







关于 RDA(Redundancy analysis 冗余分析)是什么,相信对于已经有可视化需求的同学来说已经不用更多的解释了。
在 R 中常用来进行 RDA 分析和绘制工作的是 vegan 和 ggvegan 这两个包。然而,在实际使用中,最常遇到的问题是虽然这些包内建的 plot 等功能可以绘制出基本可用的包,但想要进一步的定制图形却没那么容易。
想要绘制出一副自己满意、编辑满意、导师满意最主要的是审稿人满意的 RDA 结果,作为最强可视化工具之一的 ggplot2 包毋庸置疑是最佳的选择。
我们需要什么样的 RDA 图
首先,我们来思考我们需要什么样的 RDA 图?按照世纪需求以及审稿人的建议:
I would recommend showing in bold the variables with significant correlations
笔者最后的目标是绘制一幅:
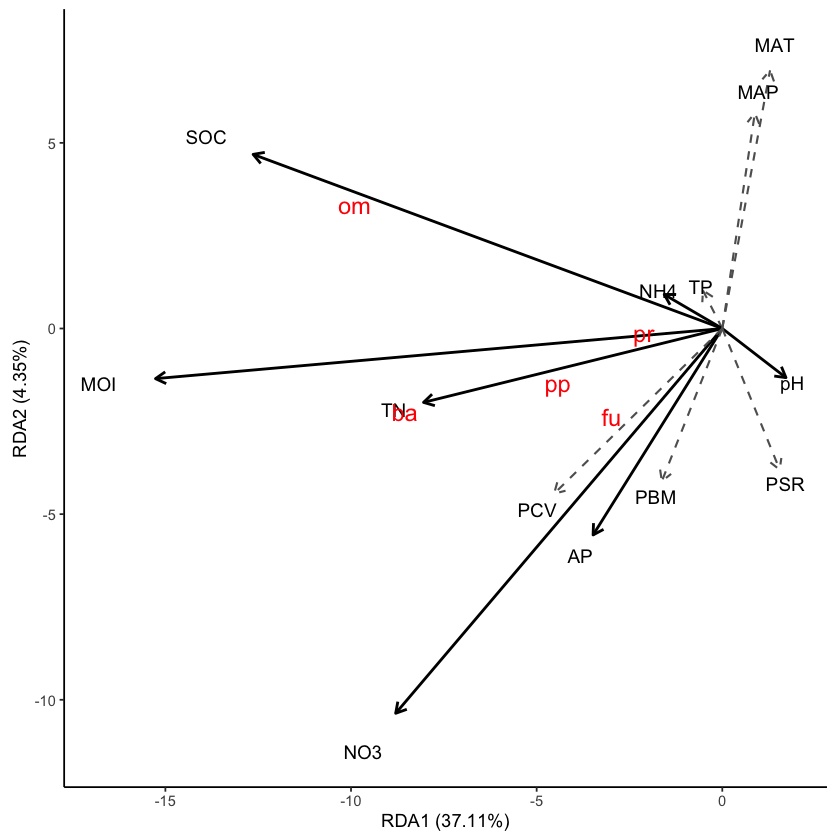
1. 显示物种信息(实际上是响应变量矩阵);
2. 环境变量(实际上是解释变量矩阵);
3. 在两轴上能显示各自的解释度;
4. 标记有显著性的解释变量。以笔者对 plot.rda 以及 autoplot.rda 这两个 vegan 和 ggvegan 内建函数的浅薄了解,似乎很难完成。
如何「标记有显著性的解释变量」?
如果进行过 RDA 分析不难发现,使用 vegan 内建的 rda 是没有标记解释变量的显著性的。其实这种显著性需要 vegan 内建的 envfit 函数来得到一个及其近似的结果。通常这个方法在论文中会写作:
Monte Carlo permutation (999 permutations) was used to identify axes with significant eigenvalues and species-environment correlations.
由于是进行了 999 次(默认参数可以修改)的蒙特卡洛抽样,因此这个结果是及其近似的结果,直接用作 RDA 中解释变量的显著性是没有问题的。然而,envfit 输出的结果并非标准的 data.frame 或者类似的结果,无法方便的输出或者进行分析,后续我们还会进行结果提取的步骤,暂且按下不表。
RDA 和 ENVFIT 分析
此例,我们使用随机抽取的 150 条土壤线虫群落群落数据以及对应的环境数据,由于不影响后续的理解以及版权考量,对各参数名不再解释。
每一步的操作以及原因以注释的形式呈现。
library('tidyverse')
# read Environmental Variables
df_env <- read_csv('df_env_smp.csv')
# read Community composition matrix
df_com <- read_csv('df_com_smp.csv')
# View the structure of data
head(df_env)
head(df_com)
Parsed with column specification:
cols(
pH = [32mcol_double()[39m,
MOI = [32mcol_double()[39m,
TN = [32mcol_double()[39m,
TP = [32mcol_double()[39m,
AP = [32mcol_double()[39m,
NH4 = [32mcol_double()[39m,
NO3 = [32mcol_double()[39m,
SOC = [32mcol_double()[39m,
MAT = [32mcol_double()[39m,
MAP = [32mcol_double()[39m,
PBM = [32mcol_double()[39m,
PCV = [32mcol_double()[39m,
PSR = [32mcol_double()[39m
)
Parsed with column specification:
cols(
p 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 8011
8011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









