






 本文介绍了基于Kdtree的DBSCAN算法用于点云聚类,详细阐述了DBSCAN的基本概念和算法流程,并探讨了算法的改进方法,包括距离矩阵预计算和Kdtree查询邻域点。实验证明,Kdtree方法在效率上显著优于传统方法,同时保持了良好的聚类效果。
本文介绍了基于Kdtree的DBSCAN算法用于点云聚类,详细阐述了DBSCAN的基本概念和算法流程,并探讨了算法的改进方法,包括距离矩阵预计算和Kdtree查询邻域点。实验证明,Kdtree方法在效率上显著优于传统方法,同时保持了良好的聚类效果。
作者:姜小明 @github
日期:2020-06-28
关键字:Kdtreee, DBSCAN, PCL, 点云
DBSCAN算法适用于点云聚类,但是3d点云数据一般较大,朴素的DBSCAN算法处理起来效率很低。对此,可以通过使用Kdtree检索临近点,从而加速DBSCAN算法。
1. DBSCAN
在点云数据分析中,我们经常需要对点云数据进行分割,提取感兴趣的部分。聚类是点云分割中的一类方法(其他方法有模型拟合、区域增长、基于图的方法、深度学习方法等)。DBSCAN 是一种基于密度的聚类算法,具有抗噪声、无需指定类别种数、可以在空间数据中发现任意形状的聚类等优点,适用于点云聚类。
1.1 概念
DBSCAN中为了增加抗噪声的能力,引入了核心对象等概念。
ε: 参数,邻域距离。
minPts: 参数,核心点领域内最少点数。
核心点: 在 $epsilon$ 邻域内有至少 $minPts$ 个邻域点的点为核心点。
直接密度可达: 对于样本集合 $D$,如果样本点 $q$ 在 $p$ 的 $epsilon$ 邻域内,并且 $p$ 为核心对象,那么对象 $q$ 从对象 $p$ 直接密度可达。
密度可达: 对于样本集合 $D$,给定一串样本点$p_1$, $p_2$, ..., $p_n$,$p = p_1$, $q = p_n$, 假如对象 $p_i$ 从 $p_{i-1}$ 直接密度可达,那么对象 $q$ 从对象 $p$ 密度可达。
密度相连: 存在样本集合 $D$ 中的一点 $o$ ,如果对象 $o$ 到对象 $p$ 和对象 $q$ 都是密度可达的,那么 $p$ 和 $q$ 密度相联。
DBSCAN 算法核心是找到密度相连对象的最大集合。参考 百度百科-DBSCAN
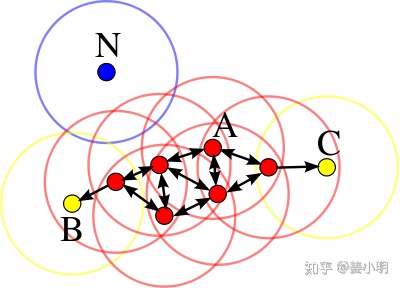
如图,$minPts=4$,红点为高密度核心点,黄点为边界点,蓝点为低密度噪声点。红黄点组成了一个簇(聚类)。
核心点、边界点、噪声点对应于不同密度,这就是 DBSCAN 属于基于密度聚类方法的原因,也是其具有抗噪声能力的原因。
1.2 算法
如前所述,DBSCAN 算法核心是找到密度相连对象的最大集合。为了实现该算法,有两种方法: - 先遍历所有的点根据邻域点数找出所有核心点,然后采用区域增长方法对其聚类,再遍历聚类中的点,将其直接密度可达的点加入聚类,从而形成最终的聚类。 - 逐点遍历,如果该点非核心点,则认为是噪声点并忽视(噪声点可能在后续被核心点归入聚类中),若为核心点则新建聚类,并将所有邻域点加入聚类。对于邻域点中的核心点,还要递归地把其邻域点加入聚类。依此类推直到无点可加入该聚类,并开始考虑新的点,建立新的聚类。
这里我们采用第二种方法,优点是只用遍历一趟。 伪代码如下(参考 维基百科-DBSCAN):
DBSCAN(DB, distFunc, eps, minPts) {
C = 0 /* Cluster counter */
for each point P in database DB {
if label(P) ≠ undefined then continue /* Previously pro 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 801
801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









