







ps0
求 d f ( X Y ) df(XY) df(XY)

求
d
(
X
−
1
)
d(X^{-1})
d(X−1)
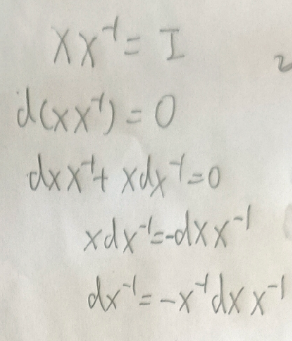
求
∇
f
(
x
T
A
x
)
\nabla f(x^TAx)
∇f(xTAx)

求
∇
2
f
(
x
T
A
x
)
\nabla^2 f(x^TAx)
∇2f(xTAx)

求
∇
g
(
a
⊤
x
)
∇
2
g
(
a
⊤
x
)
\nabla g\left(a^{\top} x\right) \quad \nabla^{2} g\left(a^{\top} x\right)
∇g(a⊤x)∇2g(a⊤x)

ps1
最小二乘法是没有局部最优的,所以可以根据损失函数的导数算出最小值。

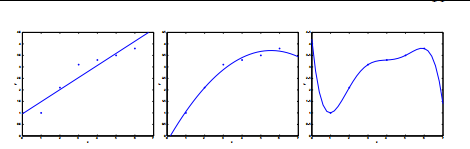
上图从左至右展示了欠拟合到过拟合的过程,为了控制线性回归,使它不至于欠拟合或者过拟合,提出了local weighted linear regression
它的思想是用样本点的x值和待预测点的x值之间的距离来衡量样本点的权重。
权重函数为
w
(
i
)
=
exp
(
−
(
x
(
i
)
−
x
)
2
2
τ
2
)
w^{(i)}=\exp \left(-\frac{\left(x^{(i)}-x\right)^{2}}{2 \tau^{2}}\right)
w(i)=exp(−2τ2(x(i)−x)2)
这里权重函数和高斯分布函数很相似,
τ
\tau
τ(tau)越大权重越分散,模型越倾向于过拟合。
这里补充一个高斯密函函数的积分为1的证明

如果x是向量则
w
(
i
)
=
exp
(
−
(
x
(
i
)
−
x
)
T
(
x
(
i
)
−
x
)
/
(
2
τ
2
)
)
w^{(i)}=\exp \left(-\left(x^{(i)}-x\right)^{T}\left(x^{(i)}-x\right) /\left(2 \tau^{2}\right)\right)
w(i)=exp(−(x(i)−x)T(x(i)−x)/(2τ2))。
这时一个non-parametric模型,因为每次为x预测y值都需要取出所有数据或者近邻数据来计算权重。而普通的线性回归是一个parametric模型,因为参数是固定的。
-
最小二乘法的概率解释
补充知识:两个独立的随机变量之和Z=X+Y的概率密度函数为 f Z ( z ) = ∫ − ∞ + ∞ f 1 ( x ) f 2 ( z − x ) d x f_{Z}(z)=\int_{-\infty}^{+\infty} f_{1}(x) f_{2}(z-x) d x fZ(z)=∫−∞+∞f1(x)f2(z−x)dx
中心极限定律:有n个分布相同并且均值为a,方差为 σ 2 \sigma^{2} σ2的随机变量,他们的平均值的满足分布
x ˉ → N ( a , σ 2 n ) \bar{x} \rightarrow N\left(a, \frac{\sigma^{2}}{n}\right) xˉ→N(a,nσ2)
假设每个目标变量和输入变量满足:
y ( i ) = θ T x ( i ) + ϵ ( i ) y^{(i)}=\theta^{T} x^{(i)}+\epsilon^{(i)} y(i)=θTx(i)+ϵ(i)
其中 ϵ ( i ) \epsilon^{(i)} ϵ(i)是高斯分布,并且满足独立同分布假设(IID),那么 y ( i ) y^{(i)} y(i)应该满足
p ( y ( i ) ∣ x ( i ) ; θ ) = 1 2 π σ exp ( − ( y ( i ) − θ T x ( i ) ) 2 2 σ 2 ) p\left(y^{(i)} \mid x^{(i)} ; \theta\right)=\frac{1}{\sqrt{2 \pi} \sigma} \exp \left(-\frac{\left(y^{(i)}-\theta^{T} x^{(i)}\right)^{2}}{2 \sigma^{2}}\right) p(y(i)∣x(i);θ)=2πσ1exp(−2σ2(y(i)−θTx(i))2) 左边的符号叫做 the distribution of y(i) given x(i) and parameterized by θ。 然后利用所有样本求log liklihood 得到 m log 1 2 π σ − 1 σ 2 ⋅ 1 2 ∑ i = 1 m ( y ( i ) − θ T x ( i ) ) 2 m \log \frac{1}{\sqrt{2 \pi} \sigma}-\frac{1}{\sigma^{2}} \cdot \frac{1}{2} \sum_{i=1}^{m}\left(y^{(i)}-\theta^{T} x^{(i)}\right)^{2} mlog2πσ1−σ21⋅21∑i=1m(y(i)−θTx(i))2, 可以看出最大化log liklihood等于最小化最小二乘法损失函数。 -
Logistic regression
利用一个sigmoid函数将线性模型的输出限制在0到1之间
h θ ( x ) = g ( θ T x ) = 1 1 + e − θ T x h_{\theta}(x)=g\left(\theta^{T} x\right)=\frac{1}{1+e^{-\theta^{T} x}} hθ(x)=g(θTx)=1+e−θTx1,其中h表示hypothese。 它的log likilihood 导数为
∂ ∂ θ j ℓ ( θ ) = ( y − h θ ( x ) ) x j \begin{aligned} \frac{\partial}{\partial \theta_{j}} \ell(\theta) &=\left(y-h_{\theta}(x)\right) x_{j} \end{aligned} ∂θj∂ℓ(θ)=(y−hθ(x))xj
由于它不像最小二乘法那样可以直接用normal equation求出导数为0点,所以只能用梯度法或牛顿法。
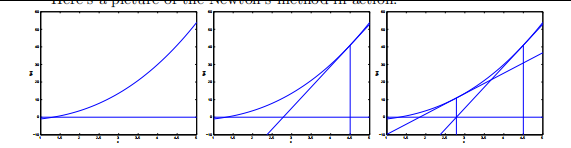
牛顿法是用迭代法求
f
(
θ
)
f(\theta)
f(θ)的零点:
θ
:
=
θ
−
f
(
θ
)
f
′
(
θ
)
\theta:=\theta-\frac{f(\theta)}{f^{\prime}(\theta)}
θ:=θ−f′(θ)f(θ)
可以理解为当前点的高度除以斜率就得到了在水平方向需要移动的距离。
把牛顿法用于对数似然的导数:
θ
:
=
θ
−
ℓ
′
(
θ
)
ℓ
′
′
(
θ
)
\theta:=\theta-\frac{\ell^{\prime}(\theta)}{\ell^{\prime \prime}(\theta)}
θ:=θ−ℓ′′(θ)ℓ′(θ)
在多维情况下,牛顿法写成
θ
:
=
θ
−
H
−
1
∇
θ
ℓ
(
θ
)
\theta:=\theta-H^{-1} \nabla_{\theta} \ell(\theta)
θ:=θ−H−1∇θℓ(θ)
其中
H
i
j
=
∂
2
ℓ
(
θ
)
∂
θ
i
∂
θ
j
H_{i j}=\frac{\partial^{2} \ell(\theta)}{\partial \theta_{i} \partial \theta_{j}}
Hij=∂θi∂θj∂2ℓ(θ)
在维数很少的情况下,牛顿法因为是二次收敛,所以速度很快。但是当维数增加时,由于要求海森矩阵的逆,所以计算量很大,这时因考虑用梯度法。
p阶收敛: 设迭代过程 x k + 1 = f ( x k ) x_{k+1}=f\left(x_{k}\right) xk+1=f(xk) 收敛于 f ( x ) = 0 f(x)=0 f(x)=0 的根 x 0 x_{0} x0
每一步的误差为 e k = ∣ x 0 − x k ∣ e_{k}=\left|x_{0}-x_{k}\right| ek=∣x0−xk∣ 那么存在常数c使得迭代次数k无限大的时候有 lim k → + ∞ e k + 1 e k p = c \lim _{k \rightarrow+\infty} \frac{e_{k+1}}{e_{k}^{p}}=c limk→+∞ekpek+1=c
-
感知机
还有一种方法可以把线性模型用于二分类任务,那就是强制模型输出0或1,即 g ( z ) = { 1 if z ≥ 0 0 if z < 0 g(z)= \begin{cases}1 & \text { if } z \geq 0 \\ 0 & \text { if } z<0\end{cases} g(z)={10 if z≥0 if z<0, h θ ( x ) = g ( θ T x ) h_{\theta}(x)=g\left(\theta^{T} x\right) hθ(x)=g(θTx)。参数更新公式为:
θ j : = θ j + α ( y ( i ) − h θ ( x ( i ) ) ) x j ( i ) \theta_{j}:=\theta_{j}+\alpha\left(y^{(i)}-h_{\theta}\left(x^{(i)}\right)\right) x_{j}^{(i)} θj:=θj+α(y(i)−hθ(x(i)))xj(i)
可以看出只有预测出错的点会给出梯度,并且梯度方向就是x的方向。

-
指数族
p ( y ; η ) = b ( y ) exp ( η T T ( y ) − a ( η ) ) p(y ; \eta)=b(y) \exp \left(\eta^{T} T(y)-a(\eta)\right) p(y;η)=b(y)exp(ηTT(y)−a(η)) 在指数族分布中,唯一的参数是 η \eta η(eta), 它也叫做natural parammeter. 一般令 T ( y ) T(y) T(y)等于y。 a ( η ) a(\eta) a(η)叫做log partition function。
伯努利(二项)分布和高斯分布等很多分布都可以写成指数族分布的形式,比如
p ( y ; ϕ ) = ϕ y ( 1 − ϕ ) 1 − y = exp ( y log ϕ + ( 1 − y ) log ( 1 − ϕ ) ) = exp ( ( log ( ϕ 1 − ϕ ) ) y + log ( 1 − ϕ ) ) \begin{aligned} p(y ; \phi) &=\phi^{y}(1-\phi)^{1-y} \\ &=\exp (y \log \phi+(1-y) \log (1-\phi)) \\ &=\exp \left(\left(\log \left(\frac{\phi}{1-\phi}\right)\right) y+\log (1-\phi)\right) \end{aligned} p(y;ϕ)=ϕy(1−ϕ)1−y=exp(ylogϕ+(1−y)log(1−ϕ))=exp((log(1−ϕϕ))y+log(1−ϕ))
其中 η = log ( ϕ / ( 1 − ϕ ) ) \eta=\log (\phi /(1-\phi)) η=log(ϕ/(1−ϕ)),反过来 ϕ = 1 / ( 1 + e − η ) \phi=1 /\left(1+e^{-\eta}\right) ϕ=1/(1+e−η)
T ( y ) = y a ( η ) = − log ( 1 − ϕ ) = log ( 1 + e η ) b ( y ) = 1 \begin{aligned} T(y) &=y \\ a(\eta) &=-\log (1-\phi) \\ &=\log \left(1+e^{\eta}\right) \\ b(y) &=1 \end{aligned} T(y)a(η)b(y)=y=−log(1−ϕ)=log(1+eη)=1为什么要使用指数族分布呢,因为在用MLE(最大似然估计)计算 η \eta η时,可以保证 η \eta η有全局最优值。 并且指数族分布的期望可以简单的表示为log partition function的一阶导数,方差可以表示为log partition function的二阶导数。
在建立generalized linear model 时,我们有以下三个假设,第一个y满足以 η \eta η为参数的指数族分布,第二个是最终得到的用来预测y值的hypothesis 满足 h ( x ) = E [ T ( y ) ∣ x ] h(x)=\mathrm{E}[T(y) \mid x] h(x)=E[T(y)∣x],但是对于回归和二分类来说, T ( y ) = y T(y)=y T(y)=y,第三是把 η \eta η reparameterize 成 θ T x {\theta}^{T}x θTx
这里还引入两个术语,我们把 g ( η ) = E [ T ( y ) ; η ] g(\eta)=\mathrm{E}[T(y) ; \eta] g(η)=E[T(y);η]叫做response function, 把它的反函数叫做link function.
利用MLE求 θ \theta θ的梯度:

如果待预测的y是二值的,我们假设它满足二项分布,它的期望是 ϕ \phi ϕ, 又根据 ϕ = 1 / ( 1 + e − η ) \phi=1 /\left(1+e^{-\eta}\right) ϕ=1/(1+e−η),可以推出h(x)应该为 1 / ( 1 + e − θ T x ) 1 /\left(1+e^{-\theta^Tx}\right) 1/(1+e−θTx)正好是Logistic regression的hypothesis.

注意 h θ ( x ) h_{\theta}(x) hθ(x)是作为一个参数(T(y)的期望)存在于概率密度函数中,而关于 θ \theta θ的损失函数是根据最大似然得到的。比如线性回归中概率密度是高斯分布,而 h θ ( x ) h_{\theta}(x) hθ(x)就相当于参数 μ \mu μ。
再比如在二项分布 ϕ y ( 1 − ϕ ) 1 − y \phi^{y}(1-\phi)^{1-y} ϕy(1−ϕ)1−y中, h θ ( x ) h_{\theta}(x) hθ(x)就相当于 ϕ \phi ϕ.多项分布的概率为 p ( y ; ϕ ) = ϕ 1 1 { y = 1 } ϕ 2 1 { y = 2 } ⋯ ϕ k 1 { y = k } = ϕ 1 1 { y = 1 } ϕ 2 1 { y = 2 } ⋯ ϕ k 1 − ∑ i = 1 k − 1 1 { y = i } = ϕ 1 ( T ( y ) ) 1 ϕ 2 ( T ( y ) ) 2 ⋯ ϕ k 1 − ∑ i = 1 k − 1 ( T ( y ) ) i = exp ( ( T ( y ) ) 1 log ( ϕ 1 ) + ( T ( y ) ) 2 log ( ϕ 2 ) + ⋯ + ( 1 − ∑ i = 1 k − 1 ( T ( y ) ) i ) log ( ϕ k ) ) = exp ( ( T ( y ) ) 1 log ( ϕ 1 / ϕ k ) + ( T ( y ) ) 2 log ( ϕ 2 / ϕ k ) + ⋯ + ( T ( y ) ) k − 1 log ( ϕ k − 1 / ϕ k ) + log ( ϕ k ) ) = b ( y ) exp ( η T T ( y ) − a ( η ) ) \begin{aligned} p(y ; \phi)=& \phi_{1}^{1\{y=1\}} \phi_{2}^{1\{y=2\}} \cdots \phi_{k}^{1\{y=k\}} \\=& \phi_{1}^{1\{y=1\}} \phi_{2}^{1\{y=2\}} \cdots \phi_{k}^{1-\sum_{i=1}^{k-1} 1\{y=i\}} \\=& \phi_{1}^{(T(y))_{1}} \phi_{2}^{(T(y))_{2}} \cdots \phi_{k}^{1-\sum_{i=1}^{k-1}(T(y))_{i}} \\=& \exp \left((T(y))_{1} \log \left(\phi_{1}\right)+(T(y))_{2} \log \left(\phi_{2}\right)+\right.\\ &\left.\cdots+\left(1-\sum_{i=1}^{k-1}(T(y))_{i}\right) \log \left(\phi_{k}\right)\right) \\=& \exp \left((T(y))_{1} \log \left(\phi_{1} / \phi_{k}\right)+(T(y))_{2} \log \left(\phi_{2} / \phi_{k}\right)+\right.\\ &\left.\cdots+(T(y))_{k-1} \log \left(\phi_{k-1} / \phi_{k}\right)+\log \left(\phi_{k}\right)\right) \\=& b(y) \exp \left(\eta^{T} T(y)-a(\eta)\right) \end{aligned} p(y;ϕ)======ϕ11{y=1}ϕ21{y=2}⋯ϕk1{y=k}ϕ11{y=1}ϕ21{y=2}⋯ϕk1−∑i=1k−11{y=i}ϕ1(T(y))1ϕ2(T(y))2⋯ϕk1−∑i=1k−1(T(y))iexp((T(y))1log(ϕ1)+(T(y))2log(ϕ2)+⋯+(1−i=1∑k−1(T(y))i)log(ϕk))exp((T(y))1log(ϕ1/ϕk)+(T(y))2log(ϕ2/ϕk)+⋯+(T(y))k−1log(ϕk−1/ϕk)+log(ϕk))b(y)exp(ηTT(y)−a(η))
其中
1
{
y
=
1
}
1\{y=1\}
1{y=1}在y等于1时为1,在y不等于1时为0.
T
(
y
)
T(y)
T(y)是根据y取值变化的独热向量,第三到第四个式子用到了换底公式
a
x
=
e
x
l
n
a
a^x=e^{xlna}
ax=exlna, 从上面的推导中还可以得到link function :
η
i
=
log
ϕ
i
ϕ
k
\eta_{i}=\log \frac{\phi_{i}}{\phi_{k}}
ηi=logϕkϕi , 并且
η
k
=
0
\eta_{k}=0
ηk=0进而得到response function :
ϕ
i
=
e
η
i
∑
j
=
1
k
e
η
j
\phi_{i}=\frac{e^{\eta_{i}}}{\sum_{j=1}^{k} e^{\eta_{j}}}
ϕi=∑j=1keηjeηi, 这里利用到
ϕ
1
+
.
.
.
ϕ
k
=
1
\phi_1+...\phi_k=1
ϕ1+...ϕk=1.
所以,最终的hypothesis应该为:
h
θ
(
x
)
=
E
[
T
(
y
)
∣
x
;
θ
]
=
[
ϕ
1
ϕ
2
⋮
ϕ
k
−
1
]
=
[
exp
(
θ
1
T
x
)
∑
j
=
1
k
exp
(
θ
j
T
x
)
exp
(
θ
2
T
x
)
∑
j
=
1
k
exp
(
θ
j
T
x
)
⋮
exp
(
θ
k
−
1
T
x
)
∑
j
=
1
k
exp
(
θ
j
T
x
)
]
\begin{aligned} h_{\theta}(x) &=\mathrm{E}[T(y) \mid x ; \theta] \\ &=\left[\begin{array}{c}\phi_{1} \\ \phi_{2} \\ \vdots \\ \phi_{k-1}\end{array}\right] \\ &=\left[\begin{array}{c}\frac{\exp \left(\theta_{1}^{T} x\right)}{\sum_{j=1}^{k} \exp \left(\theta_{j}^{T} x\right)} \\ \frac{\exp \left(\theta_{2}^{T} x\right)}{\sum_{j=1}^{k} \exp \left(\theta_{j}^{T} x\right)} \\ \vdots \\ \frac{\exp \left(\theta_{k-1}^{T} x\right)}{\sum_{j=1}^{k} \exp \left(\theta_{j}^{T} x\right)}\end{array}\right] \end{aligned}
hθ(x)=E[T(y)∣x;θ]=⎣⎢⎢⎢⎡ϕ1ϕ2⋮ϕk−1⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎢⎡∑j=1kexp(θjTx)exp(θ1Tx)∑j=1kexp(θjTx)exp(θ2Tx)⋮∑j=1kexp(θjTx)exp(θk−1Tx)⎦⎥⎥⎥⎥⎥⎥⎥⎤
这里省略了
ϕ
k
\phi_k
ϕk
- generative learning algorithms GDA
假设现在要对猫和狗进行,一种做法是分别对猫和狗进行建模,当碰到一个新动物时,看它和哪个模型更符合就把它分为哪个类,这种方法叫做generative learning,它相当于学习 p ( x ∣ y ) p(x \mid y) p(x∣y)和先验分布 p ( y ) p(y ) p(y). 而直接学习后验分布 p ( y ∣ x ) p(y \mid x) p(y∣x)的方法叫做discriminative learning。利用贝叶斯公式, p ( x ∣ y ) p(x \mid y) p(x∣y)和 p ( y ) p(y) p(y),可以得到后验分布 p ( y ∣ x ) = p ( x ∣ y ) p ( y ) p ( x ) p(y \mid x)=\frac{p(x \mid y) p(y)}{p(x)} p(y∣x)=p(x)p(x∣y)p(y),在二分类任务下 p ( x ) = p ( x ∣ y = 1 ) p ( y = 1 ) + p ( x ∣ y = 0 ) p ( y = 0 ) p(x)=p(x \mid y=1) p(y=1)+p(x \mid y=0)p(y=0) p(x)=p(x∣y=1)p(y=1)+p(x∣y=0)p(y=0). 预测还是基于后验概率进行的,因为即使特征和某一类别的模型很吻合,但是这个类别在样本中过于稀少,那么特征属于这个类的概率也不会太高,
arg max y p ( y ∣ x ) = arg max y p ( x ∣ y ) p ( y ) p ( x ) = arg max y p ( x ∣ y ) p ( y ) . \begin{aligned} \arg \max _{y} p(y \mid x) &=\arg \max _{y} \frac{p(x \mid y) p(y)}{p(x)} \\ &=\arg \max _{y} p(x \mid y) p(y) . \end{aligned} argymaxp(y∣x)=argymaxp(x)p(x∣y)p(y)=argymaxp(x∣y)p(y).
对于二项分布来说,假设每一个类别内x都满足均值不同但协方差相同的多元高斯分布,那么有
p
(
y
)
=
ϕ
y
(
1
−
ϕ
)
1
−
y
p
(
x
∣
y
=
0
)
=
1
(
2
π
)
n
/
2
∣
Σ
∣
1
/
2
exp
(
−
1
2
(
x
−
μ
0
)
T
Σ
−
1
(
x
−
μ
0
)
)
p
(
x
∣
y
=
1
)
=
1
(
2
π
)
n
/
2
∣
Σ
∣
1
/
2
exp
(
−
1
2
(
x
−
μ
1
)
T
Σ
−
1
(
x
−
μ
1
)
)
\begin{aligned} p(y) &=\phi^{y}(1-\phi)^{1-y} \\ p(x \mid y=0) &=\frac{1}{(2 \pi)^{n / 2}|\Sigma|^{1 / 2}} \exp \left(-\frac{1}{2}\left(x-\mu_{0}\right)^{T} \Sigma^{-1}\left(x-\mu_{0}\right)\right) \\ p(x \mid y=1) &=\frac{1}{(2 \pi)^{n / 2}|\Sigma|^{1 / 2}} \exp \left(-\frac{1}{2}\left(x-\mu_{1}\right)^{T} \Sigma^{-1}\left(x-\mu_{1}\right)\right) \end{aligned}
p(y)p(x∣y=0)p(x∣y=1)=ϕy(1−ϕ)1−y=(2π)n/2∣Σ∣1/21exp(−21(x−μ0)TΣ−1(x−μ0))=(2π)n/2∣Σ∣1/21exp(−21(x−μ1)TΣ−1(x−μ1))
最大化联合概率密度
p
(
x
,
y
)
p(x,y)
p(x,y)的对数似然得到
ϕ
=
1
m
∑
i
=
1
m
1
{
y
(
i
)
=
1
}
μ
0
=
∑
i
=
1
m
1
{
y
(
i
)
=
0
}
x
(
i
)
∑
i
=
1
m
1
{
y
(
i
)
=
0
}
μ
1
=
∑
i
=
1
m
1
{
y
(
i
)
=
1
}
x
(
i
)
∑
i
=
1
m
1
{
y
(
i
)
=
1
}
Σ
=
1
m
∑
i
=
1
m
(
x
(
i
)
−
μ
y
(
i
)
)
(
x
(
i
)
−
μ
y
(
i
)
)
T
\begin{aligned} \phi &=\frac{1}{m} \sum_{i=1}^{m} 1\left\{y^{(i)}=1\right\} \\ \mu_{0} &=\frac{\sum_{i=1}^{m} 1\left\{y^{(i)}=0\right\} x^{(i)}}{\sum_{i=1}^{m} 1\left\{y^{(i)}=0\right\}} \\ \mu_{1} &=\frac{\sum_{i=1}^{m} 1\left\{y^{(i)}=1\right\} x^{(i)}}{\sum_{i=1}^{m} 1\left\{y^{(i)}=1\right\}} \\ \Sigma &=\frac{1}{m} \sum_{i=1}^{m}\left(x^{(i)}-\mu_{y^{(i)}}\right)\left(x^{(i)}-\mu_{y^{(i)}}\right)^{T} \end{aligned}
ϕμ0μ1Σ=m1i=1∑m1{y(i)=1}=∑i=1m1{y(i)=0}∑i=1m1{y(i)=0}x(i)=∑i=1m1{y(i)=1}∑i=1m1{y(i)=1}x(i)=m1i=1∑m(x(i)−μy(i))(x(i)−μy(i))T
用MLE证明以上式子成立

还是以二项分布为例,如果把
p
(
y
=
1
∣
x
;
ϕ
,
μ
0
,
μ
1
,
Σ
)
p\left(y=1 \mid x ; \phi, \mu_{0}, \mu_{1}, \Sigma\right)
p(y=1∣x;ϕ,μ0,μ1,Σ)看成是x的函数,那么有
p
(
y
=
1
∣
x
;
ϕ
,
Σ
,
μ
0
,
μ
1
)
=
1
1
+
exp
(
−
θ
T
x
)
p\left(y=1 \mid x ; \phi, \Sigma, \mu_{0}, \mu_{1}\right)=\frac{1}{1+\exp \left(-\theta^{T} x\right)}
p(y=1∣x;ϕ,Σ,μ0,μ1)=1+exp(−θTx)1,可以看出二项分布的GDA可以导出losgistic回归,说明GDA拥有更强的假设。 在数据量小的时候可以选择GDA, 因为它提供更多先验知识,而数据量大的时候应该选择logistic回归。
证明GDA可以写成logistic回归

证明logistic回归 的海森矩阵为半正定

注意,这里
∑
i
m
(
y
(
i
)
−
g
(
η
(
i
)
)
)
x
j
(
i
)
\sum_{i}^{m}\left(y^{(i)}-g(\eta^{(i)})\right) x_{j}^{(i)}
i∑m(y(i)−g(η(i)))xj(i) 应该写成
∑
i
m
(
g
(
η
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
\sum_{i}^{m}\left(g(\eta^{(i)})-y^{(i)}\right) x_{j}^{(i)}
i∑m(g(η(i))−y(i))xj(i)这样才能 保证H是半正定的。另外
a
′
(
η
)
=
g
(
η
)
a^{\prime}(\eta)=g (\eta)
a′(η)=g(η)对所有指数族都是成立的,因为它是指数族的性质之一。
牛顿法中的一阶导数J,在多样本的形式下可以写成 X ⊤ ( g ( η ) − Y ) X^{\top}(g(\eta)-Y) X⊤(g(η)−Y)
绘制GDA的决策边界需要首先将其转换成等价的logistic回归

其中紫色的是GDA,红色的是logistic。
现在有一个问题,如果训练集中只有部分正样本有标签y=1, 而其它正样本和所有负样本的标签都为0,那么应该如何训练模型?假设样本的真正标签为1,首先应该证明
P
(
y
(
i
)
=
1
∣
x
(
i
)
)
P\left(y^{(i)}=1 \mid x^{(i)}\right)
P(y(i)=1∣x(i))和
p
(
t
(
i
)
=
1
∣
x
(
i
)
)
p\left(t^{(i)}=1 | x^{(i)}\right)
p(t(i)=1∣x(i)) 只差一个常数项
α
\alpha
α


红色是用t标签来训练,紫色是用y标签训练,而黑色边界是先用y标签训练,然后再用验证集得到
α
\alpha
α, 注意如果是对正样本的概率进行排序,不需要知道
α
\alpha
α
证明指数族的期望等于log-partition function函数的一阶导数,证明方差为其二阶导数, 证明指数族的 negative log-likelihood的海森矩阵是半正定

- 泊松分布
假设医院平均一天诞生 λ \lambda λ个,如何计算每天出生数k等于不同值时的概率分布呢?
一个方法是把一天分成86400秒,然后用二项分布来建模
86400 ! ( 86400 − k ) ! × k ! × ( λ 86400 ) k ( 1 − λ 86400 ) 86400 − k \frac{86400 !}{(86400-k) ! \times k !} \times\left(\frac{\lambda}{86400}\right)^{k}\left(1-\frac{\lambda}{86400}\right)^{86400-k} (86400−k)!×k!86400!×(86400λ)k(1−86400λ)86400−k
进一步,把一天的时间进行无线的划分,就会得到一个极限,这个极限就是泊松分布
n ! ( n − k ) ! × k ! × ( λ n ) k ( 1 − λ n ) n − k = 1 ( 1 − 1 n ) ( 1 − 2 n ) … ( 1 − k − 1 n ) λ k 1 k ! ( 1 − λ n ) n ( 1 − λ n ) k ≈ 1 × λ k 1 k ! e − λ 1 = λ k e − λ k ! \frac{n !}{(n-k) ! \times k !} \times\left(\frac{\lambda}{n}\right)^{k}\left(1-\frac{\lambda}{n}\right)^{n-k}=1\left(1-\frac{1}{n}\right)\left(1-\frac{2}{n}\right) \ldots\left(1-\frac{k-1}{n}\right) \lambda^{k} \frac{1}{k !} \frac{\left(1-\frac{\lambda}{n}\right)^{n}}{\left(1-\frac{\lambda}{n}\right)^{k}} \approx 1 \times \lambda^{k} \frac{1}{k !} \frac{e^{-\lambda}}{1}=\frac{\lambda^{k} e^{-\lambda}}{k !} (n−k)!×k!n!×(nλ)k(1−nλ)n−k=1(1−n1)(1−n2)…(1−nk−1)λkk!1(1−nλ)k(1−nλ)n≈1×λkk!11e−λ=k!λke−λ
 把泊松分布写成指数族分布:
把泊松分布写成指数族分布:

- local weighted linear regression
损失函数
J
(
θ
)
=
1
2
∑
i
=
1
m
w
(
i
)
(
θ
T
x
(
i
)
−
y
(
i
)
)
2
J(\theta)=\frac{1}{2} \sum_{i=1}^{m} w^{(i)}\left(\theta^{T} x^{(i)}-y^{(i)}\right)^{2}
J(θ)=21∑i=1mw(i)(θTx(i)−y(i))2
和线性回归一样,可以直接求出损失函数的极小值。

假设每个example都服从拥有不同
σ
\sigma
σ的高斯分布,可以证明
其MLE等价于一个locally weighted linear regression 问题

实现一个
w
(
i
)
=
exp
(
−
∥
x
(
i
)
−
x
∥
2
2
2
τ
2
)
w^{(i)}=\exp \left(-\frac{\left\|x^{(i)}-x\right\|_{2}^{2}}{2 \tau^{2}}\right)
w(i)=exp(−2τ2∥x(i)−x∥22)的locally weighted linear regression
tau=1

tau=0.5

tau=0.1

PS2
- Naive Bayes
在进行垃圾邮件分类时,把文本看成是一个字典大小的向量,其中每个值代表对应的单词是否出现在邮件中。
x = [ 1 0 0 ⋮ 1 ⋮ 0 ] a aardvark aardwolf ⋮ buy ⋮ zygmurgy x=\left[\begin{array}{c}1 \\ 0 \\ 0 \\ \vdots \\ 1 \\ \vdots \\ 0\end{array}\right] \quad \begin{aligned}&\text { a } \\&\text { aardvark } \\&\text { aardwolf } \\&\vdots \\&\text { buy } \\&\vdots \\&\text { zygmurgy }\end{aligned} x=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡100⋮1⋮0⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤ a aardvark aardwolf ⋮ buy ⋮ zygmurgy
假设词典大小为5000, 把x看成一个多项式分布,那么给定一个y值需要建模 2 5000 2^{5000} 25000个不同的概率值,这显然是不现实的。在naive bayes 假设中,给定y值的情况下,每个 x i x_{i} xi都是独立的,所以有
p ( x 1 , … , x 50000 ∣ y ) = ∏ i = 1 n p ( x i ∣ y ) p\left(x_{1}, \ldots, x_{50000} \mid y\right)\quad=\prod_{i=1}^{n} p\left(x_{i} \mid y\right) p(x1,…,x50000∣y)=∏i=1np(xi∣y)
用MLE得到
ϕ j ∣ y = 1 = ∑ i = 1 m 1 { x j ( i ) = 1 ∧ y ( i ) = 1 } ∑ i = 1 m 1 { y ( i ) = 1 } ϕ j ∣ y = 0 = ∑ i = 1 m 1 { x j ( i ) = 1 ∧ y ( i ) = 0 } ∑ i = 1 m 1 { y ( i ) = 0 } ϕ y = ∑ i = 1 m 1 { y ( i ) = 1 } m \begin{aligned} \phi_{j \mid y=1} &=\frac{\sum_{i=1}^{m} 1\left\{x_{j}^{(i)}=1 \wedge y^{(i)}=1\right\}}{\sum_{i=1}^{m} 1\left\{y^{(i)}=1\right\}} \\ \phi_{j \mid y=0} &=\frac{\sum_{i=1}^{m} 1\left\{x_{j}^{(i)}=1 \wedge y^{(i)}=0\right\}}{\sum_{i=1}^{m} 1\left\{y^{(i)}=0\right\}} \\ \phi_{y} &=\frac{\sum_{i=1}^{m} 1\left\{y^{(i)}=1\right\}}{m} \end{aligned} ϕj∣y=1ϕj∣y=0ϕy=∑i=1m1{y(i)=1}∑i=1m1{xj(i)=1∧y(i)=1}=∑i=1m1{y(i)=0}∑i=1m1{xj(i)=1∧y(i)=0}=m∑i=1m1{y(i)=1}
为了防止某一个
ϕ
\phi
ϕ为0导致整个概率为0,这里把
ϕ
\phi
ϕ的分子加1,即
ϕ
j
∣
y
=
1
=
∑
i
=
1
m
1
{
x
j
(
i
)
=
1
∧
y
(
i
)
=
1
}
+
1
∑
i
=
1
m
1
{
y
(
i
)
=
1
}
+
2
\phi_{j \mid y=1}=\frac{\sum_{i=1}^{m} 1\left\{x_{j}^{(i)}=1 \wedge y^{(i)}=1\right\}+1}{\sum_{i=1}^{m} 1\left\{y^{(i)}=1\right\}+2}
ϕj∣y=1=∑i=1m1{y(i)=1}+2∑i=1m1{xj(i)=1∧y(i)=1}+1
ϕ
j
∣
y
=
0
=
∑
i
=
1
m
1
{
x
j
(
i
)
=
1
∧
y
(
i
)
=
0
}
+
1
∑
i
=
1
m
1
{
y
(
i
)
=
0
}
+
2
\phi_{j \mid y=0}=\frac{\sum_{i=1}^{m} 1\left\{x_{j}^{(i)}=1 \wedge y^{(i)}=0\right\}+1}{\sum_{i=1}^{m} 1\left\{y^{(i)}=0\right\}+2}
ϕj∣y=0=∑i=1m1{y(i)=0}+2∑i=1m1{xj(i)=1∧y(i)=0}+1
分母加2是因为
x
j
x_j
xj是二项分布,只有0和1两种取值。这种操作叫做laplace smoothing.
在multinomial event model 中,特征向量的长度等于文本长度。每个
x
j
x_j
xj都是满足一个多项式分布,且这个分布对所有j相同。利用MLE可以得到
ϕ
k
∣
y
=
1
=
∑
i
=
1
m
∑
j
=
1
n
i
1
{
x
j
(
i
)
=
k
∧
y
(
i
)
=
1
}
∑
i
=
1
m
1
{
y
(
i
)
=
1
}
n
i
ϕ
k
∣
y
=
0
=
∑
i
=
1
m
∑
j
=
1
n
i
1
{
x
j
(
i
)
=
k
∧
y
(
i
)
=
0
}
∑
i
=
1
m
1
{
y
(
i
)
=
0
}
n
i
ϕ
y
=
∑
i
=
1
m
1
{
y
(
i
)
=
1
}
m
.
\begin{aligned} \phi_{k \mid y=1} &=\frac{\sum_{i=1}^{m} \sum_{j=1}^{n_{i}} 1\left\{x_{j}^{(i)}=k \wedge y^{(i)}=1\right\}}{\sum_{i=1}^{m} 1\left\{y^{(i)}=1\right\} n_{i}} \\ \phi_{k \mid y=0} &=\frac{\sum_{i=1}^{m} \sum_{j=1}^{n_{i}} 1\left\{x_{j}^{(i)}=k \wedge y^{(i)}=0\right\}}{\sum_{i=1}^{m} 1\left\{y^{(i)}=0\right\} n_{i}} \\ \phi_{y} &=\frac{\sum_{i=1}^{m} 1\left\{y^{(i)}=1\right\}}{m} . \end{aligned}
ϕk∣y=1ϕk∣y=0ϕy=∑i=1m1{y(i)=1}ni∑i=1m∑j=1ni1{xj(i)=k∧y(i)=1}=∑i=1m1{y(i)=0}ni∑i=1m∑j=1ni1{xj(i)=k∧y(i)=0}=m∑i=1m1{y(i)=1}.
可以看到和之前的Bernoulli event model不同之处在于,文本中同一个词要被计算多次。 如果event model 要进行smoothing, 分母要加
∣
V
∣
|V|
∣V∣即字典大小,因为文本中的每一个单词
x
j
x_j
xj是一个多项分布
-
SVM
svm的主要思想是令训练集中每个被正确分类的example离决策边界或者说seperating hyperplane的距离越大越好。SVM中分类器的形式为 h w , b ( x ) = g ( w T x + b ) h_{w, b}(x)=g\left(w^{T} x+b\right) hw,b(x)=g(wTx+b),和感知机的形式类似,只是当 z z z小于0时, g ( z ) = − 1 g(z)=-1 g(z)=−1, 目的是方便定义每个样本的functional margin
γ ^ ( i ) = y ( i ) ( w T x + b ) \hat{\gamma}^{(i)}=y^{(i)}\left(w^{T} x+b\right) γ^(i)=y(i)(wTx+b)
而对于整个训练集的functional margin 为
γ ^ = min i = 1 , … , m γ ^ ( i ) \hat{\gamma}=\min _{i=1, \ldots, m} \hat{\gamma}^{(i)} γ^=mini=1,…,mγ^(i)
svm的目标就是最大化 γ ^ \hat{\gamma} γ^
决策边界可以表示成 w T x + b = 0 w^{T} x+b=0 wTx+b=0, 可以看出w和b同时乘以一个常数不会改变超平面,但是会改变funtional margin, 所以实际上functional margin 和样本点到超平面的距离差了一个尺度。所以这里引入了geometric margin,用来精确表示样本到超平面距离
γ ( i ) = y ( i ) ( ( w ∥ w ∥ ) T x ( i ) + b ∥ w ∥ ) \gamma^{(i)}=y^{(i)}\left(\left(\frac{w}{\|w\|}\right)^{T} x^{(i)}+\frac{b}{\|w\|}\right) γ(i)=y(i)((∥w∥w)Tx(i)+∥w∥b)
即样本点超平面法向量上的投影减去超平面到原点的距离。 当限制 ∥ w ∥ = 1 \|w\|=1 ∥w∥=1时,geometric margin和functional margin 相等,所以svm可以写成优化问题:
max γ , w , b γ \max _{\gamma, w, b} \gamma maxγ,w,bγ
s.t. y ( i ) ( w T x ( i ) + b ) ≥ γ , i = 1 , … , m \quad y^{(i)}\left(w^{T} x^{(i)}+b\right) \geq \gamma, \quad i=1, \ldots, m y(i)(wTx(i)+b)≥γ,i=1,…,m ∥ w ∥ = 1 \|w\|=1 ∥w∥=1.
或者不加限制
max γ , w , b γ \max _{\gamma, w, b} \gamma maxγ,w,bγ
s.t. y ( i ) ( w T x ( i ) + b ) ∥ w ∥ ≥ γ , i = 1 , … , m \quad y^{(i)}\frac{\left(w^{T} x^{(i)}+b\right)}{\|w\|} \geq \gamma, \quad i=1, \ldots, m y(i)∥w∥(wTx(i)+b)≥γ,i=1,…,m .
为了把 ∥ w ∥ {\|w\|} ∥w∥从约束中去掉,可以写成
max γ , w , b γ ^ ∥ w ∥ \max _{\gamma, w, b} \frac{\hat{\gamma}}{\|w\|} maxγ,w,b∥w∥γ^
s.t. y ( i ) ( w T x ( i ) + b ) ≥ γ ^ , i = 1 , … , m y^{(i)}\left(w^{T} x^{(i)}+b\right) \geq \hat{\gamma}, \quad i=1, \ldots, m y(i)(wTx(i)+b)≥γ^,i=1,…,m
但是上面三种情况要么约束不是凸函数,要么优化目标不是凸函数,注意到w和b同时乘以一个常数都不会影响结果,所以可以令 γ ^ = 1 \hat{\gamma}=1 γ^=1, 又最大化 1 / ∥ w ∥ 1 /\|w\| 1/∥w∥相当于最小化 ∥ w ∥ 2 \|w\|^{2} ∥w∥2,所以最终的优化问题写成
min γ , w , b 1 2 ∥ w ∥ 2 s.t. y ( i ) ( w T x ( i ) + b ) ≥ 1 , i = 1 , … , m \begin{aligned} \min _{\gamma, w, b} & \frac{1}{2}\|w\|^{2} \\ \text { s.t. } \quad y^{(i)}\left(w^{T} x^{(i)}+b\right) \geq 1, \quad i=1, \ldots, m \end{aligned} γ,w,bmin s.t. y(i)(wTx(i)+b)≥1,i=1,…,m21∥w∥2
拉格朗日乘子法
假设有自变量x和y,给定约束条件g(x,y)=c,要求f(x,y)在约束g下的极值。
画出f(x,y)的等高线以及g(x,y)=c的曲线,可以看出当f(x,y)逐渐缩小至与g(x,y)=c相切时达到极值,所以在该极值点,f和g的梯度方向应该一致,即
∇
f
=
λ
∇
g
\nabla f=\lambda \nabla g
∇f=λ∇g
g
(
x
,
y
)
=
0
g(x, y)=0
g(x,y)=0


如果有多个约束呢? 上图中平面和球面分别对应两个等式约束h1和h2,可行域就是他们俩相交的圆。不难证明该圆上某点的切线必须同时满足和h1,h2,f在该点的梯度垂直,如果要有非零解的话推出f在该点的梯度是h1,h2梯度的线性组合,所以有
∇
f
(
x
)
=
λ
∑
i
=
1
2
μ
i
∇
h
i
(
x
)
=
∑
i
=
1
2
λ
i
∇
h
i
(
x
)
\nabla f(x)=\lambda \sum_{i=1}^{2} \mu_{i} \nabla h_{i}(x)=\sum_{i=1}^{2} \lambda_{i} \nabla h_{i}(x)
∇f(x)=λ∑i=12μi∇hi(x)=∑i=12λi∇hi(x)
h
1
(
x
)
=
0
h_{1}(x)=0
h1(x)=0
h
2
(
x
)
=
0
h_{2}(x)=0
h2(x)=0
如果有不等式约束怎么办,对于
min
f
(
x
)
s.t.
h
(
x
)
=
0
g
(
x
)
≤
0
\min f(x) \begin{array}{ll} \text { s.t. } & h(x)=0 \\ & g(x) \leq 0 \end{array}
minf(x) s.t. h(x)=0g(x)≤0
可以画出两张图

前者对应极值点本身在可行域内的情况,后者和之前的情况相同,即极值点在可行域边界上。
对于第一种情况,不等式约束g不起作用,有
∇
f
(
x
)
+
λ
∇
h
(
x
)
=
0
\nabla f(x)+\lambda \nabla h(x)=0
∇f(x)+λ∇h(x)=0
h
(
x
)
=
0
h(x)=0
h(x)=0
g
(
x
)
≤
0
g(x) \leq 0
g(x)≤0
对于第二种情况有
∇
f
(
x
)
+
λ
∇
h
(
x
)
+
μ
∇
g
(
x
)
=
0
\nabla f(x)+\lambda \nabla h(x)+\mu \nabla g(x)=0
∇f(x)+λ∇h(x)+μ∇g(x)=0
h
(
x
)
=
0
h(x)=0
h(x)=0
g
(
x
)
=
0
g(x)=0
g(x)=0
μ
≥
0
\mu \geq 0
μ≥0
这里
μ
≥
0
\mu \geq 0
μ≥0是因为g(x)的梯度指向可行域之外,而f(x)指向可行域内,所以两者应该方向相反。
可以验证两种情况下都满足
μ
g
(
x
)
=
0
\mu g(x)=0
μg(x)=0,所以合在一起写成
∇
f
(
x
)
+
λ
∇
h
(
x
)
+
μ
∇
g
(
x
)
=
0
\nabla f(x)+\lambda \nabla h(x)+\mu \nabla g(x)=0
∇f(x)+λ∇h(x)+μ∇g(x)=0
μ
g
(
x
)
=
0
\mu g(x)=0
μg(x)=0
μ
≥
0
\mu \geq 0
μ≥0
h
(
x
)
=
0
h(x)=0
h(x)=0
g
(
x
)
≤
0
g(x) \leq 0
g(x)≤0
这就是所谓KKT条件。
但是并不是所有优化问题的极值点都满足KKT条件,有以下几个规范性条件
LCQ:如果 h(x) 和 g(x) 都是形如 Ax+b 的仿射函数,那么极值一定满足 KKT 条件。
LICQ:起作用的 g(x) 函数(即 g(x) 相当于等式约束的情况)和 h(x) 函数在极值点处的梯度要线性无关,那么极值一定满足 KKT 条件。
Slater条件:如果优化问题是个凸优化问题,且至少存在一个点满足 h(x)=0 和 g(x)<0,极值一定满足 KKT条件。并且满足强对偶性质。
所谓凸优化问题是指目标函数f,不等式约束条件g都是凸函数,而等式约束h是仿射函数(AX+b)
定义广义拉格朗日函数generalized Lagrangian
L
(
w
,
α
,
β
)
=
f
(
w
)
+
∑
i
=
1
k
α
i
g
i
(
w
)
+
∑
i
=
1
l
β
i
h
i
(
w
)
\mathcal{L}(w, \alpha, \beta)=f(w)+\sum_{i=1}^{k} \alpha_{i} g_{i}(w)+\sum_{i=1}^{l} \beta_{i} h_{i}(w)
L(w,α,β)=f(w)+∑i=1kαigi(w)+∑i=1lβihi(w)
待不等约束的优化问题等价于原始问题:
min
w
max
α
,
β
:
α
i
≥
0
L
(
w
,
α
,
β
)
\min _{w} \max _{\alpha, \beta: \alpha_{i} \geq 0} \mathcal{L}(w, \alpha, \beta)
minwmaxα,β:αi≥0L(w,α,β)
α
i
≥
0
\alpha_{i} \geq 0
αi≥0限制了
g
i
(
w
)
g_{i}(w)
gi(w)必须小于0,不然的话
L
\mathcal{L}
L可以取无穷大,那么
w
{w}
w处也取不到最小值。
原始(primal)问题和对偶(dual)问题
 假设每个x轴和每个y轴方向上都能找到无穷大或者无穷小,那么原始问题只能找到无穷大,而对偶问题只能找到无穷小。
假设每个x轴和每个y轴方向上都能找到无穷大或者无穷小,那么原始问题只能找到无穷大,而对偶问题只能找到无穷小。
利用对偶问题求解SVM

在测试时
w
T
x
+
b
=
(
∑
i
=
1
m
α
i
y
(
i
)
x
(
i
)
)
T
x
+
b
=
∑
i
=
1
m
α
i
y
(
i
)
⟨
x
(
i
)
,
x
⟩
+
b
\begin{aligned} w^{T} x+b &=\left(\sum_{i=1}^{m} \alpha_{i} y^{(i)} x^{(i)}\right)^{T} x+b \\ &=\sum_{i=1}^{m} \alpha_{i} y^{(i)}\left\langle x^{(i)}, x\right\rangle+b \end{aligned}
wTx+b=(i=1∑mαiy(i)x(i))Tx+b=i=1∑mαiy(i)⟨x(i),x⟩+b
可以看出测试时只需要知道样本对应的
α
i
\alpha_i
αi以及和待测点的内积,并且只有支持向量对应的
α
i
\alpha_i
αi才不为0,因为
α
i
g
i
(
w
)
≥
0
\alpha_{i} g_{i}(w) \geq0
αigi(w)≥0。理解:和正例支持向量的内积之和越大,越可能是正例。
可以对input atrributes 做一个feature mapping, 比如x本身是一个三维向量,可以定义
ϕ
(
x
)
=
[
x
1
x
1
x
1
x
2
x
1
x
3
x
2
x
1
x
2
x
2
x
2
x
3
x
3
x
1
x
3
x
2
x
3
x
3
2
c
x
1
2
c
x
2
2
c
x
3
c
]
\phi(x)=\left[\begin{array}{c}x_{1} x_{1} \\ x_{1} x_{2} \\ x_{1} x_{3} \\ x_{2} x_{1} \\ x_{2} x_{2} \\ x_{2} x_{3} \\ x_{3} x_{1} \\ x_{3} x_{2} \\ x_{3} x_{3} \\ \sqrt{2 c} x_{1} \\ \sqrt{2 c} x_{2} \\ \sqrt{2 c} x_{3} \\ c\end{array}\right]
ϕ(x)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡x1x1x1x2x1x3x2x1x2x2x2x3x3x1x3x2x3x32cx12cx22cx3c⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
然后把kernel 定义成两个feature的内积
K
(
x
,
z
)
=
ϕ
(
x
)
T
ϕ
(
z
)
K(x, z)=\phi(x)^{T} \phi(z)
K(x,z)=ϕ(x)Tϕ(z)
直接计算feature复杂度会达到O(n^2),所以这里先计算input的内积,然后再进行转换
K
(
x
,
z
)
=
(
x
T
z
+
c
)
2
=
∑
i
,
j
=
1
n
(
x
i
x
j
)
(
z
i
z
j
)
+
∑
i
=
1
n
(
2
c
x
i
)
(
2
c
z
i
)
+
c
2
\begin{aligned} K(x, z) &=\left(x^{T} z+c\right)^{2} \\ &=\sum_{i, j=1}^{n}\left(x_{i} x_{j}\right)\left(z_{i} z_{j}\right)+\sum_{i=1}^{n}\left(\sqrt{2 c} x_{i}\right)\left(\sqrt{2 c} z_{i}\right)+c^{2} \end{aligned}
K(x,z)=(xTz+c)2=i,j=1∑n(xixj)(zizj)+i=1∑n(2cxi)(2czi)+c2
从而把时间复杂度缩减到O(n)
如果先不考虑future mapping,而是首先定义kernel的形式呢?比如,因为kernel考虑是两个样本的相似性,所以可以定义
K
(
x
,
z
)
=
exp
(
−
∥
x
−
z
∥
2
2
σ
2
)
K(x, z)=\exp \left(-\frac{\|x-z\|^{2}}{2 \sigma^{2}}\right)
K(x,z)=exp(−2σ2∥x−z∥2), 然后再去验证kernel是否可以写成两个feature内积的形式。
这里有一个Mercer定理,如果kernel对应的矩阵是一个半正定矩阵那么它一定能表示成内积形式(对于m个样本来说)。
对于文本分类任务,如果先定义feature mapping为每个长度为4的子串出现的频率,那么feature 的维度会非常大,而如果我们直接定义kernel,只需要用动态规划计算匹配的字符串数量就行了。
有些情况下数据是线性不可分的,必须对svm进行一个松弛,即yg(x)并不要求严格大于等于1, 得到一个新的优化问题
min
γ
,
w
,
b
1
2
∥
w
∥
2
+
C
∑
i
=
1
m
ξ
i
s.t.
y
(
i
)
(
w
T
x
(
i
)
+
b
)
≥
1
−
ξ
i
,
i
=
1
,
…
,
m
ξ
i
≥
0
,
i
=
1
,
…
,
m
.
\begin{aligned} \min _{\gamma, w, b} & \frac{1}{2}\|w\|^{2}+C \sum_{i=1}^{m} \xi_{i} \\ \text { s.t. } & y^{(i)}\left(w^{T} x^{(i)}+b\right) \geq 1-\xi_{i}, \quad i=1, \ldots, m \\ & \xi_{i} \geq 0, \quad i=1, \ldots, m . \end{aligned}
γ,w,bmin s.t. 21∥w∥2+Ci=1∑mξiy(i)(wTx(i)+b)≥1−ξi,i=1,…,mξi≥0,i=1,…,m.
可以证明它最终只是给a加了一个上界C,即
s.t.
0
≤
α
i
≤
C
,
i
=
1
,
…
,
m
0 \leq \alpha_{i} \leq C, \quad i=1, \ldots, m
0≤αi≤C,i=1,…,m,并且改变了KKT条件。
对偶函数
L
(
w
,
b
,
ξ
,
α
,
r
)
=
1
2
w
T
w
+
C
∑
i
=
1
m
ξ
i
−
∑
i
=
1
m
α
i
[
y
(
i
)
(
x
T
w
+
b
)
−
1
+
ξ
i
]
−
∑
i
=
1
m
r
i
ξ
i
\mathcal{L}(w, b, \xi, \alpha, r)=\frac{1}{2} w^{T} w+C \sum_{i=1}^{m} \xi_{i}-\sum_{i=1}^{m} \alpha_{i}\left[y^{(i)}\left(x^{T} w+b\right)-1+\xi_{i}\right]-\sum_{i=1}^{m} r_{i} \xi_{i}
L(w,b,ξ,α,r)=21wTw+C∑i=1mξi−∑i=1mαi[y(i)(xTw+b)−1+ξi]−∑i=1mriξi

剩下的就是如果优化
α
\alpha
α,SMO算法的思路每次从
α
1
,
α
2
,
…
,
α
m
\alpha_{1}, \alpha_{2}, \ldots, \alpha_{m}
α1,α2,…,αm 中选取两个进行优化,直到所有
α
\alpha
α满足KKT条件。选取两个是因为如果只选一个无法满足
∑
i
=
1
m
α
i
y
(
i
)
=
0
\sum_{i=1}^{m} \alpha_{i} y^{(i)}=0
∑i=1mαiy(i)=0

从图中可以看出,点
(
α
1
,
α
2
)
\left(\alpha_{1}, \alpha_{2}\right)
(α1,α2)在一个线段上移动,假设自变量为
α
2
\alpha_{2}
α2,它由上界H和下界L,在求出
α
2
n
e
w
\alpha_{2}^{new}
α2new后需要进行clip



每一轮迭代之后都需要更新E.
learning theory
如果把training set看成一个变量,而学习过程(model)看成是一个deterministic functon,那么通过学习得到的hypothesis也是一个变量。
generalization error 是 hypothesis 的在所有样本上的expected error,即
ε
(
h
)
=
P
(
x
,
y
)
∼
D
(
h
(
x
)
≠
y
)
\varepsilon(h)=P_{(x, y) \sim \mathcal{D}}(h(x) \neq y)
ε(h)=P(x,y)∼D(h(x)=y)
一个模型的bias是当数据集很大或无限大时,生成的hypothesis的generalization error。
variance是指模型根据不同的训练集产生的hypothesis的generalization error方差。
也就是说如果模型过于简单,不能拟合训练数据,那么就会产生较大的bias。如果模型太复杂,那么就会过拟合,进而产生较大的variance。
学习理论用到了两个定理
几个事件交集的概率小于各自概率之和
P
(
A
1
∪
⋯
∪
A
k
)
≤
P
(
A
1
)
+
…
+
P
(
A
k
)
P\left(A_{1} \cup \cdots \cup A_{k}\right) \leq P\left(A_{1}\right)+\ldots+P\left(A_{k}\right)
P(A1∪⋯∪Ak)≤P(A1)+…+P(Ak)
以及Hoeffding inequality
它说的是m个独立同分布的伯努利Bernoulli
(
ϕ
)
(\phi)
(ϕ)变量,用这些变量的均值
ϕ
^
\hat{\phi}
ϕ^作为
ϕ
\phi
ϕ的估计值,那么
估计值和真实值之间的误差大于
γ
\gamma
γ的概率在m很大时应该会很小,即
P
(
∣
ϕ
−
ϕ
^
∣
>
γ
)
≤
2
exp
(
−
2
γ
2
m
)
P(|\phi-\hat{\phi}|>\gamma) \leq 2 \exp \left(-2 \gamma^{2} m\right)
P(∣ϕ−ϕ^∣>γ)≤2exp(−2γ2m)
对于二分类下某个hypothesis来说,它在任意一个样本上出错的概率就等于它的泛化误差,所以根据Hoeffding inequality我们可以用经验误差来估计泛化误差
ε
^
(
h
)
=
1
m
∑
i
=
1
m
1
{
h
(
x
(
i
)
)
≠
y
(
i
)
}
\hat{\varepsilon}(h)=\frac{1}{m} \sum_{i=1}^{m} 1\left\{h\left(x^{(i)}\right) \neq y^{(i)}\right\}
ε^(h)=m1∑i=1m1{h(x(i))=y(i)}
我们把学习算法看成是一个在hypothesis 集合
H
\mathcal{H}
H中找到一个能最小化经验误差的hypothesis的过程。
h
^
=
arg
min
h
∈
H
ε
^
(
h
)
\hat{h}=\arg \min _{h \in \mathcal{H}} \hat{\varepsilon}(h)
h^=argminh∈Hε^(h)
根据Hoeffding inequality,已知
h
i
h_i
hi的经验误差,我们能获得它的泛化误差上下界。
P
(
∣
ε
(
h
i
)
−
ε
^
(
h
i
)
∣
>
γ
)
≤
2
exp
(
−
2
γ
2
m
)
P\left(\left|\varepsilon\left(h_{i}\right)-\hat{\varepsilon}\left(h_{i}\right)\right|>\gamma\right) \leq 2 \exp \left(-2 \gamma^{2} m\right)
P(∣ε(hi)−ε^(hi)∣>γ)≤2exp(−2γ2m)
但是如果我们想获得集合中所有hypothesis同事满足的上下界呢,这里用到了第一个过于并集的公式
P
(
∃
h
∈
H
.
∣
ε
(
h
i
)
−
ε
^
(
h
i
)
∣
>
γ
)
=
P
(
A
1
∪
⋯
∪
A
k
)
≤
∑
i
=
1
k
P
(
A
i
)
≤
∑
i
=
1
k
2
exp
(
−
2
γ
2
m
)
=
2
k
exp
(
−
2
γ
2
m
)
\begin{aligned} P\left(\exists h \in \mathcal{H} .\left|\varepsilon\left(h_{i}\right)-\hat{\varepsilon}\left(h_{i}\right)\right|>\gamma\right) &=P\left(A_{1} \cup \cdots \cup A_{k}\right) \\ & \leq \sum_{i=1}^{k} P\left(A_{i}\right) \\ & \leq \sum_{i=1}^{k} 2 \exp \left(-2 \gamma^{2} m\right) \\ &=2 k \exp \left(-2 \gamma^{2} m\right) \end{aligned}
P(∃h∈H.∣ε(hi)−ε^(hi)∣>γ)=P(A1∪⋯∪Ak)≤i=1∑kP(Ai)≤i=1∑k2exp(−2γ2m)=2kexp(−2γ2m)
然后用1减去不等式两边,得到
P
(
¬
∃
h
∈
H
.
∣
ε
(
h
i
)
−
ε
^
(
h
i
)
∣
>
γ
)
=
P
(
∀
h
∈
H
.
∣
ε
(
h
i
)
−
ε
^
(
h
i
)
∣
≤
γ
)
≥
1
−
2
k
exp
(
−
2
γ
2
m
)
\begin{aligned} P\left(\neg \exists h \in \mathcal{H} .\left|\varepsilon\left(h_{i}\right)-\hat{\varepsilon}\left(h_{i}\right)\right|>\gamma\right) &=P\left(\forall h \in \mathcal{H} .\left|\varepsilon\left(h_{i}\right)-\hat{\varepsilon}\left(h_{i}\right)\right| \leq \gamma\right) \\ & \geq 1-2 k \exp \left(-2 \gamma^{2} m\right) \end{aligned}
P(¬∃h∈H.∣ε(hi)−ε^(hi)∣>γ)=P(∀h∈H.∣ε(hi)−ε^(hi)∣≤γ)≥1−2kexp(−2γ2m)
进一步我们可以获得满足最小经验误差的hypothesis
h
^
\hat{h}
h^ 它的泛化误差应该满足
ε
(
h
^
)
≤
ε
^
(
h
^
)
+
γ
≤
ε
^
(
h
∗
)
+
γ
≤
ε
(
h
∗
)
+
2
γ
\begin{aligned} \varepsilon(\hat{h}) & \leq \hat{\varepsilon}(\hat{h})+\gamma \\ & \leq \hat{\varepsilon}\left(h^{*}\right)+\gamma \\ & \leq \varepsilon\left(h^{*}\right)+2 \gamma \end{aligned}
ε(h^)≤ε^(h^)+γ≤ε^(h∗)+γ≤ε(h∗)+2γ
其中
h
∗
h^{*}
h∗是最小化泛化误差的hypothesis,即最优hypothesis。
有了上面的公式,我们可以问一个问题,在保证概率至少为
1
−
δ
1-\delta
1−δ的情况下,至少需要多少个训练样本,才能保证训练误差在泛化误差的
γ
\gamma
γ领域内。
答案是
m
≥
1
2
γ
2
log
2
k
δ
m \geq \frac{1}{2 \gamma^{2}} \log \frac{2 k}{\delta}
m≥2γ21logδ2k
其中k是集合中hypothesis的数量,可以看出m和k应该是线性关系。
以64位浮点数为例,假设模型参数中有d个浮点数
则
m
≥
O
(
1
γ
2
log
2
6dd
δ
)
=
O
(
d
γ
2
log
1
δ
)
=
O
γ
,
δ
(
d
)
m \geq O\left(\frac{1}{\gamma^{2}} \log \frac{2^{\text {6dd}}}{\delta}\right)=O\left(\frac{d}{\gamma^{2}} \log \frac{1}{\delta}\right)=O_{\gamma, \delta}(d)
m≥O(γ21logδ26dd)=O(γ2dlogδ1)=Oγ,δ(d)
但是如果参数是实数,或者参数数量并不能反映集合大小,比如两组不同参数对应的hypothesis相同的情况。
令
S
=
{
x
(
i
)
,
…
,
x
(
d
)
}
S=\left\{x^{(i)}, \ldots, x^{(d)}\right\}
S={x(i),…,x(d)}是一个包含d个点的集合,
H
\mathcal{H}
H shatters
S
S
S 是指无论这d个点的标签分别是什么,
H
\mathcal{H}
H 中都能找到一个hypothesis能正确分类。
H
\mathcal{H}
H 所能找到的最大的d就是它的VC维。
比如线性分类器的VC维是3

注意只要找到一个S就行,没必要满足所有的S,比如下面这个大小为3的S,线性分类器就不能shatter。
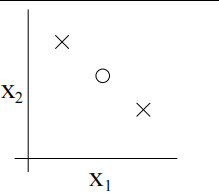
对于VC维d,有
ε
(
h
^
)
≤
ε
(
h
∗
)
+
O
(
d
m
log
m
d
+
1
m
log
1
δ
)
\varepsilon(\hat{h}) \leq \varepsilon\left(h^{*}\right)+O\left(\sqrt{\frac{d}{m} \log \frac{m}{d}+\frac{1}{m} \log \frac{1}{\delta}}\right)
ε(h^)≤ε(h∗)+O(mdlogdm+m1logδ1)
如何减少variance? 一个方法是对模型参数 θ \theta θ加上一些约束,比如l1,l2正则项。
在贝叶斯学派的人眼中, 模型参数
θ
\theta
θ也是一个随机变量,所以也有一个先验分布。
给定数据集S,模型参数的后验分布可以写成
p
(
θ
∣
S
)
=
p
(
S
∣
θ
)
p
(
θ
)
p
(
S
)
=
(
∏
i
=
1
m
p
(
y
(
i
)
∣
x
(
i
)
,
θ
)
)
p
(
θ
)
∫
θ
(
∏
i
=
1
m
p
(
y
(
i
)
∣
x
(
i
)
,
θ
)
p
(
θ
)
)
d
θ
\begin{aligned} p(\theta \mid S) &=\frac{p(S \mid \theta) p(\theta)}{p(S)} \\ &=\frac{\left(\prod_{i=1}^{m} p\left(y^{(i)} \mid x^{(i)}, \theta\right)\right) p(\theta)}{\int_{\theta}\left(\prod_{i=1}^{m} p\left(y^{(i)} \mid x^{(i)}, \theta\right) p(\theta)\right) d \theta} \end{aligned}
p(θ∣S)=p(S)p(S∣θ)p(θ)=∫θ(∏i=1mp(y(i)∣x(i),θ)p(θ))dθ(∏i=1mp(y(i)∣x(i),θ))p(θ)
给定一个新的样本x, 它的概率应该写成
p
(
y
∣
x
,
S
)
=
∫
θ
p
(
y
∣
x
,
θ
)
p
(
θ
∣
S
)
d
θ
p(y \mid x, S)=\int_{\theta} p(y \mid x, \theta) p(\theta \mid S) d \theta
p(y∣x,S)=∫θp(y∣x,θ)p(θ∣S)dθ ,因为
θ
\theta
θ是一个随机变量,所以这里必须写成积分形式。
但实际上对高维向量积分是非常困难的,所以一般用概率最大的一个点来代替整个
θ
\theta
θ的分布,这种做法叫做maximum a posteriori MAP
θ
M
A
P
=
arg
max
θ
∏
i
=
1
m
p
(
y
(
i
)
∣
x
(
i
)
,
θ
)
p
(
θ
)
\theta_{\mathrm{MAP}}=\arg \max _{\theta} \prod_{i=1}^{m} p\left(y^{(i)} \mid x^{(i)}, \theta\right) p(\theta)
θMAP=argmaxθ∏i=1mp(y(i)∣x(i),θ)p(θ)
这里的形式和MLE很像,只是多了一项先验分布
p
(
θ
)
p(\theta)
p(θ),可以证明它的作用和频率学派中的正则项一样。
在数据集ds1_b.csv上发现,以梯度的二范数作为判断是否收敛的指标,当阈值设置为1e-4时,logisticregression不能收敛。
阈值放宽到1e-3时,得到的超平面为

同样的条件下在数据集a上就可以收敛。

造成这种现象的原因是代码中使用的logistic 回归使用的是y=-1和y=1两种标签,并且概率函数的写法也不一样。

经过试验发现,添加l2约束和加入随机噪声都能使模型在数据集B上收敛,后者的原因是使原本的线性可分变成不可分。
在线性可分的情况下,第一种形式的functional margin可以无限增大。
而hinge loss 则限制了functional margin 最大为1.
J
(
y
^
)
=
max
(
0
,
1
−
y
⋅
y
^
)
J(\hat{y})=\max (0,1-y \cdot \hat{y})
J(y^)=max(0,1−y⋅y^)
well-calibrated 是指按照训练好的模型预测的正例概率划分一个范围[a,b],该范围内所有样本的正例概率之和等于正例个数。即
∑
i
∈
I
a
,
b
P
(
y
(
i
)
=
1
∣
x
(
i
)
;
θ
)
∣
{
i
∈
I
a
,
b
}
∣
=
∑
i
∈
I
a
,
b
I
{
y
(
i
)
=
1
}
∣
{
i
∈
I
a
,
b
}
∣
\frac{\sum_{i \in I_{a, b}} P\left(y^{(i)}=1 \mid x^{(i)} ; \theta\right)}{\left|\left\{i \in I_{a, b}\right\}\right|}=\frac{\sum_{i \in I_{a, b}} \mathbb{I}\left\{y^{(i)}=1\right\}}{\left|\left\{i \in I_{a, b}\right\}\right|}
∣{i∈Ia,b}∣∑i∈Ia,bP(y(i)=1∣x(i);θ)=∣{i∈Ia,b}∣∑i∈Ia,bI{y(i)=1}
首先证明在范围[0,1]内logistic回归是well-calibrated的

首先证明
θ
M
A
P
=
arg
max
θ
p
(
θ
∣
x
,
y
)
\theta_{\mathrm{MAP}}=\arg \max _{\theta} p(\theta \mid x, y)
θMAP=argmaxθp(θ∣x,y) 可以写成
θ
M
A
P
=
argmax
θ
p
(
y
∣
x
,
θ
)
p
(
θ
)
\theta_{\mathrm{MAP}}=\operatorname{argmax}_{\theta} p(y \mid x, \theta) p(\theta)
θMAP=argmaxθp(y∣x,θ)p(θ), 然后证明
θ
\theta
θ满足高斯分布的时候,后者在MLE的形式下等价于L2优化,并且对线性回归模型来说可以求得封闭解

如果
θ
\theta
θ满足拉普拉斯分布,其在MLE下等价于L1约束,但是不能求出封闭解。

证明某个kernel的正多项式,也是一个valid kernel

把感知机kernelize
θ
(
i
+
1
)
:
=
θ
(
i
)
+
α
(
y
(
i
+
1
)
−
h
θ
(
i
)
(
x
(
i
+
1
)
)
)
x
(
i
+
1
)
\theta^{(i+1)}:=\theta^{(i)}+\alpha\left(y^{(i+1)}-h_{\theta(i)}\left(x^{(i+1)}\right)\right) x^{(i+1)}
θ(i+1):=θ(i)+α(y(i+1)−hθ(i)(x(i+1)))x(i+1)
做法是把
θ
\theta
θ看成是
ϕ
(
x
i
)
\phi(x^i)
ϕ(xi)的加权和,但是
ϕ
(
x
i
)
\phi(x^i)
ϕ(xi)不用具体计算出结果,只是在新样本过来的时候用来计算kernel。
一共用了两种kernel, 一种是rbf:
distance = (a - b).dot(a - b)
scaled_distance = -distance / (2 * (sigma) ** 2)
return math.exp(scaled_distance)

一种是点乘dot

PS3
决策树
用熵
H
(
p
)
=
−
p
l
o
g
2
p
H(p)=-plog_2p
H(p)=−plog2p来衡量概率p的不确定性
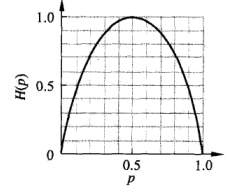
可以看出p=0.5的时候不确定性最大。
信息增益
g
(
D
,
A
)
=
H
(
D
)
−
H
(
D
∣
A
)
g(D, A)=H(D)-H(D \mid A)
g(D,A)=H(D)−H(D∣A)是指某个节点按照特征A的取值进行划分之后,不确定性的减小量。
其中
H
(
D
∣
A
)
=
∑
i
=
1
n
∣
D
i
∣
∣
D
∣
H
(
D
i
)
=
−
∑
i
=
1
n
∣
D
i
∣
∣
D
∣
∑
k
=
1
K
∣
D
i
k
∣
∣
D
i
∣
log
2
∣
D
i
k
∣
∣
D
i
∣
H(D \mid A)=\sum_{i=1}^{n} \frac{\left|D_{i}\right|}{|D|} H\left(D_{i}\right)=-\sum_{i=1}^{n} \frac{\left|D_{i}\right|}{|D|} \sum_{k=1}^{K} \frac{\left|D_{i k}\right|}{\left|D_{i}\right|} \log _{2} \frac{\left|D_{i k}\right|}{\left|D_{i}\right|}
H(D∣A)=∑i=1n∣D∣∣Di∣H(Di)=−∑i=1n∣D∣∣Di∣∑k=1K∣Di∣∣Dik∣log2∣Di∣∣Dik∣
ID3 算法递归地分割节点,直到该节点没有特征可以选择,或者其中所有实例属于同一类。对于第一种停止情况,把该节点中最大的类作为该节点的类标记。
剪枝算法从子节点往上缩,用一个作用于全体叶子节点损失函数来衡量是否合并父节点的所有子节点。
ID3 决策树的缺点是不能处理连续特征,以及不能进行回归任务。CART 决策树改进上述两点,在分类任务中,用基尼系数 G i n i ( p ) = ∑ k = 1 K p k ( 1 − p k ) = 1 − ∑ k = 1 K p k 2 G i n i(p)=\sum_{k=1}^{K} p_{k}\left(1-p_{k}\right)=1-\sum_{k=1}^{K} p_{k}^{2} Gini(p)=∑k=1Kpk(1−pk)=1−∑k=1Kpk2替代了信息熵并且使用了二叉树,更利于计算。
对于连续特征,假设训练集中一共有m个取值,以相邻取值的中点为划分点,需要考虑m-1种划分。如果是离散特征,并且该特征有m个取值,就考虑m种划分。
如果是回归任务,度量函数变成划分后两个区域的y值的方差之和,在预测时,取叶子节点的均值作为输出。
决策树的一个缺点是variance很高, 而bagging的思路是将多个correlation较低的weak leaner结合起来,它的理论依据是多个同分布,且相关性较小的随机变量的平均值方差比单个变量的方差更小:
var
(
1
n
∑
i
=
1
n
X
i
)
=
1
n
var
(
X
i
)
+
1
n
2
∑
i
≠
j
cov
(
X
i
,
X
j
)
\operatorname{var}\left({1\over n}\sum_{i=1}^{n} X_{i}\right)={1\over n}\operatorname{var}\left(X_{i}\right)+{1\over n^2}\sum_{i\not=j} \operatorname{cov}\left(X_{i}, X_{j}\right)
var(n1∑i=1nXi)=n1var(Xi)+n21∑i=jcov(Xi,Xj)
可以看出小于号取决于协方差cov.
而随机森林是指对数据集和特征进行分割然后分开单独训练,从而减小相关性。
boosting采用了另外一种增加bias的思路,每个weak leaner之间有高相关性,即前面步骤得到的分类器在每个样本上的误差会决定下一个步骤中的新分类器在每个样本上的权重。

ML debug
假设现在有一个logistic 回归模型, 他在垃圾邮件分类的测试集上有20的误差率, 如何提升模型性能。每个人可能会选择很多不同的方法,比如增加训练数据, 尝试更多或更少的特征,引入额外的特征比如邮件的header。 或者增加迭代轮次,改变学习率,尝试不同的优化方法,如果实在不行就用新的模型。
假设你怀疑问题要么是过拟合也就是高variance, 要么是特征不够。
那么可以根据模型分别在训练集和测试集上的数据来判断
对于high variance的情况,通常上训练集上的误差会明显小于测试集

随着数据的增加,两者之间的差距会缩小。
而对于high bias 的情况,即使在训练集上模型的错误率都比较高,并且随着数据的增加,测试集上的误差率也不会下降到理想水平

增大训练集,减少特征用于解决high variance , 更多特征或添加新特征用于解决high bias。
如果想判断logistic的损失函数到底有没有收敛,可以找另外一个性能更好的模型比如SVM, 它在评价指标
a
(
θ
)
=
max
θ
∑
w
(
i
)
1
{
h
θ
(
x
(
i
)
)
=
y
(
i
)
}
a(\theta)=\max _{\theta} \sum w^{(i)} 1\left\{h_{\theta}\left(x^{(i)}\right)=y^{(i)}\right\}
a(θ)=maxθ∑w(i)1{hθ(x(i))=y(i)}上优于logistic 回归。
然后用SVM的模型来计算logistic回归的目标函数(越大越好)
J
(
θ
)
=
∑
i
=
1
m
log
p
(
y
(
i
)
∣
x
(
i
)
,
θ
)
−
λ
∥
θ
∥
2
J(\theta)=\sum_{i=1}^{m} \log p\left(y^{(i)} \mid x^{(i)}, \theta\right)-\lambda\|\theta\|^{2}
J(θ)=∑i=1mlogp(y(i)∣x(i),θ)−λ∥θ∥2
如果
a
(
θ
SVM
)
>
a
(
θ
B
L
R
)
J
(
θ
S
V
M
)
>
J
(
θ
B
L
R
)
\begin{aligned} a\left(\theta_{\text {SVM }}\right) &>a\left(\theta_{\mathrm{BLR}}\right) \\ J\left(\theta_{\mathrm{SVM}}\right) &>J\left(\theta_{\mathrm{BLR}}\right) \end{aligned}
a(θSVM )J(θSVM)>a(θBLR)>J(θBLR)
说明logistic 在目标函数上不能收敛,优化算法有问题。
如果
a
(
θ
S
V
M
)
>
a
(
θ
B
L
R
)
J
(
θ
S
V
M
)
≤
J
(
θ
B
L
R
)
\begin{aligned} a\left(\theta_{\mathrm{SVM}}\right) &>a\left(\theta_{\mathrm{BLR}}\right) \\ J\left(\theta_{\mathrm{SVM}}\right) & \leq J\left(\theta_{\mathrm{BLR}}\right) \end{aligned}
a(θSVM)J(θSVM)>a(θBLR)≤J(θBLR)
说明即便logisitic回归在目标函数上表现比svm好,但实际效果仍然不如SVM, 目标函数本身有问题。
一个直升机控制算法主要分成三个部分,模拟器,代价方程,以及强化学习算法。
如果直升机在模拟器中表现良好,但是在现实环境中表现不好,说明问题出在模拟器。
如果人类操作的代价函数小于强化学习的代价函数,说明问题在算法模型。
如果强化学习的代价函数更小,说明问题在代价函数本身。
- EM


根据多元高斯分布的边缘分布性质,可以证明当X左乘一个行向量b后,得到的标量的方差为 b Σ b ′ \boldsymbol{b} \Sigma b^{\prime} bΣb′。 如果该方差为0, 说明bX为常量,X中某一个维度可以被其它维度线性表示。反过来,如果协方差矩阵的行列式为singular矩阵,则存在b, 令bX为常数。 在是、实践中,如果变量的维度n大于样本数m,则很可能发生计算出的协方差矩阵为奇异的情况。在这种情况下,可以直接去除重复的维度。 比如可以令 X = k Y + d \boldsymbol{X}=\boldsymbol{k} \boldsymbol{Y}+\boldsymbol{d} X=kY+d 其中X的维度为3, Y Y Y的维度为2,并且均值为0,方差是2x2单位矩阵,k的维度为3x2。 易证 Σ X = k k ′ \boldsymbol{\Sigma}_{\boldsymbol{X}}=\boldsymbol{k} \boldsymbol{k}^{\prime} ΣX=kk′。 k的计算方法是把 Σ \boldsymbol{\Sigma} Σ分解成下三角和上三角乘积,然后去除其中为0的行和列
( 2 0 0 1 0 0 − 1 0 3 ) ( 2 1 − 1 0 0 0 0 0 3 ) = ( 2 0 1 0 − 1 3 ) ( 2 1 − 1 0 0 3 ) \left(\begin{array}{rrr}2 & 0 & 0 \\ 1 & 0 & 0 \\ -1 & 0 & 3\end{array}\right)\left(\begin{array}{rrr}2 & 1 & -1 \\ 0 & 0 & 0 \\ 0 & 0 & 3\end{array}\right)=\left(\begin{array}{rr}2 & 0 \\ 1 & 0 \\ -1 & 3\end{array}\right)\left(\begin{array}{llr}2 & 1 & -1 \\ 0 & 0 & 3\end{array}\right) ⎝⎛21−1000003⎠⎞⎝⎛200100−103⎠⎞=⎝⎛21−1003⎠⎞(2010−13)
k和d可以成是一个仿射,把二维点映射到三维


在M步得到的
Λ
=
(
∑
i
=
1
m
(
x
(
i
)
−
μ
)
E
z
(
i
)
∼
Q
i
[
z
(
i
)
T
]
)
(
∑
i
=
1
m
E
z
(
i
)
∼
Q
i
[
z
(
i
)
z
(
i
)
T
]
)
−
1
\Lambda=\left(\sum_{i=1}^{m}\left(x^{(i)}-\mu\right) \mathrm{E}_{z^{(i)} \sim Q_{i}}\left[z^{(i)^{T}}\right]\right)\left(\sum_{i=1}^{m} \mathrm{E}_{z^{(i)} \sim Q_{i}}\left[z^{(i)} z^{(i)^{T}}\right]\right)^{-1}
Λ=(∑i=1m(x(i)−μ)Ez(i)∼Qi[z(i)T])(∑i=1mEz(i)∼Qi[z(i)z(i)T])−1 和最小二乘法中的形式
θ
T
=
(
y
T
X
)
(
X
T
X
)
−
1
.
\theta^{T}=\left(y^{T} X\right)\left(X^{T} X\right)^{-1} .
θT=(yTX)(XTX)−1.很像,原因是
Λ
\Lambda
Λ也是
x
−
μ
x-\mu
x−μ和
z
z
z之间的线性系数。















 971
971











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









