







从高通量测序技术进入到单个微生物和微生物群落研究以来,已经有大量广为人知的序列拼接工具被开发出来,有的专门用于二代数据,比如:Velvet、Spades、ABySS、SOAPdenovo等;有的专门用于三代数据,比如:Canu、miniasm、Racon。然而二代和三代测序数据混合拼接获得单菌完成图的工具还不多见,尽管Spades软件中提供了这种混合拼接的分析模块,但在很多项目的实际分析中仍然有一些不尽如人意的地方。
今天我介绍一款最近在微生物基因组高通量测序科研圈获得广泛好评的软件——Unicycler,已在大量单菌完成图项目中得到成功应用。在我们前期的项目中,应用这款工具均能获得细菌完整基因组。
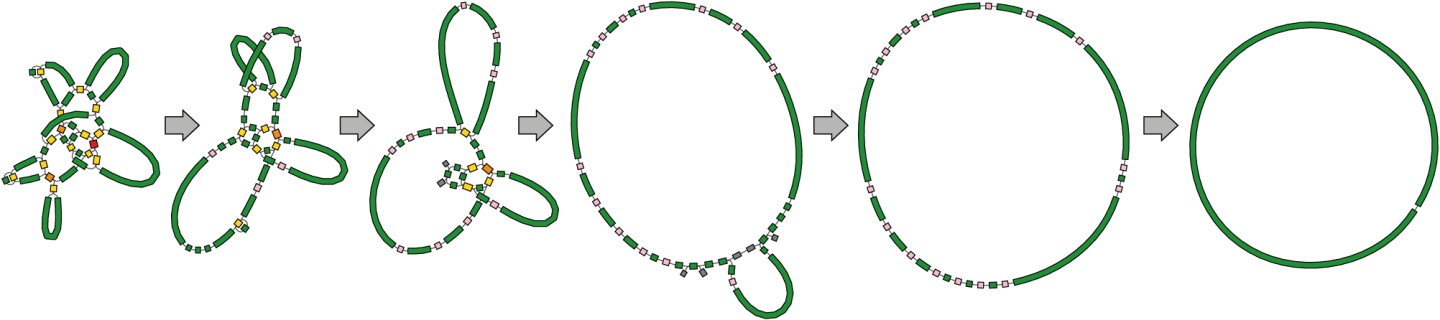
混合拼接(同时使用二代short reads和三代long reads测序数据)的算法是Unicycler分析流程的真正亮点。首先,Unicycler对Illumina short reads数据进行拼接,这一步采用的是Spades工具,生成Illumina拼接图。然后,Unicycler使用long reads数据来构建桥(bridges),桥的搭建通常使Unicycler能够解析基因组中的所有重复序列,从而完成完整基因组的组装。
在利用long reads搭桥的过程中,Unicycler采用miniasm和Racon这两个工具。但是,这个步骤里面用到的数据不仅包含long reads数据,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2873
2873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









