







目录
一、彻底理解I/O多路复用
常用的I/O操作接口一般有以下几类:
- 打开文件,open
- 改变读写位置,seek
- 文件读写,read、write
- 关闭文件,close
1.文件描述符
文件描述仅仅就是一个数字而已,但是通过这个数字我们可以操作一个打开的文件。
有了文件描述符,进程可以对文件一无所知,比如文件在磁盘的什么位置、加载到内存中又是怎样管理的等等,这些信息统统交由操作系统打理,进程无需关心,操作系统只需要给进程一个文件描述符就足够了。
2.IO多路复用
所谓I/O多路复用指的是这样一个过程:
- 我们拿到了一堆文件描述符(不管是网络相关的、还是磁盘文件相关等等,任何文件描述符都可以)
- 通过调用某个函数告诉内核:“这个函数你先不要返回,你替我监视着这些描述符,当这堆文件描述符中有可以进行I/O读写操作的时候你再返回”
- 当调用的这个函数返回后我们就能知道哪些文件描述符可以进行I/O操作了。
也就是说通过I/O多路复用我们可以同时处理多路I/O。那么有哪些函数可以用来进行I/O多路复用呢?在Linux世界中有这样三种机制可以用来进行I/O多路复用:(本质上select、poll、epoll都是阻塞式I/O)
(1)select
总结下来select有这样几个特点:
- 我能照看的文件描述符数量有限,不能超过1024个
- 用户给我的文件描述符需要拷贝的内核中
- 我只能告诉你有文件描述符满足要求了,但是我不知道是哪个,你自己一个一个去找吧(遍历)
因此我们可以看到,select机制的这些特性在高并发网络服务器动辄几万几十万并发链接的场景下无疑是低效的。
(2)poll
poll和select是非常相似的,poll相对于select的优化仅仅在于解决了文件描述符不能超过1024个的限制,select和poll都会随着监控的文件描述数量增加而性能下降,因此不适合高并发场景。
(3)epoll
在Linux平台,epoll基本上就是高并发的代名词。
二、读取文件时,程序经历了什么?
I/O就是简单的数据Copy。
- 如果数据是从外部设备copy到内存中,这就是Input。
- 如果数据是从内存copy到外部设备,这就是Output。
- 内存与外部设备之间不嫌麻烦的来回copy数据就是Input and Output,简称I/O(Input/Output),仅此而已。
1.阻塞式I/O
(1)阻塞队列
CPU执行指令的速度相比,I/O操作操作是非常慢的,因此操作系统是不可能把宝贵的CPU计算资源浪费在无谓的等待上的。操作系统检测到进程向I/O设备发起请求后就暂停进程的运行:记录下当前进程的运行状态并把CPU的PC寄存器指向其它进程的指令。
进程有暂停就会有继续执行,因此操作系统必须保存被暂停的进程以备后续继续执行,显然我们可以用阻塞队列来保存被暂停执行的进程。
(2)就绪队列
操作系统中除了有阻塞队列之外也有就绪队列,所谓就绪队列是指队列里的进程准备就绪可以被CPU执行了。为什么不直接执行非要有个就绪队列呢?答案很简单,因为在即使只有1个核的机器上也可以创建出成千上万个进程,CPU不可能同时执行这么多的进程,因此必然存在这样的进程,即使其一切准备就绪也不能被分配到计算资源,这样的进程就被放到了就绪队列。
(3)举个例子(以进程为例,线程同理)
- 进程A中有一段读取文件的代码,操作系统检测到进程A向I/O设备发起请求后就暂停进程A的运行。进程A被暂停执行并被放到阻塞队列中。操作系统已经向磁盘发送了I/O请求,因此磁盘driver开始将磁盘中的数据copy到进程A的buff中,虽然这时进程A已经被暂停执行了,但这并不妨碍磁盘向内存中copy数据。
- 当进程A被暂停执行后CPU是不可以闲下来的,因为就绪队列中还有嗷嗷待哺的进程B,这时操作系统开始在就绪队列中找下一个可以执行的进程,也就是这里的进程B。操作系统将进程B从就绪队列中取出,找出进程B被暂停时执行到的机器指令的位置,然后将CPU的PC寄存器指向该位置,这样进程B就开始运行啦。(注意:进程B在被CPU执行时,磁盘在向进程A的内存空间中copy数据。数据copy和指令执行在同时进行,在操作系统的调度下,CPU、磁盘都得到了充分的利用。)
- 磁盘终于将全部数据都copy到了进程A的内存中,这时磁盘通知操作系统任务完成啦,你可能会问怎么通知呢?这就是中断。操作系统接收到磁盘中断后发现数据copy完毕,进程A重新获得继续运行的资格,这时操作系统小心翼翼的把进程A从阻塞队列放到了就绪队列当中。
- 此后进程B继续执行,进程A继续等待,进程B执行了一会儿后操作系统认为进程B执行的时间够长了,因此把进程B放到就绪队列,把进程A取出并继续执行。(注意操作系统把进程B放到的是就绪队列,因此进程B被暂停运行仅仅是因为时间片到了而不是因为发起I/O请求被阻塞)
- 进程A继续执行,此时buff中已经装满了想要的数据,进程A就这样愉快的运行下去了,就好像从来没有被暂停过一样,进程对于自己被暂停一事一无所知。
2.零拷贝
一般情况下I/O数据是要首先copy到操作系统内部,然后操作系统再copy到进程空间中。
绕过操作系统直接进行数据copy的技术被称为Zero-copy,也就零拷贝,高并发、高性能场景下常用的一种技术。
三、零拷贝了解一下
常说的buffer,所谓buffer就是一块可用的内存空间,用来暂存数据。
1.传统read/write。
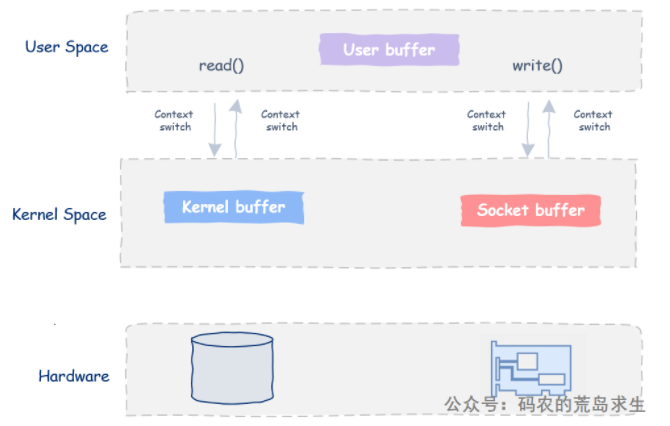
当浏览器请求一个图片或某个文件时服务器端的工作其实是非常简单的:服务器只需要从磁盘中抓出该文件然后丢给网络发送出去。但是这个过程涉及到四次内存拷贝和四次上下文切换(数据拷贝有性能损耗)。
read(fileDesc, buf, len);
write(socket, buf, len);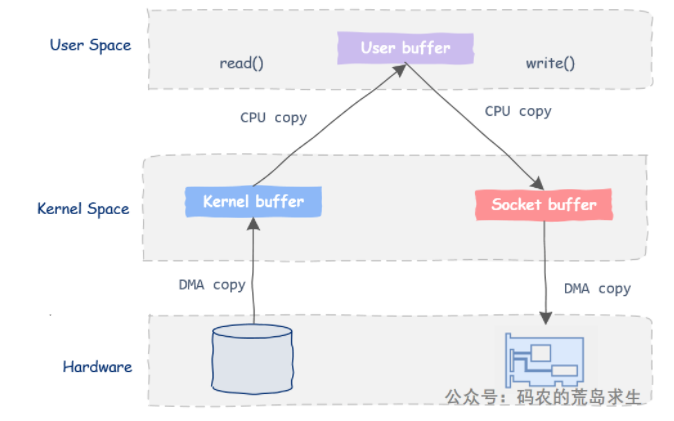
- read函数会涉及一次用户态到内核态的切换,操作系统会向磁盘发起一次IO请求,当数据准备好后通过DMA技术把数据拷贝到内核的buffer中,注意本次数据拷贝无需CPU参与。
- 此后操作系统开始把这块数据从内核拷贝到用户态的buffer中,此时read()函数返回,并从内核态切换回用户态,到这时read(fileDesc, buf, len);这行代码就返回了,buf中装好了新鲜出炉的数据。
- 接下来send函数再次导致用户态与内核态的切换,此时数据需要从用户态buf拷贝到网络协议子系统的buf中,具体点该buf属于在代码中使用的这个socket。
- 此后send函数返回,再次由内核态返回到用户态;此时在程序员看来数据已经成功发出去了,但实际上数据可能依然停留在内核中,此后第四次数据copy开始,利用DMA技术把数据从socket buf拷贝给网卡,然后真正的发送出去。
注意观察buf,服务器全程没有对buf中的数据进行任何修改,buf里的数据在用户态逛了一圈后挥一挥衣袖没有带走半点云彩就回到了内核态。既然在用户态没有对数据进行任何修改,那为什么要这么麻烦的让数据在用户态来个一日游呢?直接在内核态从磁盘给到网卡不就可以了吗?零拷贝来了~
2.节省数据拷贝
(1)方式一:mmap
利用mmap我们节省了一次数据拷贝,上下文切换依然是四次。mmap仅仅将文件内容映射到了进程地址空间中,并没有真正的拷贝到进程地址空间,这节省了一次从内核态到用户态的数据拷贝。
所以之前两行代码可以改为:
buf = mmap(file, len);
write(socket, buf, len);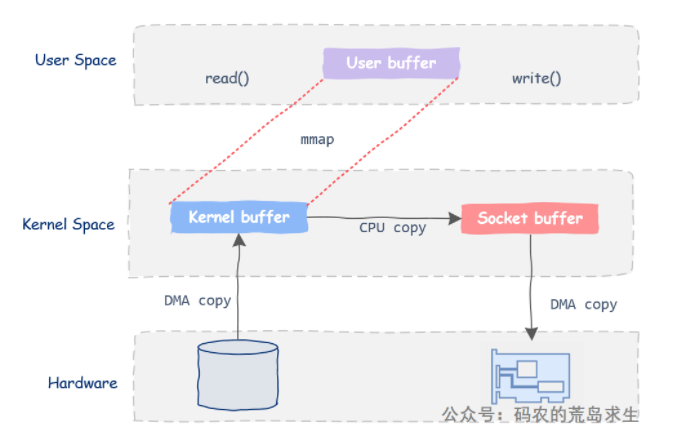
尽管mmap可以节省数据拷贝,但维护文件与地址空间的映射关系也是有代价的,除非CPU拷贝数据的时间超过维系映射关系的代价,否则基于mmap的程序性能可能不及传统的read/write。
(2)方式二:sendfile(并不是零拷贝)
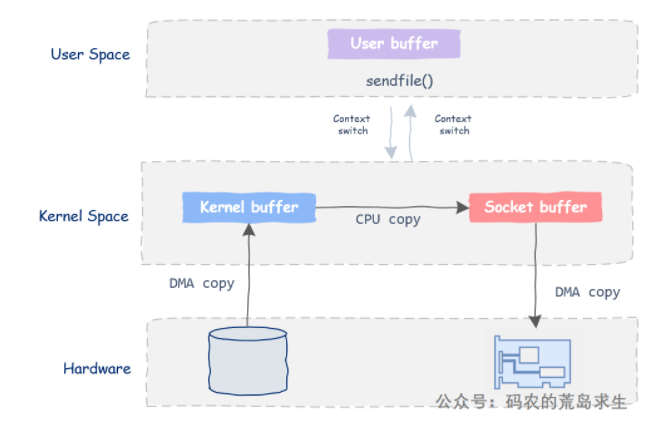
调用sendfile后,首先DMA机制会把数据从磁盘拷贝到内核buf中,接下来把数据从内核buf拷贝到相应的socket buf中,最后利用DMA机制将数据从socket buf拷贝到网卡中。
我们可以看到,同使用传统的read/write相比少了一次数据拷贝,而且内核态和用户态的切换只有两次。
(3)方式三:软硬件结合
挺复杂,不想看了。。。
总之,如果你的程序对性能要没有到那种极度苛刻哪怕慢1ns都不行的时候,老老实实用read/write,相比这些所谓的技巧,内存拷贝没有那么糟糕。
四、mmap可以让程序员解锁哪些骚操作?
操作磁盘文件要比操作内存复杂很多,根本原因就在于寻址方式不同。
对内存来说我们可以直接按照字节粒度去寻址,但对磁盘上保存的文件来说则不是这样的,磁盘上保存的文件是按照块(block)的粒度来寻址的,因此你必须先把磁盘中的文件读取到内存中,然后再按照字节粒度来操作文件内容。
1.mmap
mmap一个文件或者其它对象映射进内存。文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一个页不被使用的空间将会清零。mmap在用户空间映射调用系统中作用很大。
2.IO VS mmap
(1)mmap缺点
常用的标准IO,也就是read/write其底层是涉及到系统调用的,同时当使用read/write读写文件内容时,需要将数据从内核态copy到用户态,修改完毕后再从用户态copy到内核态,显然,这些都是有开销的。
基于mmap读写磁盘文件不会招致系统调用以及额外的内存copy开销,但mmap也不是完美的,mmap也有自己的缺点。
其中一方面在于为了创建并维持地址空间与文件的映射关系,内核中需要有特定的数据结构来实现这一映射,这当然是有性能开销的,除此之外另一点就是缺页问题,page fault。
(2)mmap优势
- mmap可以像直接读写内存那样来操作磁盘文件。
- mmap可节省内存(比如多个进程需要共用一个动态链接库)。
很多进程都依赖于同一个库,那么我就用mmap把该库直接映射到各个进程的地址空间中,尽管每个进程都认为自己地址空间中加载了该库,但实际上该库在内存中只有一份。
- mmap在处理大文件时有优势:这里的大文件指的是文件的大小超过你的物理内存。
在这种场景下如果你使用传统的read/write,那么你必须一块一块的把文件搬到内存,处理完文件的一小部分再处理下一部分。这种需要在内存中开辟一块空间——也就是我们常说的buffer,的方案听上去就麻烦有没有,而且还需要操作系统把数据从内核态copy到用户态的buffer中。
mmap情况就不一样了,只要你的进程地址空间足够大,可以直接把这个大文件映射到你的进程地址空间中,即使该文件大小超过物理内存也可以,这就是虚拟内存的巧妙之处了,当物理内存的空闲空间所剩无几时虚拟内存会把你进程地址空间中不常用的部分扔出去,这样你就可以继续在有限的物理内存中处理超大文件了。
使用mmap处理大文件要注意一点,如果你的系统是32位的话,进程的地址空间就只有4G,这其中还有一部分预留给操作系统,因此在32位系统下可能不足以在你的进程地址空间中找到一块连续的空间来映射该文件,在64位系统下则无需担心地址空间不足的问题,这一点要注意。
3.总结
谈到mmap的与标准IO(read/write)的性能情况就比较复杂了,标准IO涉及到系统调用以及用户态内核态的copy问题,而mmap则涉及到维持内存与磁盘文件的映射关系以及缺页处理的开销,单纯的从理论分析这二者半斤八两,如果你的应用场景对性能要求较高,那么你需要基于真实场景进行测试。
















 131
131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











