99.63%的准确度。同年VGGface也公开了一个人脸数据集,在该数据集上训练的VGGNet然后通过类似FaceNet的triplet loss进行微调,在LFW上获得了98.95%的结果。在2017年,SphereFace使用一个64层的Resnet结构,并提出了angular softmax(A-softmax) loss,通过使用角边际学到了判别性人脸表征,将结果提升到了99.42%。在2017年底,出现了一个新的人脸数据集,VGGface2,其包含了在姿态,年龄,光照,种族,职业都有很大的变化。Cao首次用SEnet在Ms-celeb-1M数据集上进行训练,然后用VGGFace2进行微调,在IJB-A,IJB-B上获得了最好的效果。
- 损失函数
从目标分类网络发展至今,如Alexnet,最开始的FR网络如Deepface和DeepID都是采用基于softmax loss的交叉时进行特征学习的。然后人们发现softmax不足以去学习有大边际的特征,所以更多的研究者开始利用判别性损失函数去增强泛化能力。这也变成了深度人脸识研究中最火热的研究点,如下图(参考文献[2])。
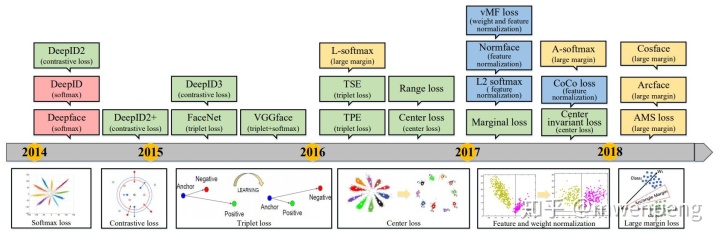
(2018年以后,出现了如AdaM等等新的损失函数的论文,有兴趣的可以自己看看)
在2017年之前,基于欧式距离的损失函数占据主流。在2017年,角/余弦边际的损失函数,特征与权重归一化这两个开始流行。虽然许多损失函数的基本思想差不多,不过最新的损失函数都是设计成采用更容易的参数或者采样方法去方便训练。简单概述一下其中几个比较有代表性的。
(1)DeepFace
DeepFace是FaceBook在CVPR2014时提出来的,后续有DeepID和FaceNet出现。而且在DeepID和FaceNet中都能体现DeepFace的身影,所以DeepFace可以谓之CNN在人脸识别的奠基之作,目前深度学习在人脸识别中也取得了非常好的效果。

为了进行分段的仿射变换,使用了3D的人脸建模来重现人脸对齐和人脸表征这两步,最终从一个9层的深度神经网络中得到了人脸的特征(如上图,参考文献[5])。这个网络并非标准的卷积网络层,而是使用了几个未共享权重的局部连接层,网络参数超过了120,000,000个。在当时为止最大的人脸数据库上训练,4030个不同的人,总计440万张带标记的人脸库。这种在大型数据库中基于模型进行准确的对齐并用神经网络训练学习到的人脸表达,可以很好地推广到非受限环境下的人脸表达。该方法在LFW上达到了97.35%的人脸验证精度,逼近了人类的水平。
(2)Facenet
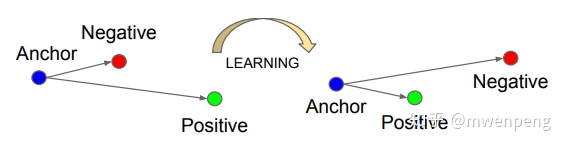
FaceNet是Google于CVPR2015年发表的,使用深度卷积网络进行人脸识别,该方法中最重要的部分在于整个系统的端到端学习。为此,论文中采用三元组损失(Triplet Loss)/三重损失,直接反映了作者想要在面部验证,识别和聚类中实现的目标。使得相同身份的所有面部之间的平方距离(与成像条件无关)很小,而来自不同身份的一对面部图像之间的平方距离很大。三元组损失的思想也很简单,输入是三张图片(Triplet),分别为 固定影像 A(Anchor Face),反例图像 N(Negative Face )和 正例图像 P(Positive Face)。A与 P为同一人,与 N 为不同人(如下图,参考文献[6])。
(3)Arcface
ArcFace的思想(additive angular margin)和SphereFace以及CosineFace(additive cosine margin )有一定的共同点,重点在于:在ArchFace中是直接在角度空间(angular space)中最大化分类界限,而CosineFace是在余弦空间中最大化分类界限,。除了损失函数外,本文的作者还清洗了公开数据集MS-Celeb-1M的数据,并强调了干净数据的对实验结果的影响,同时还对网络结构和参数做了优化。有兴趣的可以自己看看。
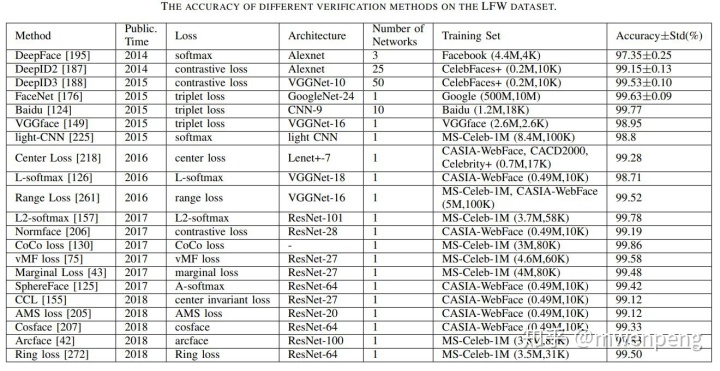
最后,下表(参考文献[2])总结了一下到2019年为止主要的损失函数。
课题
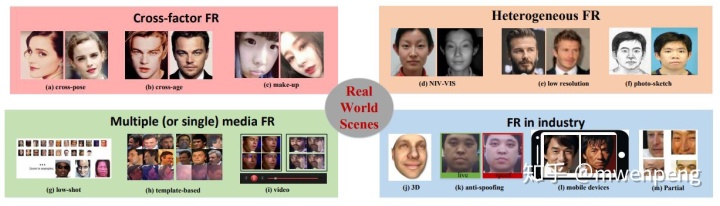
目前,人脸识别在复杂场景下还有很多课题需要解决,如下图(参考文献[2])。比如,交叉姿势、交叉年龄、化妆人脸、不同的光源、低分辨率、素描人脸识别、比如监视、训练集只有很少人、数据来源于不同的媒介、视频人脸识别等。
参考文献:
[1] Face Recognition: From Traditional to Deep Learning Methods
[2] Deep Face Recognition: A Survey
[3] The devil of face recognition is in the noise
[4] The do’s and don’ts for cnn-based face verification
[5] DeepFace: Closing the Gap to Human-Level Performance in Face Verification
[6] FaceNet: A Unified Embedding for Face Recognition and Clustering
[7] https://qiita.com/yu4u/items/078054dfb5592cbb80cc















 2101
2101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









