






Qwen、LLaMA和DeepSeek在模型架构、训练目标和应用场景上存在显著差异,具体分析如下:
1. Qwen的模型结构
Qwen(通义千问)由阿里巴巴达摩院开发,基于改进的Transformer架构,整体设计参考了LLaMA的框架,但进行了多项优化:
- 分词器优化:Qwen的分词器在中文压缩效率上优于LLaMA、Baichuan等模型,降低了服务成本。
- 支持长上下文:通过扩展上下文窗口(如Qwen 2.5支持128k tokens),适合处理长文本任务。
- MoE架构:部分版本采用 混合专家(Mixture-of-Experts, MoE) ,动态激活任务相关参数以提高效率。
- 训练数据:以中文语料为主,兼顾多语言数据,强化中文NLP任务表现。
2. Qwen与LLaMA的区别
- 架构差异:
- LLaMA(Meta开发)同样基于Transformer,但优化了稀疏注意力机制以提升计算效率。
- Qwen的分词器和上下文窗口设计更适应中文需求,而LLaMA以英文训练为主。
- 应用场景:
- Qwen:专精中文任务(如文本生成、对话系统),在多语言支持中突出中英双语。
- LLaMA:侧重英文通用任务(如翻译、问答),开源且适合研究定制。
- 性能表现:
- 在中文基准(如C-Eval、CMMLU)上,Qwen显著优于LLaMA。
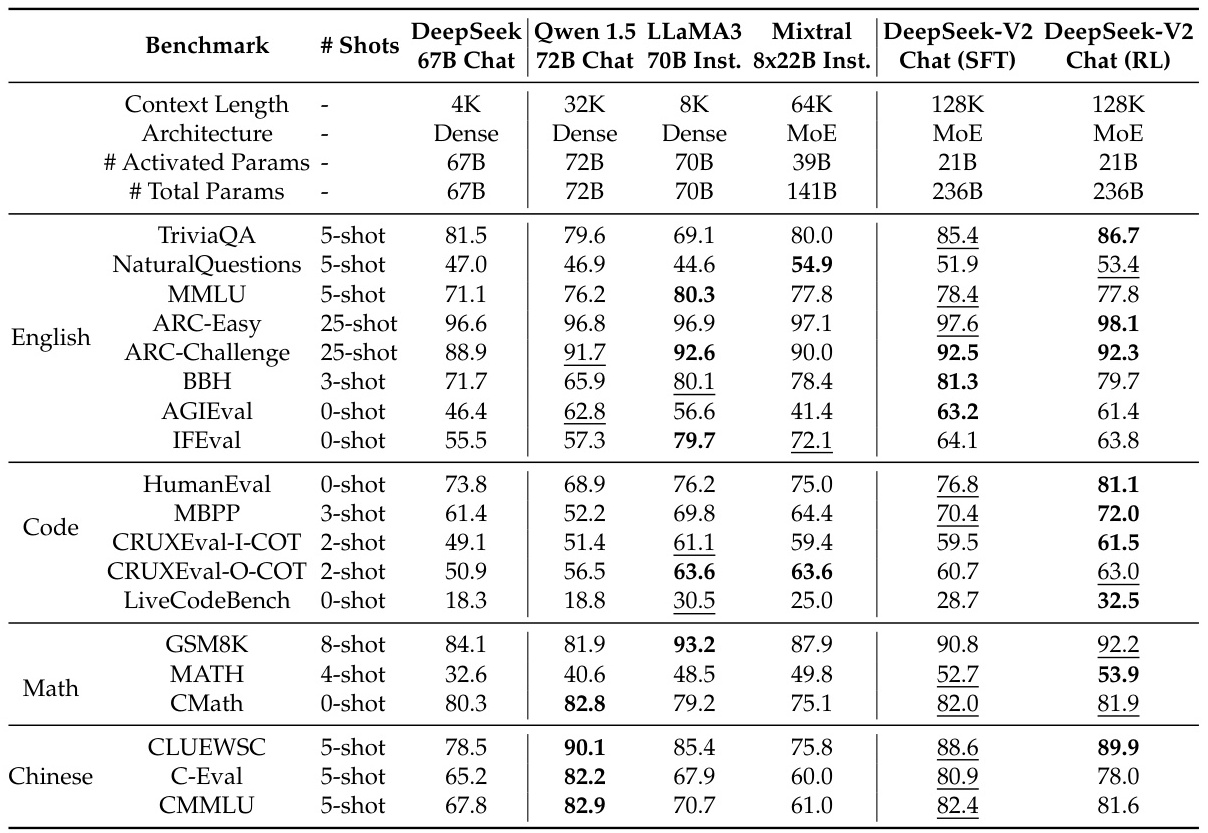
- 在英文任务(如TriviaQA)中,LLaMA 3.1-405B等版本表现更优。
- 在中文基准(如C-Eval、CMMLU)上,Qwen显著优于LLaMA。
3. Qwen与DeepSeek的区别
- 架构创新:
- DeepSeek采用DeepSeekMoE架构,结合共享专家(Shared Expert)和路由专家(Routed Expert)的新型路由逻辑,显著降低计算资源需求。
- 引入 MLA(Multi-Head Latent Attention) 注意力机制,通过低秩压缩减少KV缓存,提升推理效率。
- 训练方法:
- DeepSeek强调强化学习技术,通过极少量标注数据提升模型推理能力。
- Qwen则依赖监督微调(SFT)和人类反馈强化学习(RLHF)优化对话质量。
- 性能对比:
- 中文任务:Qwen在CLUEWSC、C-Eval等中文基准上表现更优。
- 数学与代码:DeepSeek-V2在GSM8K、HumanEval等任务中超越Qwen。
- 推理效率:DeepSeek的蒸馏模型(如DeepSeek-R1)在低参数量下保持高性能,适合边缘部署。
4. 总结
- 选择建议:
- 中文优先:Qwen因中文优化和长上下文支持更优。
- 逻辑推理与边缘计算:DeepSeek凭借MLA和MoE架构更适合高效推理。
- 研究灵活性:LLaMA开源特性适合定制化开发。
以上差异体现了不同模型在架构设计和应用目标上的针对性,需根据具体需求选择。

















 632
632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









