







之前写完了
David LEE:卡尔曼滤波:从入门到精通zhuanlan.zhihu.com之后一直说要写非线性情况下的推导。但后来想想,EKF不过就是做了一阶泰勒展开而已,要写成一篇文章实在是太短,感觉也没有太多干货,就一直没有动笔。最近在看 《概率机器人》,觉得关于贝叶斯滤波器确实也可以稍作总结,于是就写了这篇卡尔曼滤波家族。
本文对于扩展卡尔曼滤波、无迹卡尔曼滤波仅仅做了一些简要介绍,不再想上次的文章那样做详细地推导了。但只要看过之前写的卡尔曼滤波,相信这篇文章对于你来说也是很好理解的。
本文配图均来自《概率机器人》
扩展卡尔曼滤波
假设状态转移概率和测量概率分别由非线性函数g和h控制,而不再是一个线性变换:
这种情况下,由于线性变换的关系不在了,因此概率分布也不再是高斯分布。整个系统不再有闭式解,这是最让人头疼的。
而EKF 的主要思想就是线性化:通过一个在高斯函数的均值处与非线性函数g相切的线性函数来近似g。
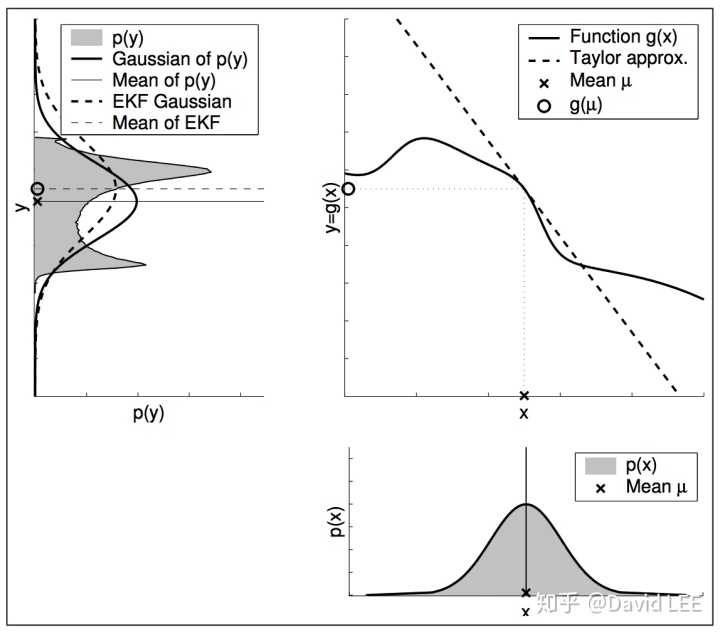
线性化的主要优点就是效率,一旦对g和h进行了线性化,KEF和KF就是等效的。
EKF采用一阶泰勒展开的方式来进行线性化,其根据g的值和斜率构造一个函数g的线性近似函数:
线性点的选择依据的是在线性化点附近自变量最有可能的状态。对于高斯函数,最可能的状态自然就是后验的均值
同理,将测量函数h线性化,有
最后,整个EKF算法的流程如下&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1391
1391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









