






Date:2020-12-3
作者:Todd-Qi
原文链接:多视图立体匹配论文分享CasMVSNet
论文题目:Cascade Cost Volume for High-Resolution Multi-View Stereo and Stereo Matching
0、引言
CasMVSNet[1]是CVPR2020的工作,在开始介绍这篇文章之前,我们首先回顾一下之前的工作。
基于学习的MVS算法可以分为四个模块:
·特征提取模块
·特征匹配和代价聚合模块
·深度图回归模块
·深度图细化模块[可选项]

以ECCV2018的MVSNet[2]为例,这里简单介绍每个模块的实现方式,具体细节可参考论文或之前的推文。
·特征提取模块:8层的2D卷积操作,除最后一层外,卷积操作后跟随BatchNorm层和ReLU;
·特征匹配和代价聚合模块:
※特征匹配:通过单应变换将源图像的特征图变换到参考视图下,并基于方差指标将多视图的特征体聚合为一个代价体。
※代价聚合:4个尺度的3DCNN网络·深度图回归:soft-argmin操作。
1、文章动机
基于学习的MVS算法因为受到显存的限制,输出的深度图的空间分辨率只有输入图像的1/16大小(长宽均为输入图像的1/4大小)。以MVSNet为例,对于1600×1184大小的输入图像,需要构建h×w×D×F=400×296×256×8大小的代价体,16GB的显卡才可以胜任。之前的方法限制了高分辨率MVS算法的发展。那么问题来了,为什么要得到高分辨率的深度图呢?我们知道,MVS算法的评测是对最后生成的点云进行评测。同等情况下,深度图分辨率越高,得到的空间3D点数目越多,那么点云的完整性会更高,重建质量则更佳。

关于代价体:代价体(Cost Volume)是三维的,存储时为4D的tensor。我们可以理解为:代价体每一个位置存储的是一个F维的向量而不是标量。如图2所示,空间分辨率H×W越高,平面假设数D越多,深度间隔I越小,那么得到的深度图质量越高;同时显存占用越大、耗时越长。那么,有没有一种可以权衡精度和效率的方法呢?
2. 方法
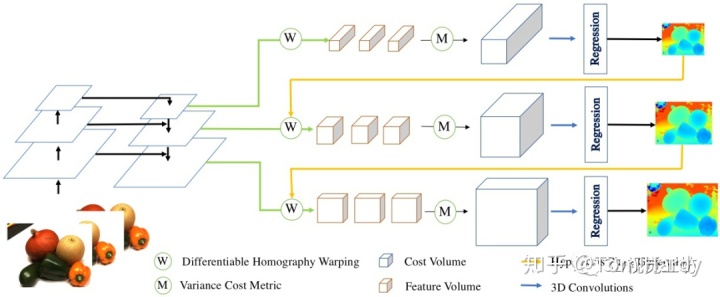
整体思路:CasMVSNet使用级联的代价体来实现coarse-to-fine的深度估计。具体地,首先通过一个较小的代价体估计低分辨率的深度图,然后我们可以根据上一级输出的深度图,缩减当前尺度的深度假设范围。CasMVSNet使用3级的代价体来实现深度图估计,包括两级的中间结果和一个最终的深度输出。· 特征提取模块:CasMVSNet需要在每个尺度上都进行特征提取和代价体构建,所以需要输入图像的多尺度特征。文章使用了三个尺度的FPN(Feature Pyramid Network)网络。三个尺度的特征图空间分辨率分别为输入图像的{1/16, 1/4, 1}大小。和之前的方法一样,不同输入图像之间共享权重。·特征匹配和代价聚合:同MVSNet·深度图回归:同MVSNet
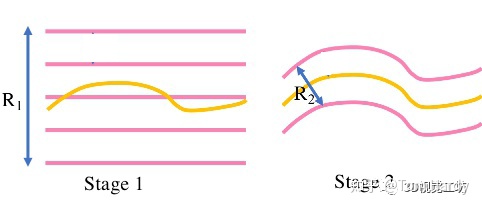
深度范围的确定:


3、实验结果
3.1 DTU数据集
CasMVSNet在DTU[3]数据集的实验结果如表1所示,和Baseline方法MVSNet相比,重建质量有35.6% 的提升,显存占用降低了50.6%,运行时间有59.3%的提升。点云重建质量也超过了2019年的R-MVSNet、P-MVSNet和Point-MVSNet等方法。图5中(a)~(d)是不同方法的DTU scan9的可视化结果,我们可以看到CasMVSNet重建的点云更加稠密,点云质量更佳,这也说明了高分辨深度估计的优势所在。图5中(e)为不同方法的GPU占用和精度对比图;图5中(f)为不同方法的运行时间和精度对比图。
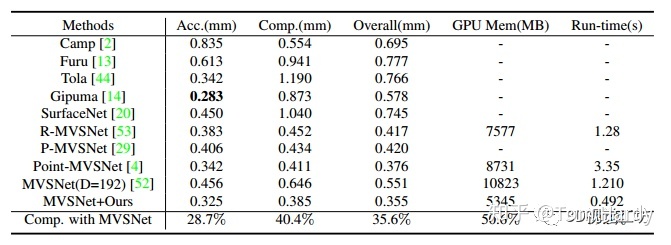

图 5 与SOTA方法的实验效果对比图
3.2 Tanks and Temples 数据集
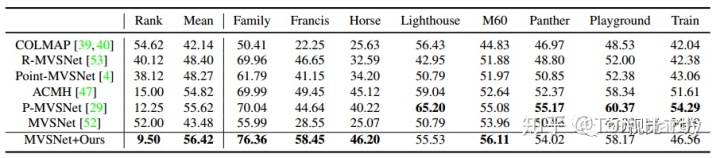
CasMVSNet在Tanks and Temple[4]数据集的实验结果如表2所示,重建点云的可视化结果如图6所示。

参考文献
1.Gu X, Fan Z, Zhu S, et al. Cascade cost volume for high-resolution multi-view stereo and stereo matching[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 2495-2504.
2.Yao Y, Luo Z, Li S, et al. Mvsnet: Depth inference for unstructured multi-view stereo[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 767-783.
3.Aanæs H, Jensen R R, Vogiatzis G, et al. Large-scale data for multiple-view stereopsis[J]. International Journal of Computer Vision, 2016, 120(2): 153-168.
4.Knapitsch A, Park J, Zhou Q Y, et al. Tanks and temples: Benchmarking large-scale scene reconstruction[J]. ACM Transactions on Graphics (ToG), 2017, 36(4): 1-13.
更多干货
欢迎加入【3D视觉工坊】交流群,方向涉及3D视觉、计算机视觉、深度学习、vSLAM、激光SLAM、立体视觉、自动驾驶、点云处理、三维重建、多视图几何、结构光、多传感器融合、VR/AR、学术交流、求职交流等。工坊致力于干货输出,为3D领域贡献自己的力量!欢迎大家一起交流成长~
添加小助手微信:CV_LAB,备注学校/公司+姓名+研究方向即可加入工坊一起学习进步。















 3593
3593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









