







FINN 端到端流
在这本文中,我们将讨论如何使用一个简单的、二进制的、完全连接的、在MNIST数据集上训练的网络,并将它一直使用到一个在PYNQ板上运行的定制位文件。
概述
FINN编译器附带了许多转换,这些转换根据特定模式修改网络的ONNX表示。本文将演示一系列可能的转换,以将特定的经过培训的网络一直带到硬件,如下图所示。
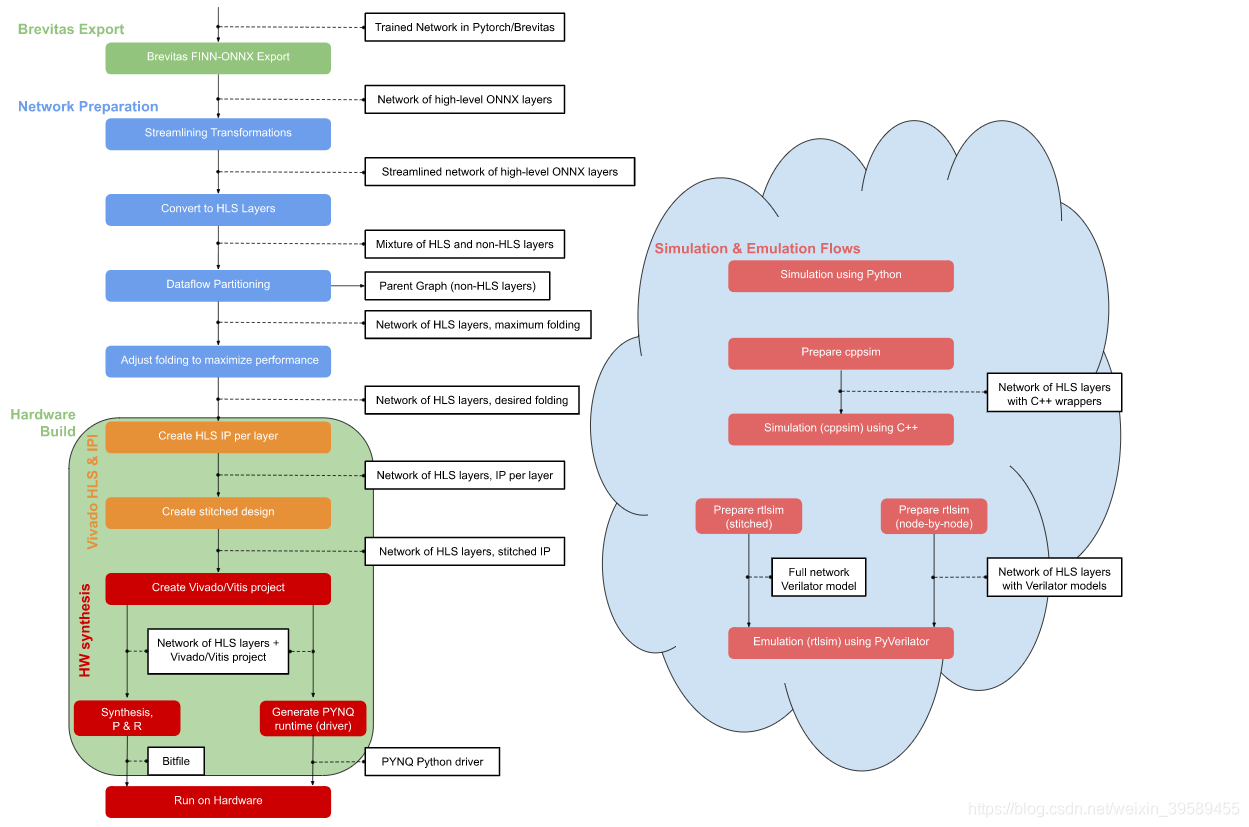
白色字段显示相应步骤中网络表示的状态。
彩色字段表示应用于网络以获得特定结果的变换。
该图分为5个部分,用不同的颜色表示,每个部分包括几个流程步骤。
流程从左上角的Brevitas export(绿色部分)开始,然后准备网络(蓝色部分)进行Vivado HLS合成和Vivado IPI缝合(橙色部分),最后构建一个PYNQ覆盖位文件并在PYNQ板上进行测试(黄色部分)。
在图的右侧有一个额外的功能验证部分(红色部分),我们将不在本文中介绍。有关详细信息,请查看官方文档。
本文是根据上述章节组织的。我们将使用以下帮助函数,showSrc显示FINN库调用的源代码,showInNetron显示当前转换步骤中的ONNX模型。Netron显示器是交互式的,但它们仅在主动运行笔记本而不是在GitHub上运行时才起作用(即,如果您在GitHub上查看,则只会看到空白的方块)。
from finn.util.visualization import showSrc, showInNetron
from finn.util.basic import make_build_dir
build_dir = "/workspace/finn"
纲要
1 Brevitas输出
FINN期望ONNX模型作为输入。这可以是用Brevitas训练的模型。Brevitas是一个用于量化感知训练的PyTorch库,FINN Docker图像附带了几个Brevitas网络示例。为了显示FINN端到端的流,我们将使用TFC-w1a1模型作为示例网络。
首先要import一些东西。然后将预训练好的权重加载到模型中。
import onnx
from finn.util.test import get_test_model_trained
import brevitas.onnx as bo
tfc = get_test_model_trained("TFC", 1, 1)
bo.export_finn_onnx(tfc, (1, 1, 28, 28), build_dir+"/tfc_w1_a1.onnx")
该模型现在被导出,加载了预先训练好的权重,并以"lfc_w1_a1.onnx"的名称保存。为了可视化导出的模型,可以使用Netron。Netron是神经网络的可视化工具,允许对网络特性进行交互式研究。例如,可以单击各个节点并查看属性。
showInNetron(build_dir+"/tfc_w1_a1.onnx")
服务“/workspace/finn/tfc_w1_a1.onnx”http://0.0.0.0:8081
OUT from netron
现在我们有了.onnx格式的模型,我们可以使用FINN来处理它。因为使用了FINN ModelWrapper。它是一个围绕ONNX模型的包装器,它提供了几个helper函数,使得使用模型更容易。
from finn.core.modelwrapper import ModelWrapper
model = ModelWrapper(build_dir+"/tfc_w1_a1.onnx")
现在模型已经准备好了,可以用Python进行模拟。
现在也可以用不同的方式处理模型。FINN的基本原理是分析和变换过程,可以应用到模型中。分析过程提取有关模型的特定信息,并将其以dictionary的形式返回给用户。转换过程更改模型并将更改后的模型返回到FINN流。
由于本笔记本中的目标是将模型处理到可以从中生成位流的程度,因此重点是为此所需的转换。下一节将更详细地讨论这些问题。
2 网络准备
在本节中,我们将对网络进行一系列的转换,将其转换为可缝合在一起的形式,以形成FINN样式的数据流体系结构,从而产生高性能,高效率的FPGA加速器。
2.1 FINN风格的数据流架构
我们首先简要回顾一下FINN风格的数据流体系结构。这种体系结构的关键思想是通过为每一层分配成比例的计算资源来实现跨层和层内的并行化,如以下摘自FINN-R论文的图所示:
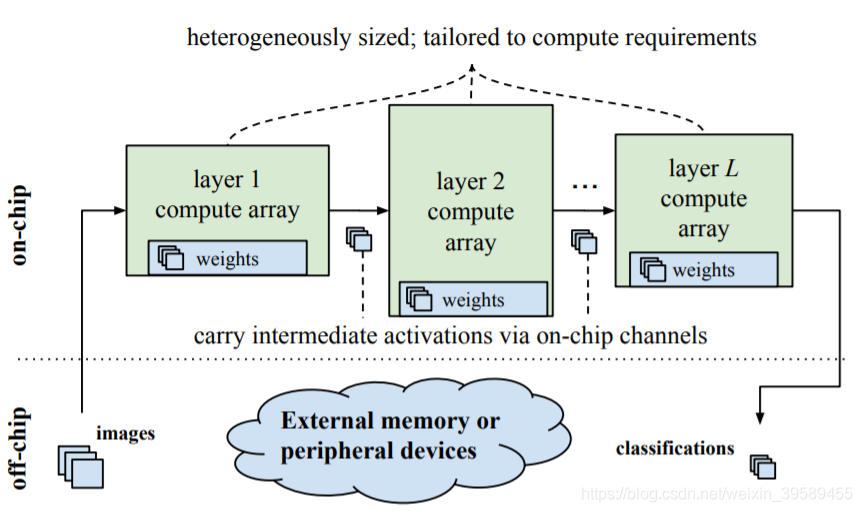
实际上,计算数组是通过函数调用finn-hlslib库中优化的Vivado HLS构建块来实例化的。由于这些函数调用只能处理某些模式/情况,因此我们需要将网络转换为适当的形式,以便用这些函数调用替换网络层,这是网络准备过程的目标。
2.2 整理转换
本节讨论一些基本的转换,这些转换像“整理”一样应用于模型,以使其更易于处理。它们没有出现在上图中,但是它们在FINN流中的许多步骤中被应用,以便在转换之后对模型进行后处理和/或为下一次转换做准备。
这些转换是:
- GiveUniqueNodeNames
- GiveReadableTensorNames
- InferShapes
- InferDataTypes
- FoldConstants
- RemoveStaticGraphInputs
在前两个转换(GiveUniqueNodeNames、GiveReadableTensorNames)中,首先为图中的节点指定唯一(通过枚举)名称,然后为张量指定人类可读的名称(基于节点名称)。以下两个转换(InferShapes、InferDataTypes)从模型属性派生出张量的形状和数据类型,并在模型的ValueInfo中设置它们。这些转换几乎总是可以在没有负面影响的情况下应用,并且不会影响图形的结构,从而确保所需的所有信息都可用。
下一个列出的转换是FoldConstants,它执行常量折叠。它用常量输入标识节点并确定其输出。然后将结果设置为仅用于以下节点的常量输入,并删除旧节点。尽管这种转换改变了模型的结构,但它是一种通常需要的转换,可以应用于任何模型。最后,我们有RemoveStaticGraphInputs来移除任何已经有ONNX初始化器关联的顶级图形输入。
这些转换可以按如下方式导入和应用。
from finn.transformation.general import GiveReadableTensorNames, GiveUniqueNodeNames, RemoveStaticGraphInputs
from finn.transformation.infer_shapes import InferShapes
from finn.transformation.infer_datatypes import InferDataTypes
from finn.transformation.fold_constants import FoldConstants
model = model.transform(InferShapes())
model = model.transform(FoldConstants())
model = model.transform(GiveUniqueNodeNames())
model = model.transform(GiveReadableTensorNames())
model = model.transform(InferDataTypes())
model = model.transform(RemoveStaticGraphInputs())
model.save(build_dir+"/tfc_w1_a1_tidy.onnx")
再次保存模型后,可以使用netron查看这些转换的结果。通过单击各个节点,现在可以看到,例如,每个节点都有一个名称。整个上部区域也可以折叠,这样第一个节点就是“重塑”。
showInNetron(build_dir+"/tfc_w1_a1_tidy.onnx")
2.3 添加预处理和后处理
在许多情况下,在训练之前对机器学习框架中的原始数据进行一些预处理是很常见的。对于图像分类网络,这可能包括将原始8位RGB值转换为0到1之间的浮点值。类似地,在网络的输出处,可以在部署期间执行一些后处理,例如提取具有最大值的分类的索引(top-K索引)。
在FINN中,我们可以将一些预处理/后处理操作拷到图形中,在某些情况下,这些操作可以通过允许加速器直接使用原始数据而不是经过CPU预处理来非常有利于提高性能。
我们将在下面的小型图像分类网络中演示这一点。Brevitas使用torchvision.transforms.ToTensor() 在训练之前,通过将输入除以255,将8位RGB值转换为介于0和1之间的浮点值。在FINN中,我们可以通过导出一个单节点ONNX图以除以255(它已经作为finn.util.pytorch公司.ToTensor并将其与原始模型合并。最后,我们将把输入张量标记为8位,让FINN知道要使用哪一级的精度。
from finn.util.pytorch import ToTensor
from finn.transformation.merge_onnx_models import MergeONNXModels
from finn.core.datatype import DataType
model = ModelWrapper(build_dir+"/tfc_w1_a1_tidy.onnx")
global_inp_name = model.graph.input[0].name
ishape = model.get_tensor_shape(global_inp_name)
# preprocessing: torchvision's ToTensor divides uint8 inputs by 255
totensor_pyt = ToTensor()
chkpt_preproc_name = build_dir+"/tfc_w1_a1_preproc.onnx"
bo.export_finn_onnx(totensor_pyt, ishape, chkpt_preproc_name)
# join preprocessing and core model
pre_model = ModelWrapper(chkpt_preproc_name)
model = model.transform(MergeONNXModels(pre_model))
# add input quantization annotation: UINT8 for all BNN-PYNQ models
global_inp_name = model.graph.input[0].name
model.set_tensor_datatype(global_inp_name, DataType.UINT8)
model.save(build_dir+"/tfc_w1_a1_with_preproc.onnx")
showInNetron(build_dir+"/tfc_w1_a1_with_preproc.onnx")
您可以在上图中观察到两个变化:开始时出现了一个Div节点来执行输入预处理,现在global_in张量具有量化注释,以将其标记为无符号的8位值。
对于后处理,我们将在图的末尾插入k=1的TopK节点。这将为最大值的输出提取索引(类号)。
from finn.transformation.insert_topk import InsertTopK
# postprocessing: insert Top-1 node at the end
model = model.transform(InsertTopK(k=1))
chkpt_name = build_dir+"/tfc_w1_a1_pre_post.onnx"
# tidy-up again
model = model.transform(InferShapes())
model = model.transform(FoldConstants())
model = model.transform(GiveUniqueNodeNames())
model = model.transform(GiveReadableTensorNames())
model = model.transform(InferDataTypes())
model = model.transform(RemoveStaticGraphInputs())
model.save(chkpt_name)
showInNetron(build_dir+"/tfc_w1_a1_pre_post.onnx")
请注意出现在网络末端的Topk节点。有了我们的预处理和后处理,我们可以进入流程中的下一步,即流线化。
2.4 简化
精简是一个包含多个子变换的变换。简化的目标是通过移动浮点运算来消除浮点运算,然后将它们折叠为一个运算,最后一步将它们转换为多阈值节点。有关这方面的理论背景的更多信息,请参阅本文。
让我们看看哪些子转换包括:
from finn.transformation.streamline import Streamline
showSrc(Streamline)
可以看到,在流线型转换中涉及到几个转换。有移动和折叠变换。在最后一步中,操作被转换成多阈值。这里可以详细查看所涉及的转换。在每个转换之后,三个整理转换(GiveUniqueNodeNames、GiveReadableTensorNames和InferDataTypes)应用于模型。
精简后的网络如下:
from finn.transformation.streamline.reorder import MoveScalarLinearPastInvariants
import finn.transformation.streamline.absorb as absorb
model = ModelWrapper(build_dir+"/tfc_w1_a1_pre_post.onnx")
# move initial Mul (from preproc) past the Reshape
model = model.transform(MoveScalarLinearPastInvariants())
# streamline
model = model.transform(Streamline())
model.save(build_dir+"/tfc_w1_a1_streamlined.onnx")
showInNetron(build_dir+"/tfc_w1_a1_streamlined.onnx")
您可以看到,与上一步相比,网络已经大大简化了:许多节点在MatMul层之间消失了,符号节点被替换为多阈值节点。
当前的优化实现是高度网络特定的,如果您的网络的拓扑结构与这里的示例网络非常不同,则它可能不适用于您的网络。我们希望在将来的版本中纠正这一点。
我们的示例网络是一个具有1位双极(-1,+1 values)精度的量化网络,我们希望FINN将它们实现为XNOR popcount操作,如FINN的原始论文中所述。因此,在简化之后,产生的双极矩阵乘法被转换为xnorpopcount操作。这种转换会产生再次折叠并转换为阈值的操作。该程序如下所示。
from finn.transformation.bipolar_to_xnor import ConvertBipolarMatMulToXnorPopcount
from finn.transformation.streamline.round_thresholds import RoundAndClipThresholds
from finn.transformation.infer_data_layouts import InferDataLayouts
from finn.transformation.general import RemoveUnusedTensors
model = model.transform(ConvertBipolarMatMulToXnorPopcount())
model = model.transform(absorb.AbsorbAddIntoMultiThreshold())
model = model.transform(absorb.AbsorbMulIntoMultiThreshold())
# absorb final add-mul nodes into TopK
model = model.transform(absorb.AbsorbScalarMulAddIntoTopK())
model = model.transform(RoundAndClipThresholds())
# bit of tidy-up
model = model.transform(InferDataLayouts())
model = model.transform(RemoveUnusedTensors())
model.save(build_dir+"/tfc_w1a1_ready_for_hls_conversion.onnx")
showInNetron(build_dir+"/tfc_w1a1_ready_for_hls_conversion.onnx")
观察XnorPopcountmatMul和MultiThreshold层对,这是下一步将要寻找的特定模式,以便将它们转换为HLS层。
2.5 HLS层的转换
将节点转换为与finn HLS库中的函数相对应的HLS层。在本例中,此转换将二进制XnorPopcountMatMul层对转换为StreamingFCLayer_Batch层。任何紧随其后的多阈值层也将被吸收到MVTU中。
下面是转换代码,使用netron可视化网络,创建具有StreamingFCLayer_Batch节点的新结构,该节点将对应于finn_hlslib库的函数调用。
注:转换为_hls.InferBinaryStreamingFCLayer文件获取字符串“decoupled”作为参数,这表示权重的mem_mode。在finn中,有不同的选项来设置权重的存储和访问方式。有关详细信息,请查看FINN readthedocs网站的“内部”部分。
import finn.transformation.fpgadataflow.convert_to_hls_layers as to_hls
model = ModelWrapper(build_dir+"/tfc_w1a1_ready_for_hls_conversion.onnx")
model = model.transform(to_hls.InferBinaryStreamingFCLayer("decoupled"))
# TopK to LabelSelect
model = model.transform(to_hls.InferLabelSelectLayer())
# input quantization (if any) to standalone thresholding
model = model.transform(to_hls.InferThresholdingLayer())
model.save(build_dir+"/tfc_w1_a1_hls_layers.onnx")
showInNetron(build_dir+"/tfc_w1_a1_hls_layers.onnx")
每个StreamingFCLayer_Batch节点都有两个指定折叠程度的属性PE和SIMD。在所有节点中,这些属性的值默认设置为1,这将对应于最大折叠(时间多路复用)和最小性能。我们将很快介绍如何调整这些,但首先我们要将网络中的HLS层与非HLS层分开。
2.6 创建数据流分区
在上图中,您可以看到FINN HLS层(StreamingFCLayer\u Batch)与常规ONNX层(reformate、Mul、Add)的混合。要创建位流,FINN需要一个只有HLS层的模型。为了实现这一点,我们将使用CreateDataflowPartition转换在这个图中创建一个“dataflow分区”,将HLS层分离到另一个模型中,并用一个名为StreamingDataflowPartition的占位符层替换它们:
from finn.transformation.fpgadataflow.create_dataflow_partition import CreateDataflowPartition
model = ModelWrapper(build_dir+"/tfc_w1_a1_hls_layers.onnx")
parent_model = model.transform(CreateDataflowPartition())
parent_model.save(build_dir+"/tfc_w1_a1_dataflow_parent.onnx")
showInNetron(build_dir+"/tfc_w1_a1_dataflow_parent.onnx")
我们可以看到,StreamingFCLayer实例都被替换为一个StreamingDataflowPartition,它有一个指向提取的、仅HLS数据流图的属性模型:
from finn.custom_op.registry import getCustomOp
sdp_node = parent_model.get_nodes_by_op_type("StreamingDataflowPartition")[0]
sdp_node = getCustomOp(sdp_node)
dataflow_model_filename = sdp_node.get_nodeattr("model")
showInNetron(dataflow_model_filename)
我们可以看到所有提取的StreamingFCLayer实例都被移动到了子(dataflow)模型中。我们将用ModelWrapper加载子模型并继续处理它。
model = ModelWrapper(dataflow_model_filename)
2.7 折叠和数据宽度转换器,先进先出和TLastMarker插入
FINN中的Folding描述了一个层在执行资源方面的时间复用程度。每一层有几个折叠因子,由PE(输出并行化)和SIMD(输入并行化)参数控制。PE和SIMD值设置得越高,生成的加速器运行得越快,消耗的FPGA资源越多。
由于折叠参数是节点属性,因此可以使用ModelWrapper的helper函数轻松地访问和更改它们。但首先,我们要仔细看看实现StreamingFCLayer_Batch操作的一个节点。这就是Netron可视化帮助我们的地方,在上图中我们可以看到前四个节点正在流化fcu批处理。作为一个例子,我们提取第一个节点。
我们可以为这个节点使用更高级的HLSCustomOp包装器。这些包装器可以方便地访问这些节点的特定属性,例如折叠因子(PE和SIMD)。让我们看看CustomOp包装器定义了哪些节点属性,并调整SIMD和PE属性。
fc0 = model.graph.node[0]
fc0w = getCustomOp(fc0)
print("CustomOp wrapper is of class " + fc0w.__class__.__name__)
fc0w.get_nodeattr_types()
我们可以看到,PE和SIMD被列为节点属性,以及将在连续层之间插入的FIFO的深度,所有这些都可以使用set_nodeattr根据特定约束进行调整。在本笔记本中,我们手动设置折叠因子和FIFO深度,但在未来的版本中,我们将支持根据FINN-R论文中的分析模型确定给定FPGA资源预算的折叠因子。
fc_layers = model.get_nodes_by_op_type("StreamingFCLayer_Batch")
# (PE, SIMD, in_fifo_depth, out_fifo_depth, ramstyle) for each layer
config = [
(16, 49, 16, 64, "block"),
(8, 8, 64, 64, "auto"),
(8, 8, 64, 64, "auto"),
(10, 8, 64, 10, "distributed"),
]
for fcl, (pe, simd, ififo, ofifo, ramstyle) in zip(fc_layers, config):
fcl_inst = getCustomOp(fcl)
fcl_inst.set_nodeattr("PE", pe)
fcl_inst.set_nodeattr("SIMD", simd)
fcl_inst.set_nodeattr("inFIFODepth", ififo)
fcl_inst.set_nodeattr("outFIFODepth", ofifo)
fcl_inst.set_nodeattr("ram_style", ramstyle)
# set parallelism for input quantizer to be same as first layer's SIMD
inp_qnt_node = model.get_nodes_by_op_type("Thresholding_Batch")[0]
inp_qnt = getCustomOp(inp_qnt_node)
inp_qnt.set_nodeattr("PE", 49)
我们正在设置PE和SIMD,以便每一层总共有16个折叠。
除PE和SIMD外,还设置了其他三个节点属性。ram_style指定如何存储权重(BRAM、LUTRAM等)。它可以显式选择或与选项自动你可以让维瓦多决定。inFIFODepth和outFIFODepth指定节点从周围FIFO所需的FIFO深度。这些属性在转换“InsertFIFO”中用于在节点之间插入适当的fifo,这将作为硬件构建过程的一部分自动调用。
在以前的FINN版本中,我们必须调用转换来手动插入数据宽度转换器、fifo和TLastMarker。这不再需要了,因为所有这些都由ZynqBuild或VitisBuild转换处理。
model.save(build_dir+"/tfc_w1_a1_set_folding_factors.onnx")
showInNetron(build_dir+"/tfc_w1_a1_set_folding_factors.onnx")
这就完成了网络准备,网络可以传递到下一个模块Vivado HLS和IPI,如下所述。
3 硬件构建
我们终于可以开始从我们的网络生成硬件了。根据您是想针对Zynq还是Alveo平台,FINN提供了两种转换来构建加速器、集成到适当的shell和构建位文件。它们分别是Zynq和Alveo的ZynqBuild和VitisBuild。在本笔记本中,我们将演示ZynqBuild,因为这些板比较常见,而且为它们上的较小FPGA完成位文件生成要快得多。
由于我们将在这些任务中处理FPGA合成工具,我们将定义两个helper变量来描述xilinxfpga部件名和我们要针对的PYNQ板名。
# print the names of the supported PYNQ boards
from finn.util.basic import pynq_part_map
print(pynq_part_map.keys())
dict_keys([‘Ultra96’, ‘Pynq-Z1’, ‘Pynq-Z2’, ‘ZCU102’, ‘ZCU104’])
# change this if you have a different PYNQ board, see list above
pynq_board = "Pynq-Z1"
fpga_part = pynq_part_map[pynq_board]
target_clk_ns = 10
在FINN的早期版本中,我们必须手动完成几个步骤来生成HLS代码、缝合IP、创建PYNQ项目和运行合成。所有这些步骤现在都由ZynqBuild转换(或Alveo的VitisBuild转换)执行。由于这涉及到调用HLS synthesis和Vivado synthesis,此转换将运行一段时间(最多半小时,具体取决于您的电脑)。
from finn.transformation.fpgadataflow.make_zynq_proj import ZynqBuild
model = ModelWrapper(build_dir+"/tfc_w1_a1_set_folding_factors.onnx")
model = model.transform(ZynqBuild(platform = pynq_board, period_ns = target_clk_ns))
model.save(build_dir + "/tfc_w1_a1_post_synthesis.onnx")
3.1 检查生成的输出
让我们从查看Netron中的后期合成模型开始:
showInNetron(build_dir + "/tfc_w1_a1_post_synthesis.onnx")
我们可以看到,我们的HLS层序列已经被StreamingDataflowPartitions所取代,每个分区指向一个不同的ONNX文件。您可以为每个用户打开Netron会话以查看其内容。在这里,第一个和最后一个分区只包含一个IODMA节点,它是自动插入的,用于在DRAM和加速器之间移动数据。让我们仔细看看中间的分区,它包含了我们所有的层:
model = ModelWrapper(build_dir + "/tfc_w1_a1_post_synthesis.onnx")
sdp_node_middle = getCustomOp(model.graph.node[1])
postsynth_layers = sdp_node_middle.get_nodeattr("model")
showInNetron(postsynth_layers)
我们可以看到StreamingFIFO和StreamingDataWidthConverter实例在硬件构建之前已经自动插入到图中。像ZynqBuild这样的转换使用模型的元数据属性来输入与转换结果相关的额外元数据信息。让我们检查包含所有层的当前图形的元数据:
model = ModelWrapper(postsynth_layers)
model.model.metadata_props
在这里,我们看到一个Vivado项目被构建来创建我们称之为缝合的IP,在这里,实现不同层的所有IP块将缝合在一起。您可以在Vivado中查看此缝合块设计,也可以在此处查看导出的PDF。
回到顶层模型,回想一下ZynqBuild将创建一个Vivado项目并对其进行合成,因此它将创建与创建的路径和文件相关的元数据条目:
model = ModelWrapper(build_dir + "/tfc_w1_a1_post_synthesis.onnx")
model.model.metadata_props
在这里,我们可以看到为PYNQ驱动程序(pynq_driver_dir)和Vivado synthesis项目(vivado_pynq_proj)创建的目录,以及位文件、硬件切换文件和合成报告的位置。
! ls {model.get_metadata_prop("vivado_pynq_proj")}
请随意检查生成的Vivado项目,以了解FINN生成的“缝合IP”是如何执行系统级集成的,它在顶级块设计中显示为StreamingDataflowPartition_1:您可以在此处将其视为导出为PDF的框图。
4 PYNQ部署
我们几乎完成了硬件设计的准备工作。我们现在将把它放在一个适合用作PYNQ覆盖的形式中,并对其进行综合和部署。
4.1 部署和远程执行
我们现在将使用DeployToPYNQ转换创建一个包含位文件和驱动程序文件的部署文件夹,并将其复制到PYNQ板。您可以更改下面PYNQ的默认IP地址、用户名、密码和目标文件夹。
from finn.transformation.fpgadataflow.make_deployment import DeployToPYNQ
ip = "192.168.2.99"
port = "22"
username = "xilinx"
password = "xilinx"
target_dir = "/home/xilinx/finn_tfc_end2end_example"
model = model.transform(DeployToPYNQ(ip, port, username, password, target_dir))
model.save(build_dir + "/tfc_w1_a1_pynq_deploy.onnx")
让我们验证远程访问凭据是否保存在模型元数据中,以及部署文件夹是否已成功复制到主板:
model.model.metadata_props
target_dir_pynq = target_dir + "/" + model.get_metadata_prop("pynq_deployment_dir").split("/")[-1]
target_dir_pynq
! sshpass -p {password} ssh {username}@{ip} -p {port} 'ls -l {target_dir_pynq}'
我们只有另外两个步骤才能使用MNIST数据集中的一些测试数据远程执行部署的位文件。让我们加载一些FINN附带的测试数据。
from pkgutil import get_data
import onnx.numpy_helper as nph
import matplotlib.pyplot as plt
raw_i = get_data("finn", "data/onnx/mnist-conv/test_data_set_0/input_0.pb")
x = nph.to_array(onnx.load_tensor_from_string(raw_i))
plt.imshow(x.reshape(28,28), cmap='gray')
model = ModelWrapper(build_dir + "/tfc_w1_a1_pynq_deploy.onnx")
iname = model.graph.input[0].name
oname = parent_model.graph.output[0].name
ishape = model.get_tensor_shape(iname)
print("Expected network input shape is " + str(ishape))
最后,我们可以在图上调用execute_onnx,它将使用位文件在内部调用远程执行,获取结果并返回numpy数组。您可能还记得StreamingDataflowPartition中遗漏了一个“重塑”节点。在传入输入时,我们将使用numpy函数调用手动执行该操作,但是网络中的所有其他内容都会在StreamingDataflowPartition中结束,所以我们只需要这样做。
import numpy as np
from finn.core.onnx_exec import execute_onnx
input_dict = {iname: x.reshape(ishape)}
ret = execute_onnx(model, input_dict)
ret[oname]
我们看到网络正确地预测这是一个数字2。
4.2 PYNQ板验证
这里的所有命令行提示都是用PYNQ板上的sudo执行的,因此我们将使用一个变通方法(sshpass和echo password | sudo-S命令)从运行在主机上的笔记本中获得该操作。
确保你的PYNQ板有一个工作的互联网连接为下一步,因为有些有一些下载涉及。
为了验证准确性,我们首先需要将数据集加载Python包安装到PYNQ板上。这将为我们下载和访问MNIST数据集提供一种方便的方法。
要在PYNQ上执行的命令:
pip3 install git+https://github.com/fbcotter/dataset_loading.git@0.0.4#egg=dataset_loading
! sshpass -p {password} ssh -t {username}@{ip} -p {port} 'echo {password} | sudo -S pip3 install git+https://github.com/fbcotter/dataset_loading.git@0.0.4#egg=dataset_loading'
我们现在可以使用验证.py与驱动程序一起生成的脚本,用于测量MNIST数据集上的top-1精度。
要在PYNQ上执行的命令:
python3.6 validate.py --dataset mnist --batchsize 1000
! sshpass -p {password} ssh -t {username}@{ip} -p {port} 'cd {target_dir_pynq}; echo {password} | sudo -S python3.6 validate.py --dataset mnist --batchsize 1000'
我们看到,最终的top-1准确率为92.96%,这非常接近Brevitas中BNN-PYNQ准确率表中报告的93.17%。
4.3 PYNQ板上的吞吐量测试
除了功能验证之外,FINN还提供了直接在PYNQ板上测量网络性能的可能性。这可以使用核心函数throughput_test来完成。在下一节中,我们将导入函数并执行它。首先,我们再次提取remote_exec_model并将其传递给函数。函数将网络的度量作为字典返回。
from finn.core.throughput_test import throughput_test_remote
model = ModelWrapper(build_dir + "/tfc_w1_a1_pynq_deploy.onnx")
res = throughput_test_remote(model, 10000)
print("Network metrics:")
for key in res:
print(str(key) + ": " + str(res[key]))
与折叠值一起,我们可以评估加速器的性能。每一层的总折叠因子为64,由于网络是完全管道化的,因此如下:II=64。II是起始间隔,表示处理一个输入需要多少个周期。
II = 64
# frequency in MHz
f_MHz = 100
# expected throughput in MFPS
expected_throughput = f_MHz / II
# measured throughput (FPS) from throughput test, converted to MFPS
measured_throughput = res["throughput[images/s]"] * 0.000001
# peformance
print("We reach approximately " + str(round((measured_throughput / expected_throughput)*100)) + "% of the ideal performance.")
以10000的批量和100 MHz的频率记录测量值。在即将发布的FINN版本中,我们将提高生成的加速器示例的效率。


















 670
670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











